经常使用 Apache Spark 从 Kafka 读数的同学肯定会遇到这样的问题:某些 Spark 分区已经处理完数据了,另一部分分区还在处理数据,从而导致这个批次的作业总消耗时间变长;甚至导致 Spark 作业无法及时消费 Kafka 中的数据。为了简便起见,本文讨论的 Spark Direct 方式读取 Kafka 中的数据,这种情况下 Spark RDD 中分区和 Kafka 分区是一一对 w397090770 7年前 (2018-09-08) 6649℃ 0评论25喜欢
!! expr :逻辑非。%expr1 % expr2 - 返回 expr1/expr2 的余数.例子:[code lang="sql"]> SELECT 2 % 1.8; 0.2> SELECT MOD(2, 1.8); 0.2[/code]&expr1 & expr2 - 返回 expr1 和 expr2 的按位AND的结果。例子:[code lang="sql"]> SELECT 3 & 5; 1[/code]*expr1 * expr2 - 返回 expr1*expr2.例子:[code lang="sql"]> SELECT 2 * 3; 6[/code]+ w397090770 7年前 (2018-07-13) 16667℃ 0评论2喜欢
为期三天的 Spark Summit 在美国时间 2018-06-04 ~ 06-06 于旧金山的 Moscone Center 举行,不少人已经注意到,今年的会议已经更名为 Spark+AI, 去年 12 月份时,Databricks 在他们的博客中就已经提到过,2018 年的会议将包括更多人工智能的内容,某种意义上也代表着 Spark 未来的发展方向。作为大数据领域的顶级会议,Spark Summit 2018 吸引了全球近 200 w397090770 7年前 (2018-06-18) 3679℃ 0评论14喜欢
背景在默认情况下,Spark Streaming 通过 receivers (或者是 Direct 方式) 以生产者生产数据的速率接收数据。当 batch processing time > batch interval 的时候,也就是每个批次数据处理的时间要比 Spark Streaming 批处理间隔时间长;越来越多的数据被接收,但是数据的处理速度没有跟上,导致系统开始出现数据堆积,可能进一步导致 Executor 端出现 w397090770 7年前 (2018-05-28) 27402℃ 409评论62喜欢
杭州第六次 Spark & Flink Meetup 于2018年05月12日在华为杭研所1号楼1楼报告厅进行。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop议题本次会议的议题如下:冯叶磊 - 华为云 《Time GeoSpatial on Flink SQL》范文臣 - Spark PMC 《deep dive into structural streaming》梁永峰 - 阿里《基于Flink的流计算平台 w397090770 7年前 (2018-05-13) 3946℃ 1评论8喜欢
本文将对 Spark 的内存管理模型进行分析,下面的分析全部是基于 Apache Spark 2.2.1 进行的。为了让下面的文章看起来不枯燥,我不打算贴出代码层面的东西。文章仅对统一内存管理模块(UnifiedMemoryManager)进行分析,如对之前的静态内存管理感兴趣,请参阅网上其他文章。我们都知道 Spark 能够有效的利用内存并进行分布式计算,其内 w397090770 7年前 (2018-04-01) 19936℃ 4评论93喜欢
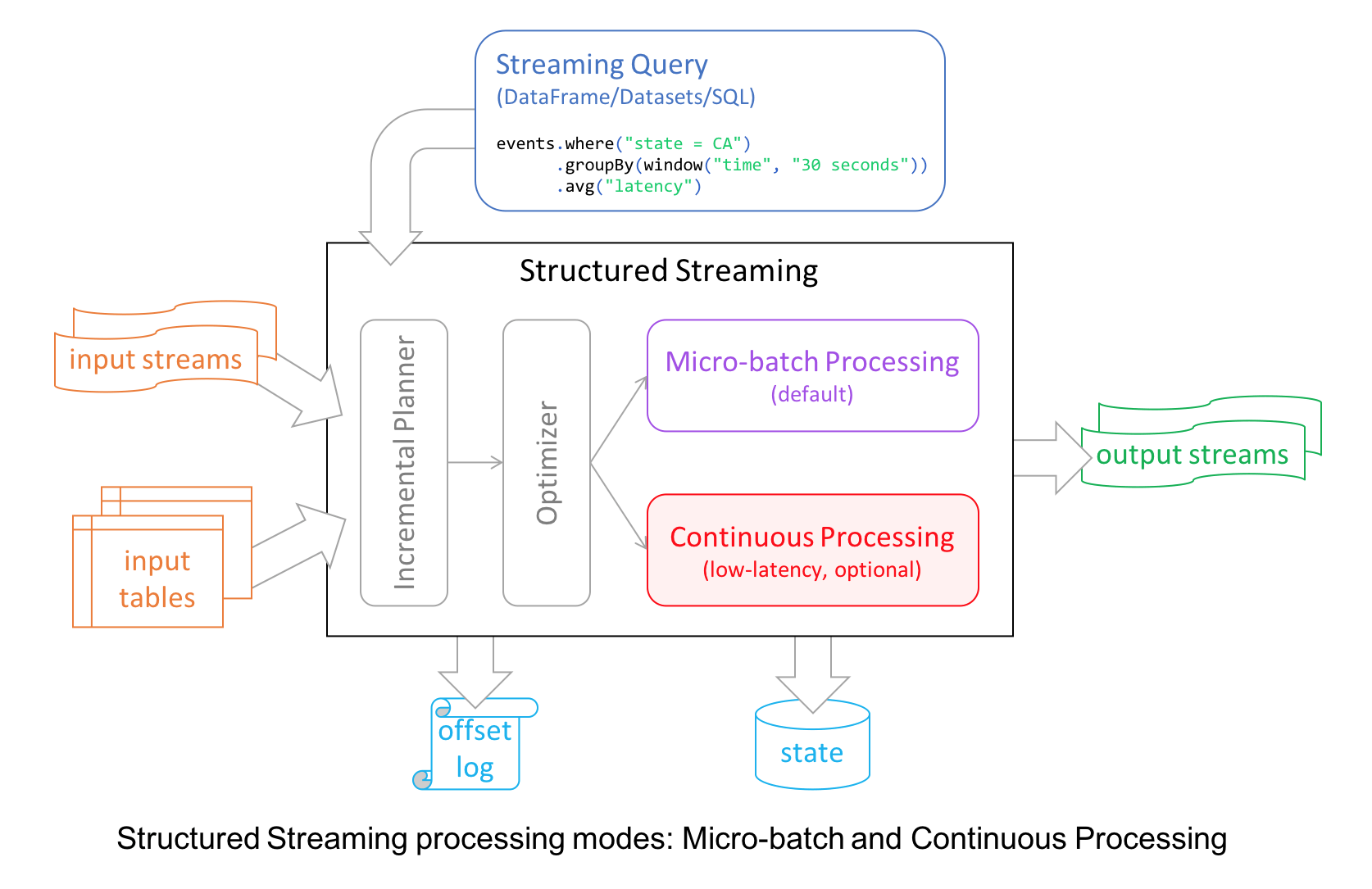
本文翻译自:Introducing Apache Spark 2.3为了继续实现 Spark 更快,更轻松,更智能的目标,Spark 2.3 在许多模块都做了重要的更新,比如 Structured Streaming 引入了低延迟的连续处理(continuous processing);支持 stream-to-stream joins;通过改善 pandas UDFs 的性能来提升 PySpark;支持第四种调度引擎 Kubernetes clusters(其他三种分别是自带的独立模式St w397090770 7年前 (2018-03-01) 7333℃ 3评论32喜欢
Databricks 开源的 Apache Spark 对于分布式数据处理来说是一个伟大的进步。我们在使用 Spark 时发现了很多可圈可点之处,我们在此与大家分享一下我们在简化Spark使用和编程以及加快Spark在生产环境落地上做的一些努力。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop一个Spark Streaming读取Kafka w397090770 7年前 (2018-02-28) 6753℃ 0评论13喜欢
用户定义函数(User-defined functions, UDFs)是大多数 SQL 环境的关键特性,用于扩展系统的内置功能。 UDF允许开发人员通过抽象其低级语言实现来在更高级语言(如SQL)中启用新功能。 Apache Spark 也不例外,并且提供了用于将 UDF 与 Spark SQL工作流集成的各种选项。在这篇博文中,我们将回顾 Python,Java和 Scala 中的 Apache Spark UDF和UDAF(u w397090770 7年前 (2018-02-14) 15061℃ 0评论21喜欢
本文作者:汪愈舟 俞育才 郭晨钊 程浩(英特尔),李元健(百度)Spark SQL是Apache Spark最广泛使用的一个组件,它提供了非常友好的接口来分布式处理结构化数据,在很多应用领域都有成功的生产实践,但是在超大规模集群和数据集上,Spark SQL仍然遇到不少易用性和可扩展性的挑战。为了应对这些挑战,英特尔大数据技术团 w397090770 7年前 (2018-01-11) 91136℃ 0评论78喜欢



![Spark Summit North America 201806 全部PPT下载[共147个]](https://www.iteblog.com/pic/spark/spark-summit-north-america-2018-06_iteblog.png)