Spark Summit 2017会议于2017年06月05日至07日在旧金山(San Francisco)进行,全部会议一共179个。从会议我们得到目前的Spark发展方向主要包括两大主题:深度学习(Deep Learning)提升流系统的性能( Streaming Performance)如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop2016年是深度学习之年,而 w397090770 8年前 (2017-06-18) 1974℃ 0评论4喜欢
本书作者:Rajdeep Dua、Manpreet Singh Ghotra、 Nick Pentreath,由Packt出版社于2017年04月出版,全书共532页。本书是2015年02月出版的Machine Learning with Spark的第二版。通过本书将学习到以下的知识:Get hands-on with the latest version of Spark MLCreate your first Spark program with Scala and PythonSet up and configure a development environment for Spark on your own computer, as well zz~~ 8年前 (2017-05-27) 4561℃ 0评论14喜欢
如果你在Spark SQL中运行的SQL语句过长的话,会出现 java.lang.StackOverflowError 异常:[code lang="java"]java.lang.StackOverflowError at org.apache.spark.sql.hive.HiveQl$$anonfun$22.apply(HiveQl.scala:924) at org.apache.spark.sql.hive.HiveQl$$anonfun$22.apply(HiveQl.scala:924) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244) at scala.collection.TraversableLike$$anonfun w397090770 8年前 (2017-05-17) 6364℃ 0评论7喜欢
Spark 的 shell 作为一个强大的交互式数据分析工具,提供了一个简单的方式来学习 API。它可以使用 Scala(在 Java 虚拟机上运行现有的 Java 库的一个很好方式) 或 Python。我们很可能会在Spark Shell模式下运行下面的测试代码:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop[code lang="scala"]scala> imp w397090770 8年前 (2017-04-26) 2899℃ 0评论9喜欢
本书由Andrew Morgan所著,全书共560页;Packt Publishing出版社于2017年03月出版。通过本书你将学习到以下的知识: 1、Learn the design patterns that integrate Spark into industrialized data science pipelines 2、See how commercial data scientists design scalable code and reusable code for data science services 3、Explore cutting edge data science methods so that you can study tre zz~~ 8年前 (2017-04-17) 3555℃ 2评论8喜欢
最近几年关于Apache Spark框架的声音是越来越多,而且慢慢地成为大数据领域的主流系统。最近几年Apache Spark和Apache Hadoop的Google趋势可以证明这一点:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop上图已经明显展示出最近五年,Apache Spark越来越受开发者们的欢迎,大家通过Google搜索更多关 w397090770 8年前 (2017-04-12) 6711℃ 0评论46喜欢
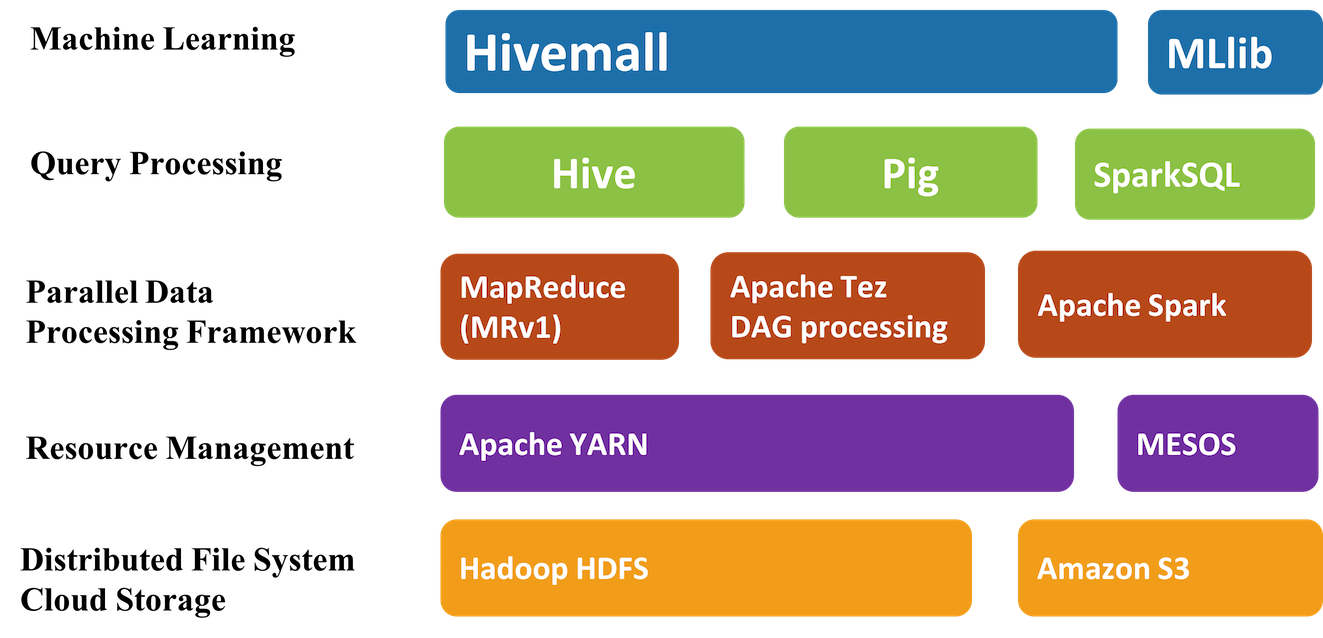
Apache Hivemall是机器学习算法(machine learning algorithms)和多功能数据分析函数(versatile data analytics functions)的集合,它通过Apache Hive UDF / UDAF / UDTF接口提供了一些易于使用的机器学习算法。Hivemall 最初由Treasure Data 开发的,并于2016年9月捐献给 Apache 软件基金会,进入了Apache 孵化器。 Apache Hivemall提供了各种功能包括:回归( w397090770 8年前 (2017-03-29) 3515℃ 1评论10喜欢
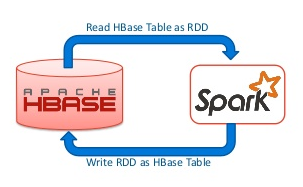
在使用Spark操作Hbase的时候,其返回的数据类型是RDD[ImmutableBytesWritable,Result],我们可能会对这个结果进行其他的操作,比如join等,但是因为org.apache.hadoop.hbase.io.ImmutableBytesWritable 和 org.apache.hadoop.hbase.client.Result 并没有实现 java.io.Serializable 接口,程序在运行的过程中可能发生以下的异常:[code lang="bash"]Serialization stack: - object not ser w397090770 8年前 (2017-03-23) 5474℃ 1评论13喜欢
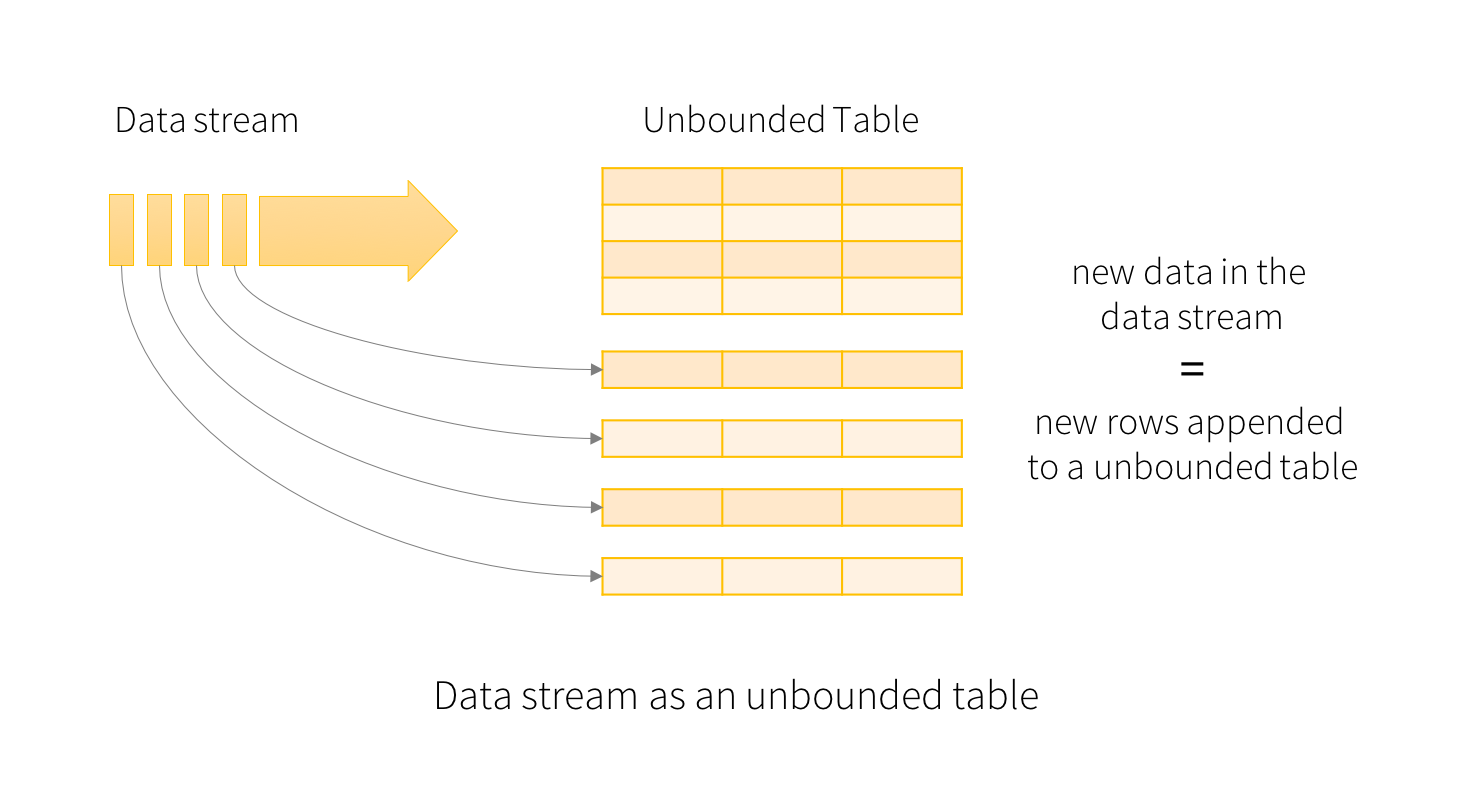
概览 Structured Streaming 是一个可拓展,容错的,基于Spark SQL执行引擎的流处理引擎。使用小量的静态数据模拟流处理。伴随流数据的到来,Spark SQL引擎会逐渐连续处理数据并且更新结果到最终的Table中。你可以在Spark SQL上引擎上使用DataSet/DataFrame API处理流数据的聚集,事件窗口,和流与批次的连接操作等。最后Structured Streaming zz~~ 8年前 (2017-03-22) 10798℃ 2评论11喜欢
本文作者:李寅威,从事大数据、机器学习方面的工作,目前就职于CVTE联系方式:微信(coridc),邮箱(251469031@qq.com)原文链接: Spark2.1.0 + CarbonData1.0.0集群模式部署及使用入门1 引言 Apache CarbonData是一个面向大数据平台的基于索引的列式数据格式,由华为大数据团队贡献给Apache社区,目前最新版本是1.0.0版。介于 zz~~ 8年前 (2017-03-13) 3486℃ 0评论11喜欢

![Spark Summit 2017 SanFrancisco全部PPT下载[共143个]](https://www.iteblog.com/pic/spark-summit-2017-SanFrancisco.png)
![[电子书]Machine Learning with Spark Second Edition PDF下载](https://www.iteblog.com/pic/books/Machine_Learning_with_Spark_Second_Edition_iteblog.jpg)

![[电子书]Mastering Spark for Data Science PDF下载](https://www.iteblog.com/pic/books/mastering-spark-data-science_iteblog.jpg)