为了让大家更好地学习交流,过往记忆大数据花了一个周末的时间把 Awesome Big Data 里近 600 个大数据相关的调度、存储、计算、数据库以及可视化等介绍全部翻译了一遍,供大家学习交流。关系型数据库管理系统MySQL 世界上最流行的开源数据库。PostgreSQL 世界上最先进的开源数据库。Oracle Database - 对象关系数据库管理系统。T w397090770 6年前 (2019-09-23) 12590℃ 0评论34喜欢
Delta Lake 写数据是其最基本的功能,而且其使用和现有的 Spark 写 Parquet 文件基本一致,在介绍 Delta Lake 实现原理之前先来看看如何使用它,具体使用如下:[code lang="scala"]df.write.format("delta").save("/data/iteblog/delta/test/")//数据按照 dt 分区df.write.format("delta").partitionBy("dt").save("/data/iteblog/delta/test/" w397090770 6年前 (2019-09-10) 2220℃ 0评论2喜欢
Delta Lake 是一个存储层,为 Apache Spark 和大数据 workloads 提供 ACID 事务能力,其通过写和快照隔离之间的乐观并发控制(optimistic concurrency control),在写入数据期间提供一致性的读取,从而为构建在 HDFS 和云存储上的数据湖(data lakes)带来可靠性。Delta Lake 还提供内置数据版本控制,以便轻松回滚。为了更好的学习 Delta Lake ,本文 w397090770 6年前 (2019-09-09) 4043℃ 0评论4喜欢
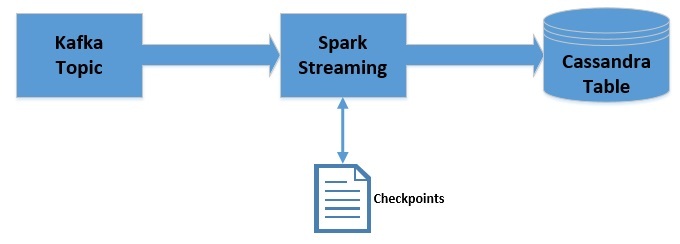
Apache Kafka 是一个可扩展,高性能,低延迟的平台,允许我们像消息系统一样读取和写入数据。我们可以很容易地在 Java 中使用 Kafka。Spark Streaming 是 Apache Spark 的一部分,是一个可扩展、高吞吐、容错的实时流处理引擎。虽然是使用 Scala 开发的,但是支持 Java API。Apache Cassandra 是分布式的 NoSQL 数据库。在这篇文章中,我们将 w397090770 6年前 (2019-09-08) 4119℃ 0评论8喜欢
我们已经在 这篇文章详细介绍了 Apache Spark Delta Lake 的事务日志是什么、主要用途以及如何工作的。那篇文章已经可以很好地给大家介绍 Delta Lake 的内部工作原理,原子性保证,本文为了学习的目的,带领大家从源码级别来看看 Delta Lake 事务日志的实现。在看本文时,强烈建议先看一下《深入理解 Apache Spark Delta Lake 的事务日志》文 w397090770 6年前 (2019-09-02) 1797℃ 0评论4喜欢
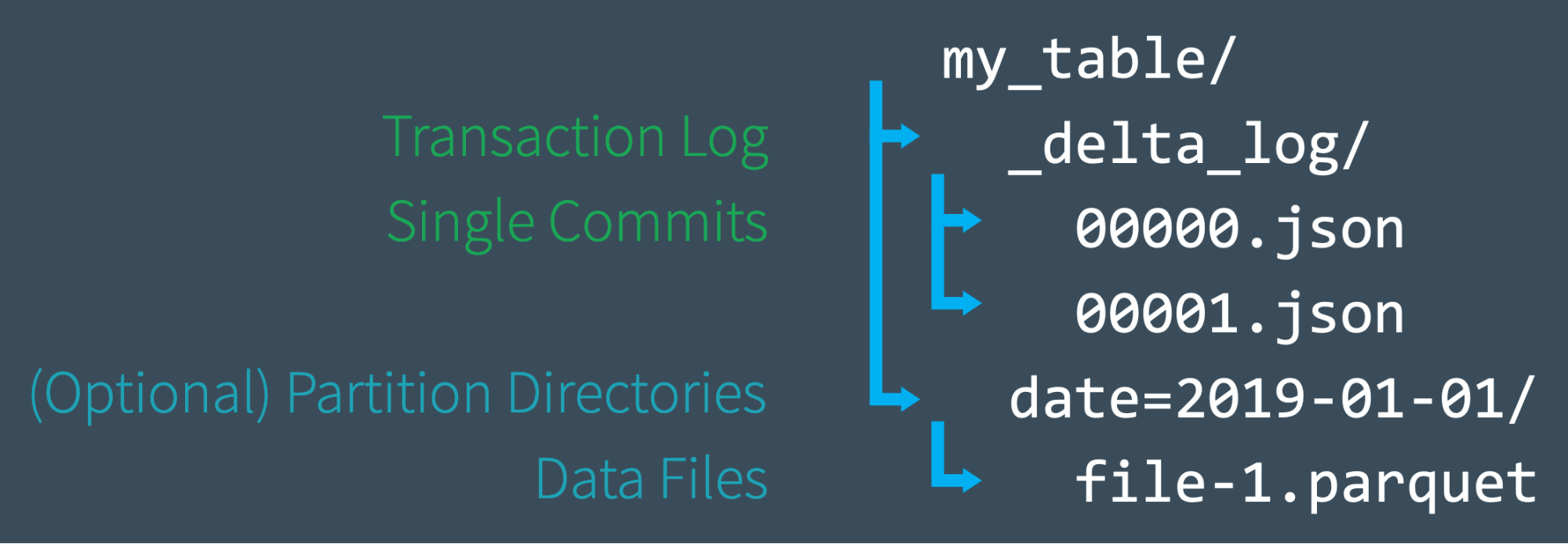
事务日志是理解 Delta Lake 的关键,因为它是贯穿许多最重要功能的通用模块,包括 ACID 事务、可扩展的元数据处理、时间旅行(time travel)等。本文我们将探讨事务日志(Transaction Log)是什么,它在文件级别是如何工作的,以及它如何为多个并发读取和写入问题提供优雅的解决方案。事务日志(Transaction Log)是什么Delta Lake 事务日 w397090770 6年前 (2019-08-22) 1871℃ 0评论6喜欢
今年是我创建这个微信公众号的第五年,五年来,收获了6.8万粉丝。这个数字,在自媒体圈子,属于十八线小规模的那种,但是在纯技术圈,还是不错的成绩,我很欣慰。我花在这个号上面的时间挺多的。我平时下班比较晚,一般下班到家了,老婆带着孩子已经安睡了,我便轻手轻脚的拿出电脑,带上耳机,开始我一天的知识盘 w397090770 6年前 (2019-08-13) 5681℃ 2评论33喜欢
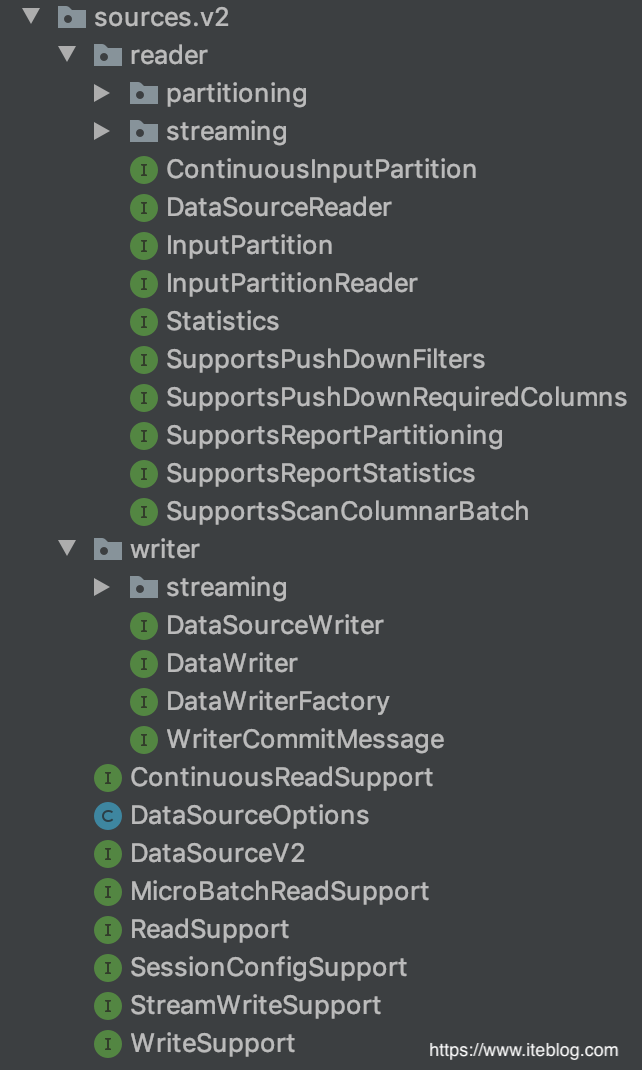
我们在 Apache Spark DataSource V2 介绍及入门编程指南(上) 文章中介绍了 Apache Spark DataSource V1 的不足,所以才有了 Data Source API V2 的诞生。Data Source API V2为了解决 Data Source V1 的一些问题,从 Apache Spark 2.3.0 版本开始,社区引入了 Data Source API V2,在保留原有的功能之外,还解决了 Data Source API V1 存在的一些问题,比如不再依赖上层 API w397090770 6年前 (2019-08-13) 4102℃ 1评论9喜欢
Data Source API 定义如何从存储系统进行读写的相关 API 接口,比如 Hadoop 的 InputFormat/OutputFormat,Hive 的 Serde 等。这些 API 非常适合用户在 Spark 中使用 RDD 编程的时候使用。使用这些 API 进行编程虽然能够解决我们的问题,但是对用户来说使用成本还是挺高的,而且 Spark 也不能对其进行优化。为了解决这些问题,Spark 1.3 版本开始引入了 D w397090770 6年前 (2019-08-13) 3659℃ 0评论3喜欢
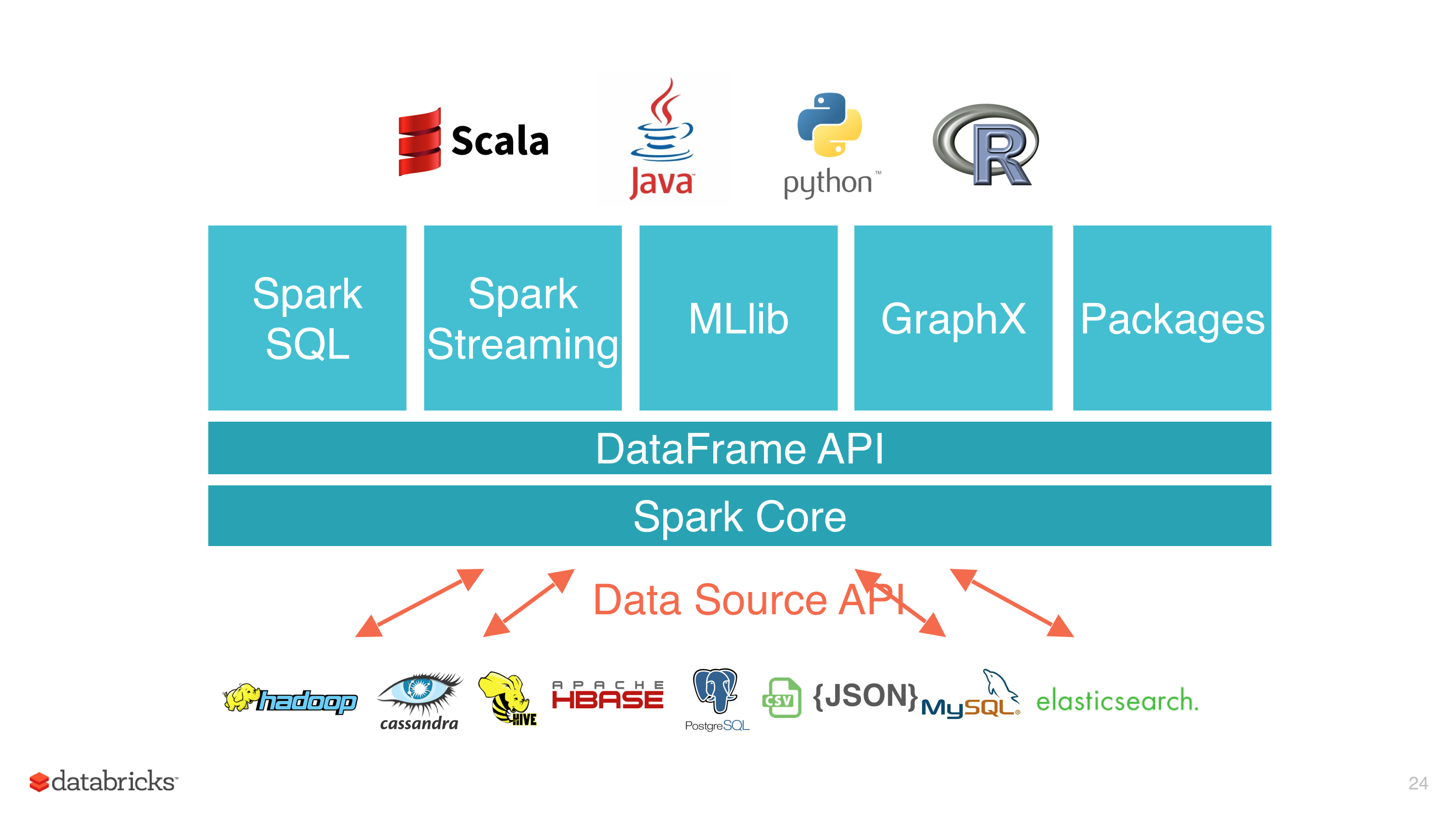
Spark SQL 是 Spark 最新且技术最复杂的组件之一。它同时支持 SQL 查询和新的 DataFrame API。Spark SQL 的核心是 Catalyst 优化器,它以一种全新的方式利用高级语言的特性(例如:Scala 的模式匹配和 Quasiquotes ①)构建一个可扩展的查询优化器。最近我们在 SIGMOD 2015 发表了一篇论文(合作者:Davies Liu,Joseph K. Bradley,Xiangrui Meng,Tomer Kaftan w397090770 6年前 (2019-07-21) 3333℃ 0评论5喜欢