我们知道,编写Scala程序的时候可以使用下面两种方法之一:[code lang="scala"]object IteblogTest extends App { //ToDo}object IteblogTest{ def main(args: Array[String]): Unit = { //ToDo }}[/code] 上面的两种方法都可以运行程序,但是在Spark中,第一种方法有时可不会正确的运行(出现异常或者是数据不见了)。比如下面的代码运 w397090770 9年前 (2015-12-10) 5336℃ 0评论5喜欢
Hive on Spark功能目前只增加下面九个参数,具体含义可以参见下面介绍。hive.spark.client.future.timeout Hive client请求Spark driver的超时时间,如果没有指定时间单位,默认就是秒。Expects a time value with unit (d/day, h/hour, m/min, s/sec, ms/msec, us/usec, ns/nsec), which is sec if not specified. Timeout for requests from Hive client to remote Spark driver.hive.spark.job.mo w397090770 10年前 (2015-12-07) 24662℃ 2评论11喜欢
Spark已经取代Hadoop成为最活跃的开源大数据项目。但是,在选择大数据框架时,企业不能因此就厚此薄彼。近日,著名大数据专家Bernard Marr在一篇文章(http://www.forbes.com/sites/bernardmarr/2015/06/22/spark-or-hadoop-which-is-the-best-big-data-framework/)中分析了Spark和Hadoop的异同。 Hadoop和Spark均是大数据框架,都提供了一些执行常见大数据任务 w397090770 10年前 (2015-12-01) 9584℃ 0评论31喜欢
《Spark RDD缓存代码分析》 《Spark Task序列化代码分析》 《Spark分区器HashPartitioner和RangePartitioner代码详解》 《Spark Checkpoint读操作代码分析》 《Spark Checkpoint写操作代码分析》 上次我对Spark RDD缓存的相关代码《Spark RDD缓存代码分析》进行了简要的介绍,本文将对Spark RDD的checkpint相关的代码进行相关的 w397090770 10年前 (2015-11-25) 8961℃ 5评论14喜欢
我们知道,Spark相比Hadoop最大的一个优势就是可以将数据cache到内存,以供后面的计算使用。本文将对这部分的代码进行分析。 我们可以通过rdd.persist()或rdd.cache()来缓存RDD中的数据,cache()其实就是调用persist()实现的。persist()支持下面的几种存储级别:[code lang="scala"]val NONE = new StorageLevel(false, false, false, false)val DISK_ONLY = w397090770 10年前 (2015-11-17) 9758℃ 0评论15喜欢
Spark的作业会通过DAGScheduler的处理生产许多的Task并构建成DAG图,而分割出的Task最终是需要经过网络分发到不同的Executor。在分发的时候,Task一般都会依赖一些文件和Jar包,这些依赖的文件和Jar会对增加分发的时间,所以Spark在分发Task的时候会将Task进行序列化,包括对依赖文件和Jar包的序列化。这个是通过spark.closure.serializer参数 w397090770 10年前 (2015-11-16) 6334℃ 0评论8喜欢
最近由Reynold Xin给Spark开发者发布的一封邮件透露,Spark社区很有可能会跳过Spark 1.7版本的发布,而直接转向Spark 2.x。 如果Spark 2.x发布,那么它将: (1)、Spark编译将默认使用Scala 2.11,但是还是会支持Scala 2.10。 (2)、移除对Hadoop 1.x的支持。不过也有可能移除对Hadoop 2.2以下版本的支持,因为Hadoop 2.0和2.1版本分 w397090770 10年前 (2015-11-13) 6996℃ 0评论16喜欢
在Spark中分区器直接决定了RDD中分区的个数;也决定了RDD中每条数据经过Shuffle过程属于哪个分区;也决定了Reduce的个数。这三点看起来是不同的方面的,但其深层的含义是一致的。 我们需要注意的是,只有Key-Value类型的RDD才有分区的,非Key-Value类型的RDD分区的值是None的。 在Spark中,存在两类分区函数:HashPartitioner w397090770 10年前 (2015-11-10) 18790℃ 2评论40喜欢
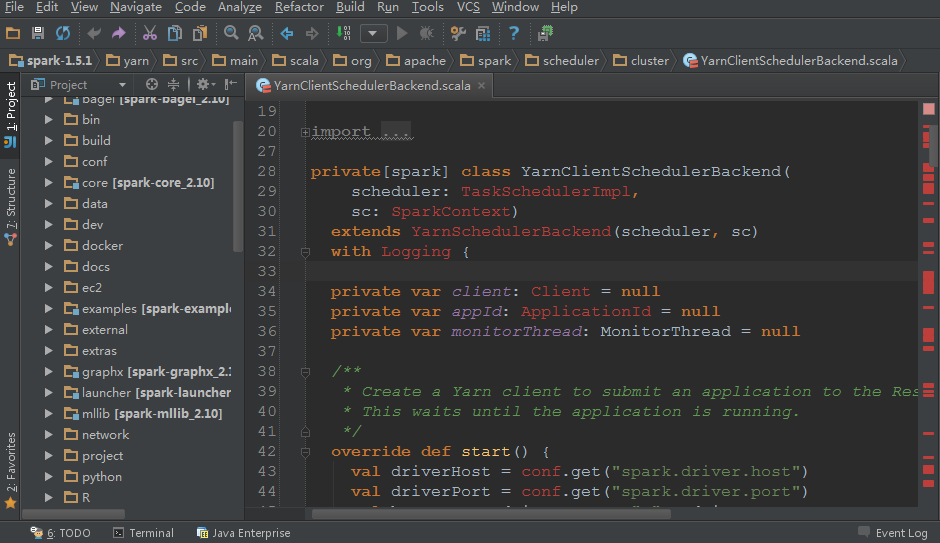
我们在学习或者使用Spark的时候都会选择下载Spark的源码包来加强Spark的学习。但是在导入Spark代码的时候,我们会发现yarn模块的相关代码总是有相关类依赖找不到的错误(如下图),而且搜索(快捷键Ctrl+N)里面的类时会搜索不到!这给我们带来了很多不遍。。 本文就是来解决这个问题的。我使用的是Idea IDE工具阅读代 w397090770 10年前 (2015-11-07) 9163℃ 4评论11喜欢
新世纪以来,互联网及个人终端的普及,传统行业的信息化及物联网的发展等产业变化产生了大量的数据,远远超出了单台机器能够处理的范围,分布式存储与处理成为唯一的选项。从2005年开始,Hadoop从最初Nutch项目的一部分,逐步发展成为目前最流行的大数据处理平台。Hadoop生态圈的各个项目,围绕着大数据的存储,计算, w397090770 10年前 (2015-11-06) 7985℃ 0评论9喜欢