在过去的几个月时间里,我们一直忙于我们所爱的大数据开源软件的下一个主要版本开发工作:Apache Spark 2.0。Spark 1.0已经出现了2年时间,在此期间,我们听到了赞美以及投诉。Spark 2.0的开发基于我们过去两年学到的:用户所喜爱的我们加倍投入;用户抱怨的我们努力提高。本文将总结Spark 2.0的三大主题:更容易、更快速、更智 w397090770 9年前 (2016-05-12) 8846℃ 2评论26喜欢
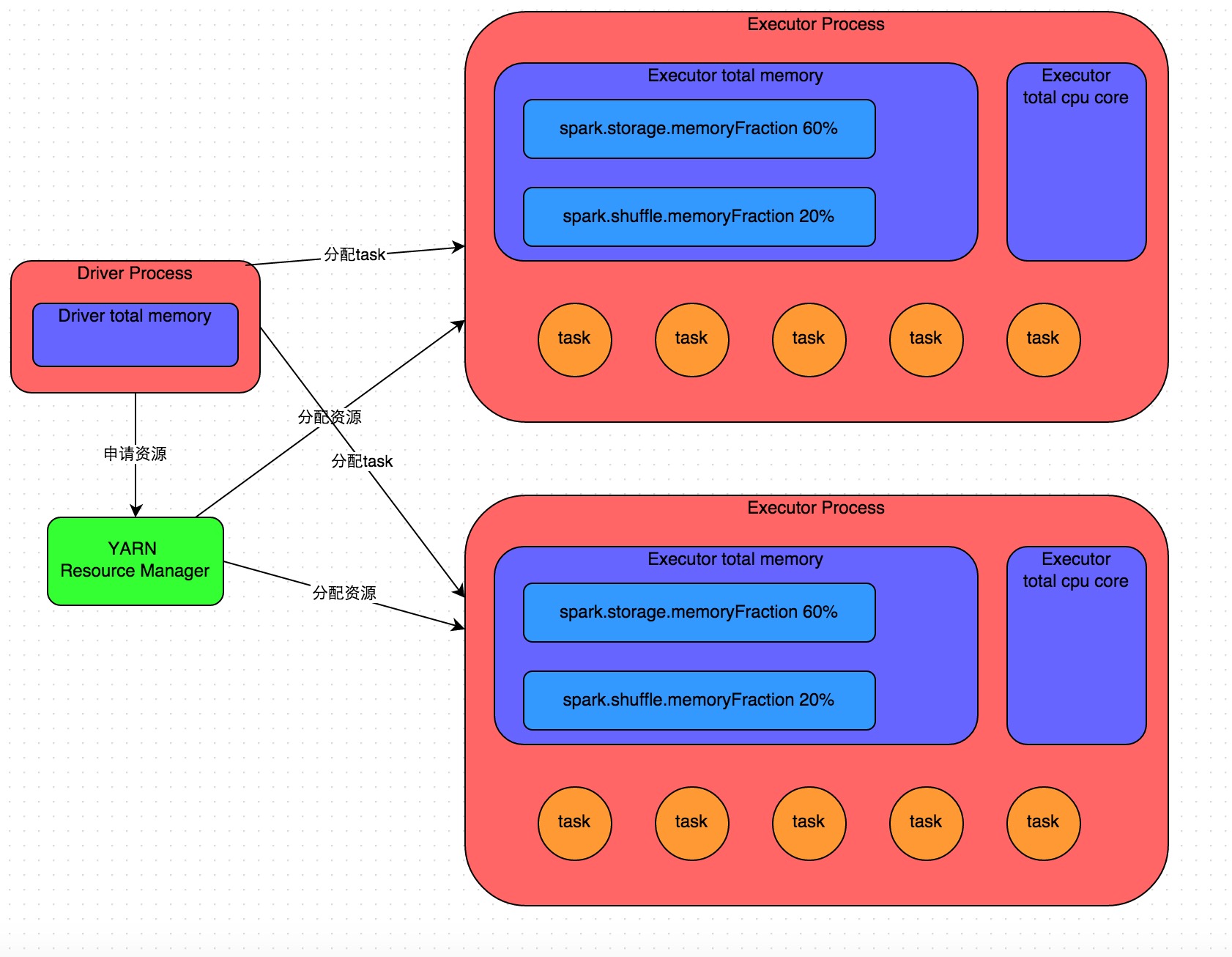
《Spark性能优化:开发调优篇》《Spark性能优化:资源调优篇》《Spark性能优化:数据倾斜调优》《Spark性能优化:shuffle调优》 在开发完Spark作业之后,就该为作业配置合适的资源了。Spark的资源参数,基本都可以在spark-submit命令中作为参数设置。很多Spark初学者,通常不知道该设置哪些必要的参数,以及如何设置这些参 w397090770 9年前 (2016-05-04) 30986℃ 8评论38喜欢
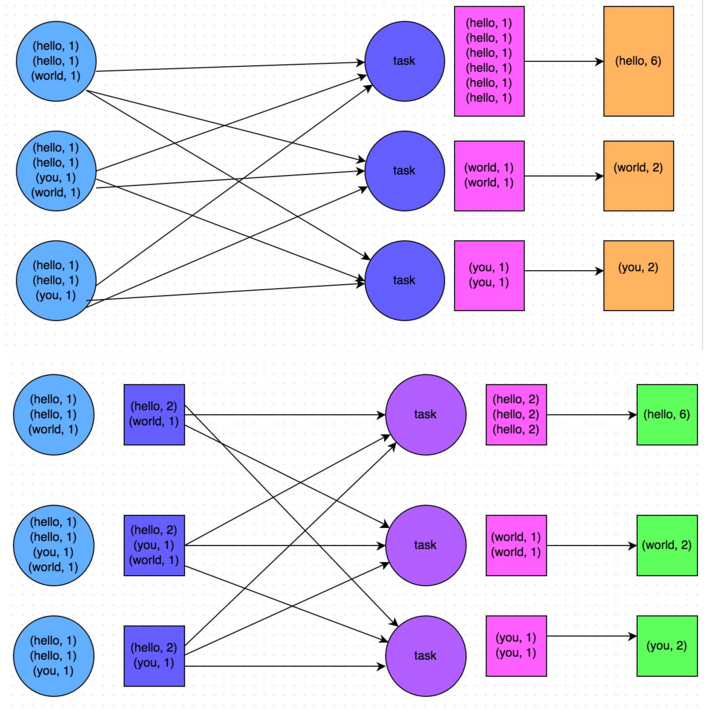
《Spark性能优化:开发调优篇》《Spark性能优化:资源调优篇》《Spark性能优化:数据倾斜调优》《Spark性能优化:shuffle调优》 在大数据计算领域,Spark已经成为了越来越流行、越来越受欢迎的计算平台之一。Spark的功能涵盖了大数据领域的离线批处理、SQL类处理、流式/实时计算、机器学习、图计算等各种不同类型的计 w397090770 9年前 (2016-05-04) 16901℃ 3评论45喜欢
PhantomJS是一个基于WebKit的服务器端JavaScript API,它基于BSD开源协议发布。PhantomJS无需浏览器即可实现对Web的支持,且原生支持各种Web标准,如DOM处理、JavaScript、CSS选择器、JSON、Canvas和可缩放矢量图形SVG。PhantomJS主要是通过JavaScript和CoffeeScript控制WebKit的CSS选择器、可缩放矢量图形SVG和HTTP网络等各个模块。PhantomJS主要支持Windows、M w397090770 9年前 (2016-04-29) 4280℃ 0评论5喜欢
本文是面向Spark初学者,有Spark有比较深入的理解同学可以忽略。前言很多初学者其实对Spark的编程模式还是RDD这个概念理解不到位,就会产生一些误解。比如,很多时候我们常常以为一个文件是会被完整读入到内存,然后做各种变换,这很可能是受两个概念的误导:1、RDD的定义,RDD是一个分布式的不可变数据集合; w397090770 9年前 (2016-04-20) 8499℃ 0评论33喜欢
由Databricks、UC Berkeley以及MIT联合为Apache Spark开发了一款图像处理类库,名为:GraphFrames,该类库是构建在DataFrame之上,它既能利用DataFrame良好的扩展性和强大的性能,同时也为Scala、Java和Python提供了统一的图处理API。什么是GraphFrames 与Apache Spark的GraphX类似,GraphFrames支持多种图处理功能,但得益于DataFrame因此GraphFrames与G w397090770 9年前 (2016-04-09) 4839℃ 0评论6喜欢
我们是否还需要另外一个新的数据处理引擎?当我第一次听到Flink的时候这是我是非常怀疑的。在大数据领域,现在已经不缺少数据处理框架了,但是没有一个框架能够完全满足不同的处理需求。自从Apache Spark出现后,貌似已经成为当今把大部分的问题解决得最好的框架了,所以我对另外一款解决类似问题的框架持有很强烈的怀 w397090770 9年前 (2016-04-04) 18169℃ 0评论42喜欢
Spark Streaming和Flink都能提供恰好一次的保证,即每条记录都仅处理一次。与其他处理系统(比如Storm)相比,它们都能提供一个非常高的吞吐量。它们的容错开销也都非常低。之前,Spark提供了可配置的内存管理,而Flink提供了自动内存管理,但从1.6版本开始,Spark也提供了自动内存管理。这两个流处理引擎确实有许多相似之处, w397090770 9年前 (2016-04-02) 4815℃ 0评论5喜欢
7.1 TF-IDF TF-IDF是一种特征向量化方法,这种方法多用于文本挖掘,通过算法可以反应出词在语料库中某个文档中的重要性。文档中词记为t,文档记为d , 语料库记为D . 词频TF(t,d) 是词t 在文档d 中出现的次数。文档频次DF(t,D) 是语料库中包括词t的文档数。如果使用词在文档中出现的频次表示词的重要程度,那么很容易取出反例, w397090770 9年前 (2016-03-27) 6062℃ 0评论6喜欢
Spark北京Meetup第十次活动将于北京时间2016年03月27日在北京市海淀区丹棱街5号微软亚太研发集团总部大厦1号楼进行。会议主题1. Spark in TalkingData 阎志涛 TalkingData研发副总裁2. Spark in GrowingIO 田毅 GrowingIO数据平台工程师 主要分享GrowingIO使用Spark进行数据处理过程中的各种小技巧 w397090770 9年前 (2016-03-14) 2433℃ 0评论6喜欢