Spark 1.6.1于2016年3月11日正式发布,此版本主要是维护版本,主要涉及稳定性修复,并不涉及到大的修改。推荐所有使用1.6.0的用户升级到此版本。 Spark 1.6.1主要修复的bug包括: 1、当写入数据到含有大量分区表时出现的OOM:SPARK-12546 2、实验性Dataset API的许多bug修复:SPARK-12478, SPARK-12696, SPARK-13101, SPARK-12932 w397090770 9年前 (2016-03-11) 3975℃ 0评论5喜欢
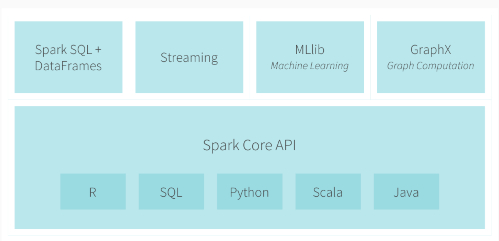
现在Apache Spark已形成一个丰富的生态系统,包括官方的和第三方开发的组件或工具。后面主要给出5个使用广泛的第三方项目。Spark官方构建了一个非常紧凑的生态系统组件,提供各种处理能力。 下面是Spark官方给出的生态系统组件 1、Spark DataFrames:列式存储的分布式数据组织,类似于关系型数据表。 2、Spark SQL:可 w397090770 9年前 (2016-03-08) 4955℃ 2评论7喜欢
Spark Streaming除了可以使用内置的接收器(Receivers,比如Flume、Kafka、Kinesis、files和sockets等)来接收流数据,还可以自定义接收器来从任意的流中接收数据。开发者们可以自己实现org.apache.spark.streaming.receiver.Receiver类来从其他的数据源中接收数据。本文将介绍如何实现自定义接收器,并且在Spark Streaming应用程序中使用。我们可以用S w397090770 9年前 (2016-03-03) 5987℃ 2评论4喜欢
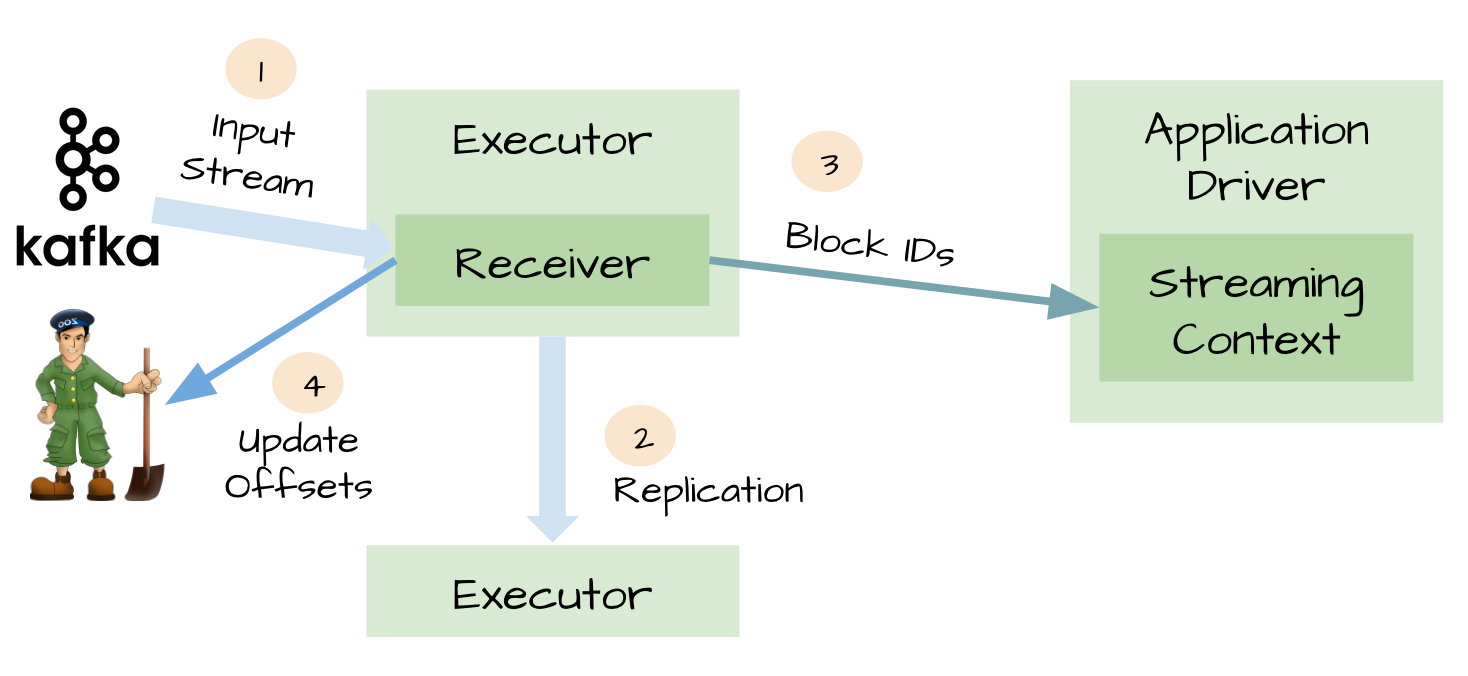
当我们正确地部署好Spark Streaming,我们就可以使用Spark Streaming提供的零数据丢失机制。为了体验这个关键的特性,你需要满足以下几个先决条件: 1、输入的数据来自可靠的数据源和可靠的接收器; 2、应用程序的metadata被application的driver持久化了(checkpointed ); 3、启用了WAL特性(Write ahead log)。 下面我将简单 w397090770 9年前 (2016-03-02) 17694℃ 16评论50喜欢
即日起,关注@Spark技术博客 及@ 一位微博好友并转发本文章到微博有机会获取《Spark大数据分析实战》:/archives/1590。3月12日在微博抽奖平台抽取1位同学并赠送此书。本活动已经结束,抽奖信息已经在新浪微博抽奖平台公布 《Spark大数据分析实战》由高彦杰和倪亚宇编写,通过典型数据分析应用场景、算法与系统架构,结 w397090770 9年前 (2016-03-02) 8572℃ 0评论44喜欢
Spark Summit East 2016:视频,PPT Spark Summit East 2016会议于2016年2月16日至2月18日在美国纽约进行。总体来说,Spark Summit一年比一年火,单看纽约的峰会中,规模已从900人增加到500个公司的1300人,更吸引到更多大型公司的分享,包括Bloomberg、Capital One、Novartis、Comcast等公司。而在这次会议上,Databricks还发布了两款产品——Commu w397090770 9年前 (2016-02-27) 5685℃ 0评论14喜欢
Spark Summit East 2016:视频,PPT Spark Summit East 2016会议于2016年2月16日至2月18日在美国纽约进行。总体来说,Spark Summit一年比一年火,单看纽约的峰会中,规模已从900人增加到500个公司的1300人,更吸引到更多大型公司的分享,包括Bloomberg、Capital One、Novartis、Comcast等公司。而在这次会议上,Databricks还发布了两款产品——Commu w397090770 9年前 (2016-02-27) 6200℃ 0评论9喜欢
Apache Zeppelin使用入门指南:安装Apache Zeppelin使用入门指南:编程Apache Zeppelin使用入门指南:添加外部依赖 在前面的两篇文章中我们介绍了如何编译和部署Apache Zeppelin、如何使用Apache Zeppelin。这篇文章中将介绍如何将外部依赖库加入到Apache Zeppelin中。 在现实情况下,我们编写程序一般都是需要依赖外部的相关类库 w397090770 9年前 (2016-02-04) 8247℃ 0评论7喜欢
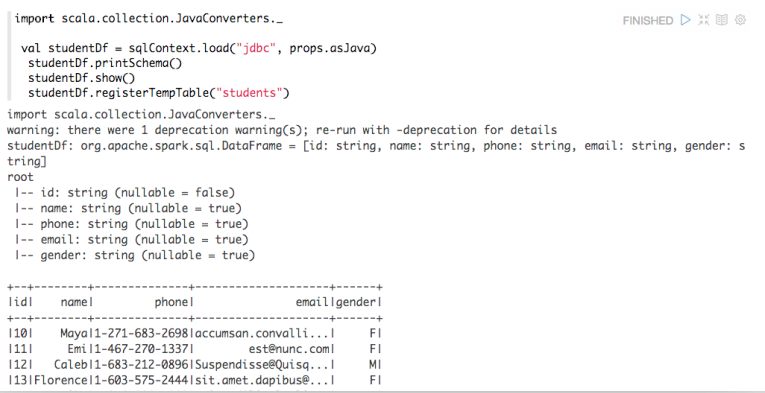
Apache Zeppelin使用入门指南:安装Apache Zeppelin使用入门指南:编程Apache Zeppelin使用入门指南:添加外部依赖使用Apache Zeppelin 编译和启动完Zeppelin相关的进程之后,我们就可以来使用Zeppelin了。我们进入到https://www.iteblog.com:8080页面,我们可以在页面上直接操作Zeppelin,依次选择Notebook->Create new note,然后会弹出一个对话框 w397090770 9年前 (2016-02-03) 25403℃ 2评论31喜欢
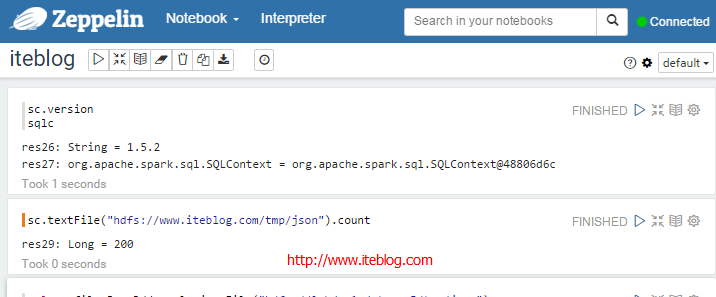
Apache Zeppelin使用入门指南:安装Apache Zeppelin使用入门指南:编程Apache Zeppelin使用入门指南:添加外部依赖 Apache Zeppelin是一款基于web的notebook(类似于ipython的notebook),支持交互式地数据分析。原生就支持Spark、Scala、SQL 、shell, markdown等。而且它是完全开源的,目前还处于Apache孵化阶段。本文所有的操作都是基于Apache Zeppelin w397090770 9年前 (2016-02-02) 20778℃ 9评论20喜欢




![Spark Summit East 2016 PPT免费下载[共65个]](https://www.iteblog.com/wp-content/themes/yusi2.0/img/pic/5.jpg)