静态分区裁剪(Static Partition Pruning)用过 Spark 的同学都知道,Spark SQL 在查询的时候支持分区裁剪,比如我们如果有以下的查询:[code lang="sql"]SELECT * FROM Sales_iteblog WHERE day_of_week = 'Mon'[/code]Spark 会自动进行以下的优化:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop从上图可以看到,S w397090770 5年前 (2019-11-04) 2716℃ 0评论6喜欢
为期三天的 SPARK + AI SUMMIT Europe 2019 于 2019年10月15日-17日荷兰首都阿姆斯特丹举行。数据和 AI 是需要结合的,而 Spark 能够处理海量数据的分析,将 Spark 和 AI 进行结合,无疑会带来更好的产品。Spark+AI Summit Europe 2019 是欧洲最大的数据和机器学习会议,大约有1700多名数据科学家、工程师和分析师参加此次会议。本次会议的提议包括了A w397090770 5年前 (2019-11-01) 1055℃ 0评论1喜欢
为期三天的 SPARK + AI SUMMIT Europe 2019 于 2019年10月15日-17日荷兰首都阿姆斯特丹举行。数据和 AI 是需要结合的,而 Spark 能够处理海量数据的分析,将 Spark 和 AI 进行结合,无疑会带来更好的产品。Spark+AI Summit Europe 2019 是欧洲最大的数据和机器学习会议,大约有1700多名数据科学家、工程师和分析师参加此次会议。本次会议的提议包括了A w397090770 5年前 (2019-11-01) 1538℃ 1评论0喜欢
2019年10月22日上午 Databricks 宣布,已经完成了由安德森-霍洛维茨基金(Andreessen Horowitz)牵头的4亿美元F轮融资,参与融资的有微软(Microsoft)、Alkeon Capital Management、贝莱德(BlackRock)、Coatue Management、Dragoneer Investment Group、Geodesic、Green Bay Ventures、New Enterprise Associates、T. Rowe Price和Tiger Global Management。经过这次融资,Databricks 的估值高达62亿美 w397090770 6年前 (2019-10-22) 1138℃ 0评论0喜欢
Apache Spark Delta Lake 的更新(update)和删除都是在 0.3.0 版本发布的,参见这里,对应的 Patch 参见这里。和前面几篇源码分析文章一样,我们也是先来看看在 Delta Lake 里面如何使用更新这个功能。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopDelta Lake 更新使用Delta Lake 的官方文档为我们提供如何 w397090770 6年前 (2019-10-19) 2116℃ 0评论3喜欢
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop一年一度的 Spark + AI Summit Europe 峰会于2019年10月15-17日在欧洲的阿姆斯特丹举行。在10年16日 数砖和 Linux 基金会共同宣布 Delta Lake 和 将成为一个 Linux 基金会项目(参考:The Delta Lake Project Turns to Linux Foundation to Become the Open Standard for Data Lakes)。该项 w397090770 6年前 (2019-10-16) 1242℃ 0评论2喜欢
在这篇我们介绍了 Spark Delta Lake 0.4.0 的发布,并提到这个版本支持 Python API 和部分 SQL。本文我们将详细介绍 Delta Lake 0.4.0 Python API 的使用。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop在本文中,我们将基于 Apache Spark™ 2.4.3,演示一个准时航班情况业务场景中,如何使用全新的 Delta Lake 0.4.0 w397090770 6年前 (2019-10-04) 1048℃ 0评论1喜欢
Apache Spark 发布了 Delta Lake 0.4.0,主要支持 DML 的 Python API、将 Parquet 表转换成 Delta Lake 表 以及部分 SQL 功能。 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop下面详细地介绍这些功能部分功能的 SQL 支持SQL 的支持能够为用户提供极大的便利,如果大家去看数砖的 Delta Lake 产品,你肯定已 w397090770 6年前 (2019-10-01) 1308℃ 0评论4喜欢
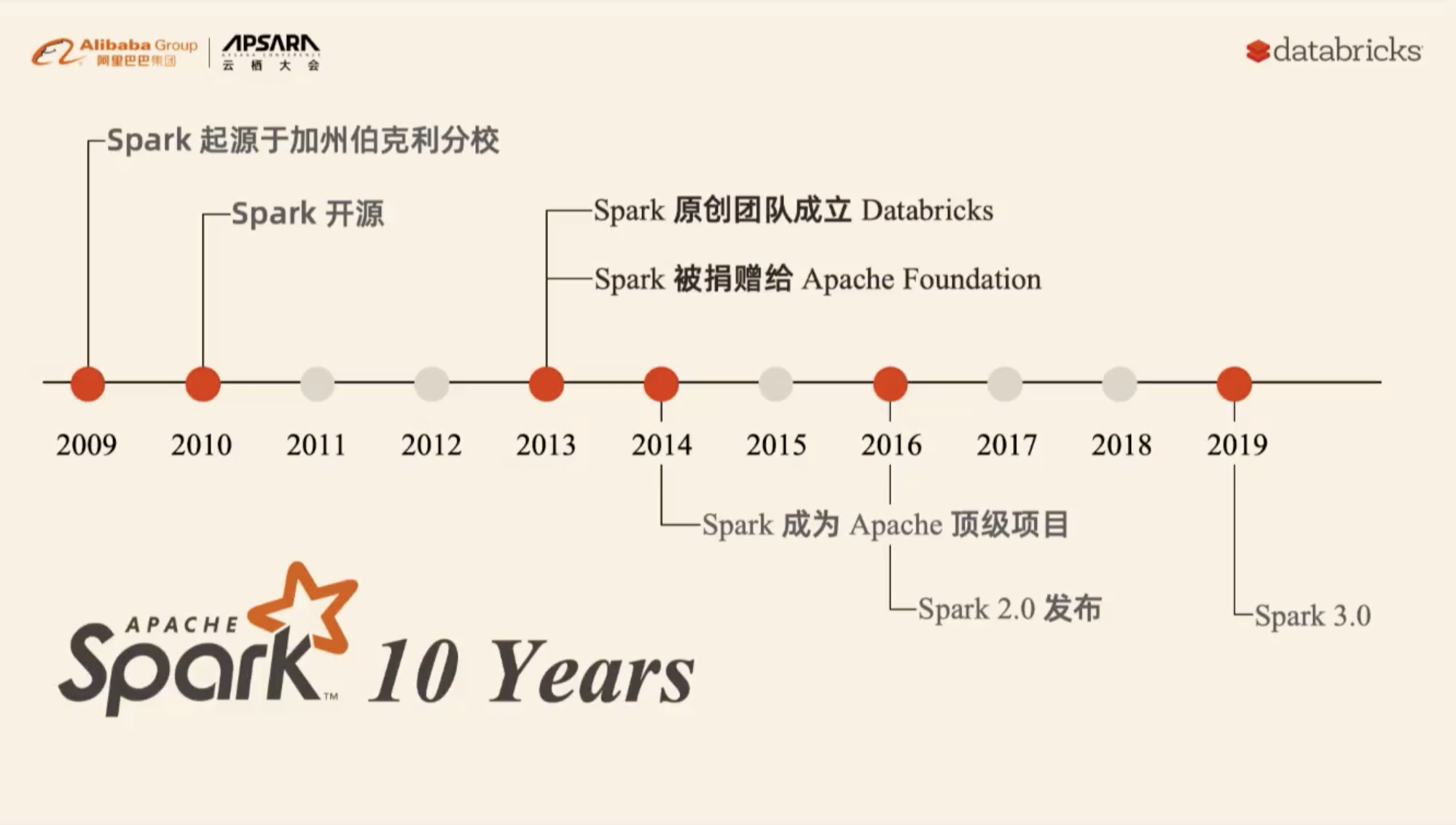
本资料来自2019-09-26在杭州举办的云栖大会的大数据 & AI 峰会分会。议题名称《New Developments in the Open Source Ecosystem: Apache Spark 3.0 and Koalas》,分享嘉宾李潇,Databricks Spark 研发总监。下面是本次会议的视频(由于微信公众号的限制,只能发布小于30分钟的视频,完整视频和 PPT 请关注 过往记忆大数据 公众号并回复 spark_yq 获取。) w397090770 6年前 (2019-09-27) 2948℃ 0评论3喜欢
Delta Lake 的 Delete 功能是由 0.3.0 版本引入的,参见这里,对应的 Patch 参见这里。在介绍 Apache Spark Delta Lake 实现逻辑之前,我们先来看看如何使用 delete 这个功能。Delta Lake 删除使用Delta Lake 的官方文档为我们提供如何使用 Delete 的几个例子,参见这里,如下:[code lang="scala"]import io.delta.tables._val iteblogDeltaTable = DeltaTable.forPath(spa w397090770 6年前 (2019-09-27) 1563℃ 0评论2喜欢


![Spark+AI Summit Europe 2019 高清视频下载[共135个]](https://www.iteblog.com/pic/spark/spark+ai_summit_europe_2019-iteblog.jpg)