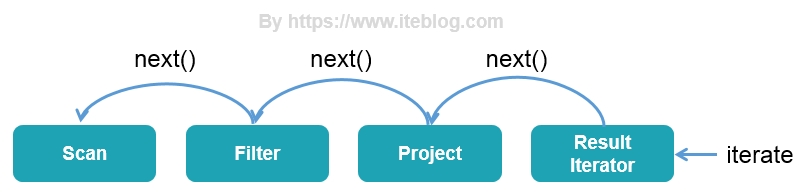
终于到最后一篇了,我们在前面两篇文章中《一条 SQL 在 Apache Spark 之旅(上)》 和 《一条 SQL 在 Apache Spark 之旅(中)》 介绍了 Spark SQL 之旅的 SQL 解析、逻辑计划绑定、逻辑计划优化以及物理计划生成阶段,本文我们将继续接上文,介绍 Spark SQL 的全阶段代码生成以及最后的执行过程。全阶段代码生成阶段 - WholeStageCodegen前面 w397090770 6年前 (2019-06-19) 9159℃ 0评论17喜欢
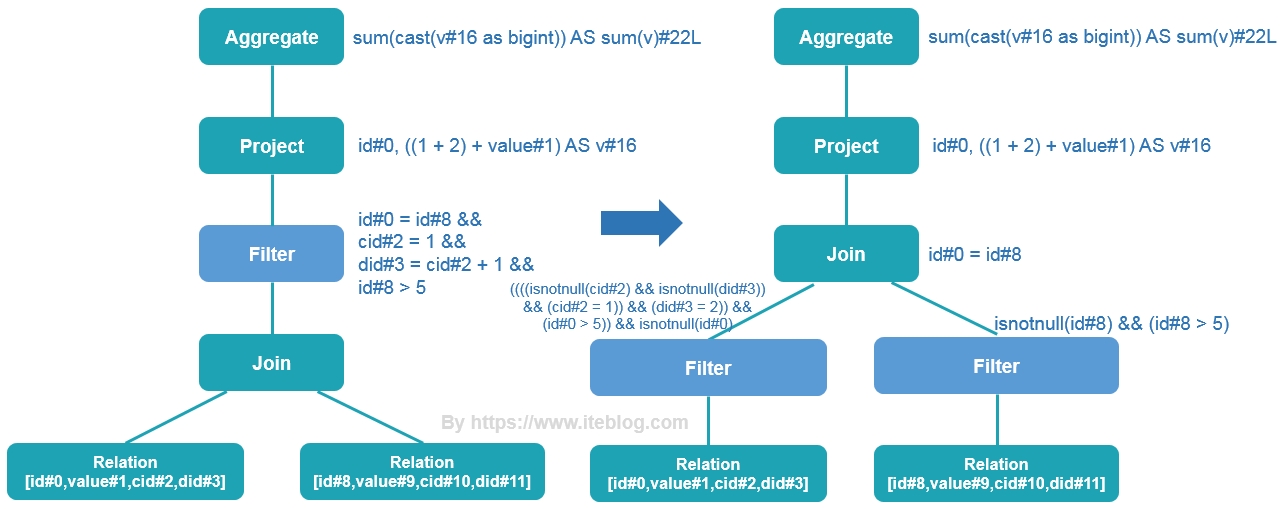
在 《一条 SQL 在 Apache Spark 之旅(上)》 文章中我们介绍了一条 SQL 在 Apache Spark 之旅的 Parser 和 Analyzer 两个过程,本文接上文继续介绍。优化逻辑计划阶段 - Optimizer在前文的绑定逻辑计划阶段对 Unresolved LogicalPlan 进行相关 transform 操作得到了 Analyzed Logical Plan,这个 Analyzed Logical Plan 是可以直接转换成 Physical Plan 然后在 Spark 中执 w397090770 6年前 (2019-06-18) 5759℃ 4评论21喜欢
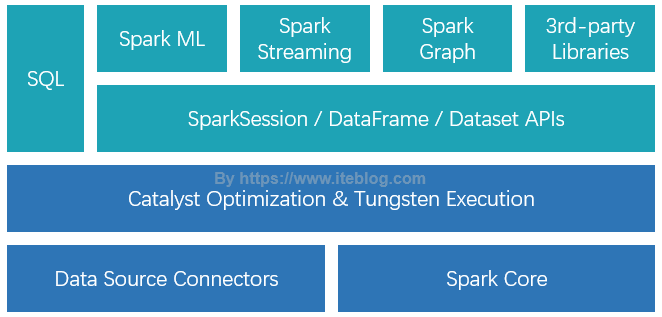
Spark SQL 是 Spark 众多组件中技术最复杂的组件之一,它同时支持 SQL 查询和 DataFrame DSL。通过引入了 SQL 的支持,大大降低了开发人员的学习和使用成本。目前,整个 SQL 、Spark ML、Spark Graph 以及 Structured Streaming 都是运行在 Catalyst Optimization & Tungsten Execution 之上的,如下图所示:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关 w397090770 6年前 (2019-06-12) 10995℃ 0评论31喜欢
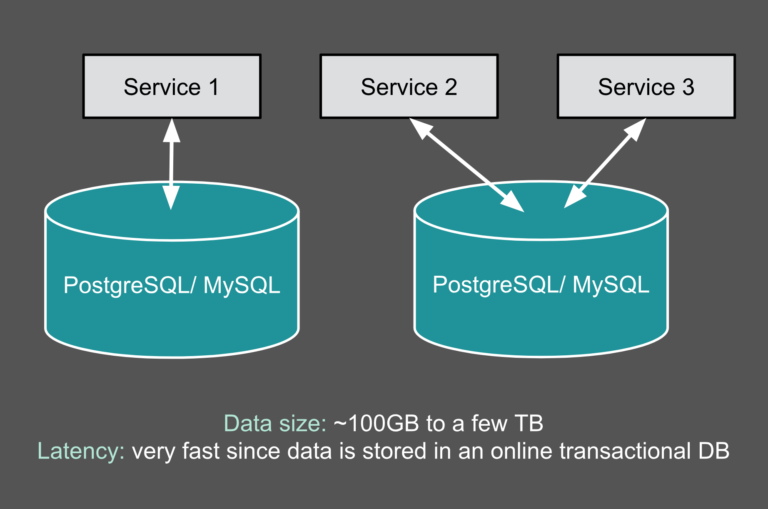
Uber 致力于在全球市场上提供更安全,更可靠的运输服务。为了实现这一目标,Uber 在很大程度上依赖于数据驱动的决策,从预测高流量事件期间骑手的需求到识别和解决我们的驾驶员-合作伙伴注册流程中的瓶颈。自2014年以来,Uber 一直致力于开发大数据解决方案,确保数据可靠性,可扩展性和易用性;现在 Uber 正专注于提高他们平 w397090770 6年前 (2019-06-06) 3315℃ 0评论8喜欢
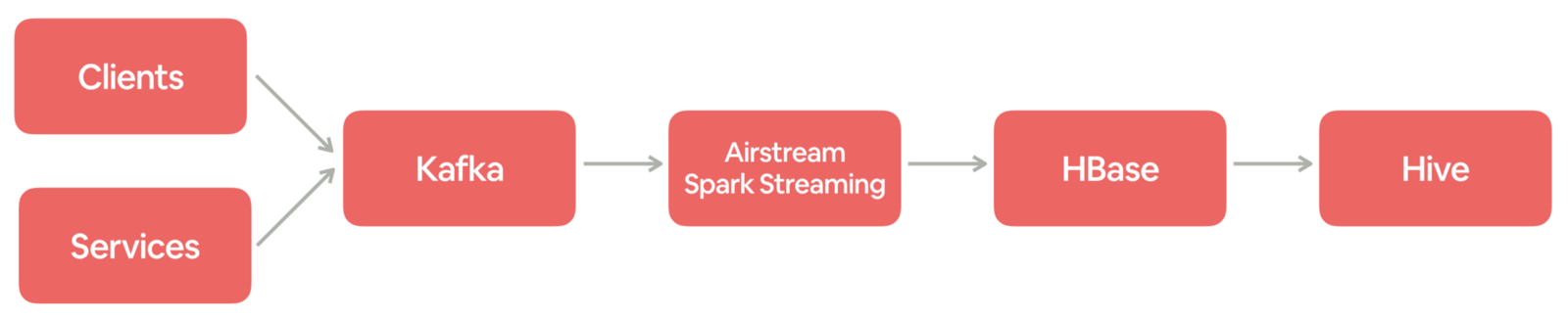
Airbnb 日志事件获取日志事件从客户端(例如移动应用程序和 Web 浏览器)和在线服务发出,其中包含行为或操作的关键信息。每个事件都有一个特定的信息。例如,当客人在 Airbnb.com 上搜索马里布的海滨别墅时,将生成包含位置,登记和结账日期等的搜索事件。在 Airbnb,事件记录对于我们理解客人和房东,然后为他们提供更 w397090770 6年前 (2019-05-19) 2890℃ 0评论8喜欢
为期三天的 SPARK + AI SUMMIT 2019 于 2019年04月23日-25日在旧金山(San Francisco)进行。数据和 AI 是需要结合的,而 Spark 能够处理海量数据的分析,将 Spark 和 AI 进行结合,无疑会带来更好的产品。作为大数据领域的顶级会议,Spark+AI Summit 2019 吸引了全球大量技术大咖参会,而且 Spark+AI Summit 越做越大,本次会议议题快接近200多个。会议的 w397090770 6年前 (2019-05-07) 859℃ 0评论0喜欢
今年的 Spark + AI Summit 2019 databricks 开源了几个重磅的项目,比如 Delta Lake,Koalas 等,Koalas 是一个新的开源项目,它增强了 PySpark 的 DataFrame API,使其与 pandas 兼容。Python 数据科学在过去几年中爆炸式增长,pandas 已成为生态系统的关键。 当数据科学家拿到一个数据集时,他们会使用 pandas 进行探索。 它是数据清洗和分析的终极工 w397090770 6年前 (2019-04-29) 3385℃ 0评论6喜欢
2019年4月25日,微软的 Rahul Potharaju、Terry Kim 以及 Tyson Condie 在 Spark + AI Summit 2019 会议上为我们带来主题为 《Introducing .NET Bindings for Apache Spark 》的分享,并宣布 .NET for Apache Spark 预览版正式发布。.NET 框架是由微软开发,一个致力于敏捷软件开发、快速应用开发、平台无关性和网络透明化的免费软件框架,用于构建许多不同类型的 w397090770 6年前 (2019-04-28) 16466℃ 0评论4喜欢
本文英文原文:Open Sourcing Delta Lake2019年4月24日在美国旧金山召开的 Spark+AI Summit 2019 会上,Databricks 的联合创始人及 CEO Ali Ghodsi 宣布将 Databricks Runtime 里面的 Delta Lake 基于 Apache License 2.0 协议开源。Delta Lake 是一个存储层,为 Apache Spark 和大数据 workloads 提供 ACID 事务能力,其通过写和快照隔离之间的乐观并发控制(optimistic concurrency w397090770 6年前 (2019-04-25) 7178℃ 0评论12喜欢
Apache Spark 和 Apache HBase 是两个使用比较广泛的大数据组件。很多场景需要使用 Spark 分析/查询 HBase 中的数据,而目前 Spark 内置是支持很多数据源的,其中就包括了 HBase,但是内置的读取数据源还是使用了 TableInputFormat 来读取 HBase 中的数据。这个 TableInputFormat 有一些缺点:一个 Task 里面只能启动一个 Scan 去 HBase 中读取数据;TableIn w397090770 6年前 (2019-04-02) 13191℃ 5评论18喜欢

![Spark+AI Summit 2019 PPT 下载[共124个]](https://www.iteblog.com/pic/spark/spark+ai_summit_2019-iteblog.png)



