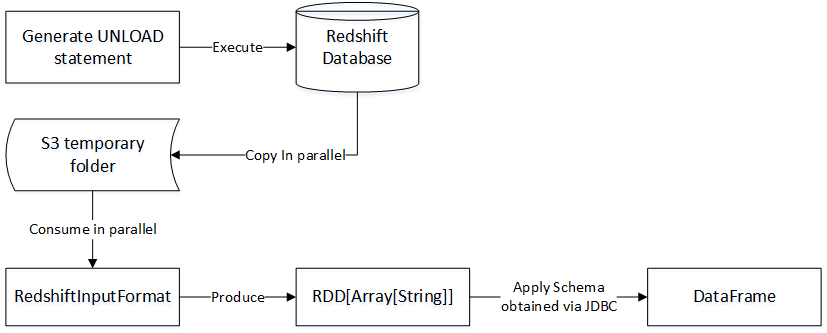
Spark Data Source API是从Spark 1.2开始提供的,它提供了可插拔的机制来和各种结构化数据进行整合。Spark用户可以从多种数据源读取数据,比如Hive table、JSON文件、Parquet文件等等。我们也可以到http://spark-packages.org/(这个网站貌似现在不可以访问了)网站查看Spark支持的第三方数据源工具包。本文将介绍新的Spark数据源包,通过它我们 w397090770 10年前 (2015-10-21) 3911℃ 0评论4喜欢
我们知道,在Spark中创建RDD的创建方式大概可以分为三种:(1)、从集合中创建RDD;(2)、从外部存储创建RDD;(3)、从其他RDD创建。 而从集合中创建RDD,Spark主要提供了两中函数:parallelize和makeRDD。我们可以先看看这两个函数的声明:[code lang="scala"]def parallelize[T: ClassTag]( seq: Seq[T], numSlices: Int = defaultParalle w397090770 10年前 (2015-10-09) 48340℃ 0评论60喜欢
Apache Spark社区刚刚发布了1.5版本,大家一定想知道这个版本的主要变化,这篇文章告诉你答案。DataFrame执行后端优化(Tungsten第一阶段) DataFrame可以说是整个Spark项目最核心的部分,在1.5这个开发周期内最大的变化就是Tungsten项目的第一阶段已经完成。主要的变化是由Spark自己来管理内存而不是使用JVM,这样可以避免JVM w397090770 10年前 (2015-09-09) 4806℃ 0评论14喜欢
Spark 1.5.0是1.x线上的第6个发行版。这个版本共处理了来自230+contributors和80+机构的1400+个patches。Spark 1.5的许多改变都是围绕在提升Spark的性能、可用性以及操作稳定性。Spark 1.5.0焦点在Tungsten项目,它主要是通过对低层次的组建进行优化从而提升Spark的性能。Spark 1.5版本为Streaming增加了operational特性,比如支持backpressure。另外比较重 w397090770 10年前 (2015-09-09) 3074℃ 0评论12喜欢
基于社区开发者们的观察,绝大多数的Spark应用程序的瓶颈不在于I/O或者网络,而在于CPU和内存。基于这个事实,开发者们发起了Tungsten项目,而Spark 1.5是Tungsten项目的第一阶段。Tungsten项目主要集中在三个方面,于此来提高Spark应用程序的内存和CPU的效率,使得性能能够接近硬件的限制。Tungsten项目的三个阶段内存管理和二 w397090770 10年前 (2015-09-09) 7446℃ 0评论5喜欢
我们在《Tachyon 0.7.0伪分布式集群安装与测试》文章中介绍了如何搭建伪分布式Tachyon集群。从官方文档得知,Spark 1.4.x和Tachyon 0.6.4版本兼容,而最新版的Tachyon 0.7.1和Spark 1.5.x兼容,目前最新版的Spark为1.4.1,所以下面的操作步骤全部是基于Tachyon 0.6.4平台的,Tachyon 0.6.4的搭建步骤和Tachyon 0.7.0类似。 废话不多说,开始介绍吧 w397090770 10年前 (2015-08-31) 5500℃ 0评论6喜欢
先说明一下,这里说的Hive on Spark是Hive跑在Spark上,用的是Spark执行引擎,而不是MapReduce,和Hive on Tez的道理一样。 从Hive 1.1版本开始,Hive on Spark已经成为Hive代码的一部分了,并且在spark分支上面,可以看这里https://github.com/apache/hive/tree/spark,并会定期的移到master分支上面去。关于Hive on Spark的讨论和进度,可以看这里https:// w397090770 10年前 (2015-08-31) 41896℃ 30评论43喜欢
Spark SQL主要目的是使得用户可以在Spark上使用SQL,其数据源既可以是RDD,也可以是外部的数据源(比如Parquet、Hive、Json等)。Spark SQL的其中一个分支就是Spark on Hive,也就是使用Hive中HQL的解析、逻辑执行计划翻译、执行计划优化等逻辑,可以近似认为仅将物理执行计划从MR作业替换成了Spark作业。本文就是来介绍如何通过Spark SQL来 w397090770 10年前 (2015-08-27) 74720℃ 19评论38喜欢
在极短的时间内,Apache Spark 迅速成长为大数据分析的技术核心。这就使得保守派担心在这个技术更新如此之快的年代它是否会同样快的被淘汰呢。我反而却坚信,spark仅仅是崭露头角。 在过去的几年时间,随着Hadoop技术爆炸和大数据逐渐占据主流地位,几件事情逐渐明晰: 1、对所有数据而言,Hadoop分布式文件系 w397090770 10年前 (2015-08-26) 2845℃ 0评论4喜欢
上海Spark Meetup第四次聚会将于2015年7月18日在太库科技创业发展有限公司举办,详细地址上海市浦东新区金科路2889弄3号长泰广场 C座12层,太库。本次聚会由七牛和Intel联合举办。大会主题 1、hadoop/spark生态的落地实践 王团结(七牛)七牛云数据平台工程师。主要负责数据平台的设计研发工作。关注大数据处理,高 w397090770 10年前 (2015-08-26) 2905℃ 0评论3喜欢