最近在Yarn上使用Spark,不管是yarn-cluster模式还是yarn-client模式,都出现了以下的异常:[code lang="java"]Application application_1434099279301_123706 failed 2 times due to AM Container for appattempt_1434099279301_123706_000002 exited with exitCode: 127 due to: Exception from container-launch:org.apache.hadoop.util.Shell$ExitCodeException:at org.apache.hadoop.util.Shell.runCommand(Shell.java:464) w397090770 10年前 (2015-06-19) 7885℃ 0评论3喜欢
一、活动时间 北京第八次Spark Meetup活动将于2015年06月27日进行;下午14:00-18:00。二、活动地点 海淀区海淀大街1号中关村梦想实验室(原中关村国际数字设计中心)4层三、活动内容 1、基于mesos和docker的spark实践 -- 马越 数人科技大数据核心开发工程师 2、Spark 1.4.0 新特性介绍 -- 朱诗雄 Databricks新晋 w397090770 10年前 (2015-06-17) 3098℃ 2评论2喜欢
今天早上我在博文里面更新了Spark 1.4.0正式发布,由于时间比较匆忙(要上班啊),所以在那篇文章里面只是简单地介绍了一下Spark 1.4.0,本文详细将详细地介绍Spark 1.4.0特性。如果你想尽早了解Spark等相关大数据消息,请关注本博客,或者本博客微信公共帐号iteblog_hadoop。 Apache Spark 1.4.0版本于美国时间2015年06月11日正式发 w397090770 10年前 (2015-06-12) 5087℃ 1评论1喜欢
早上时间匆忙,我将于晚点时间详细地介绍Spark 1.4的更新,请关注本博客。 Apache Spark 1.4.0的新特性可以看这里《Apache Spark 1.4.0新特性详解》。 Apache Spark 1.4.0于美国时间的2015年6月11日正式发布。Python 3支持,R API,window functions,ORC,DataFrame的统计分析功能,更好的执行解析界面,再加上机器学习管道从alpha毕业成 w397090770 10年前 (2015-06-12) 4749℃ 0评论11喜欢
我(不是博主,这里的我指的是Shivaram Venkataraman)很高兴地宣布即将发布的Apache Spark 1.4 release将包含SparkR,它是一个R语言包,允许数据科学家通过R shell来分析大规模数据集以及交互式地运行Jobs。 R语言是一个非常流行的统计编程语言,并且支持很多扩展以便支持数据处理和机器学习任务。然而,R中交互式地数据分析常 w397090770 10年前 (2015-06-10) 8253℃ 0评论12喜欢
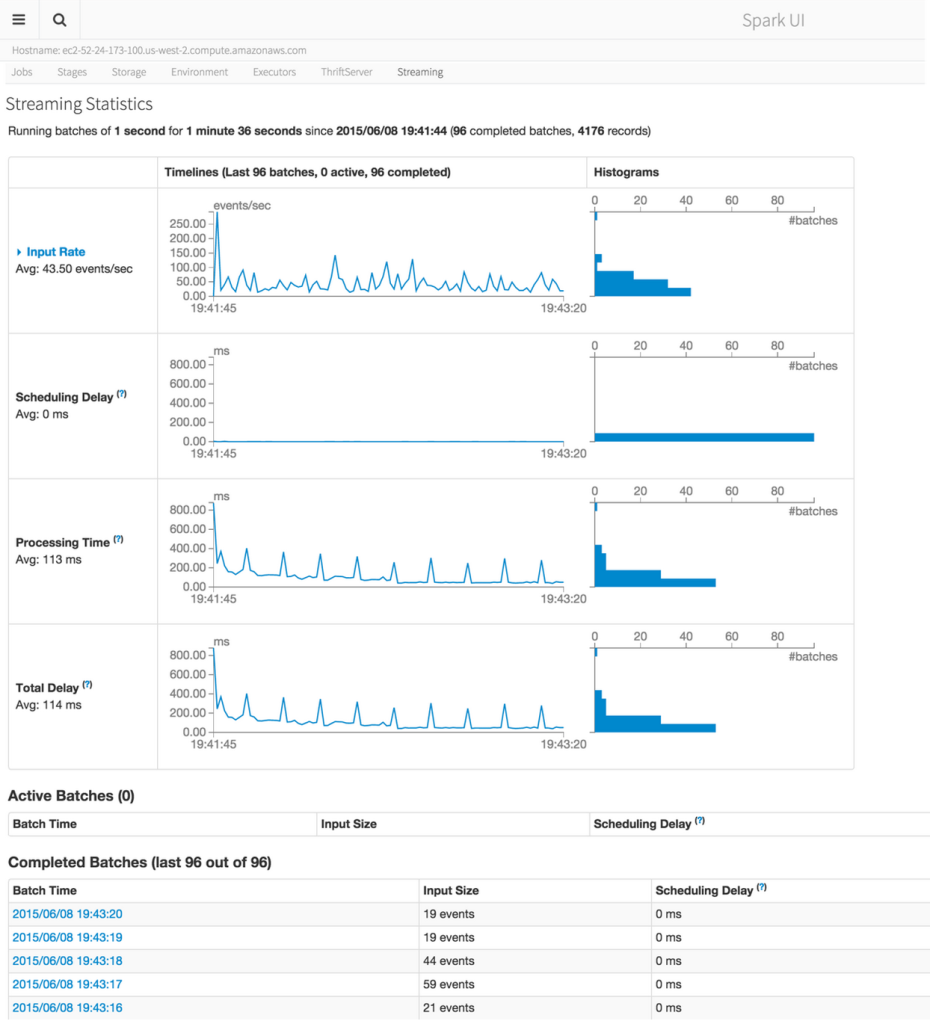
在Spark 1.4中引入了REST API,这样我们可以像Hadoop中REST API一样,很方便地获取一些信息。这个ISSUE在https://issues.apache.org/jira/browse/SPARK-3644里面首先被提出,已经在Spark 1.4加入。 Spark的REST API返回的信息是JSON格式的,开发者们可以很方便地通过这个API来创建可视化的Spark监控工具。目前这个API支持正在运行的应用程序,也支持 w397090770 10年前 (2015-06-10) 15843℃ 0评论8喜欢
概论 SparkR是一个R语言包,它提供了轻量级的方式使得可以在R语言中使用Apache Spark。在Spark 1.4中,SparkR实现了分布式的data frame,支持类似查询、过滤以及聚合的操作(类似于R中的data frames:dplyr),但是这个可以操作大规模的数据集。SparkR DataFrames DataFrame是数据组织成一个带有列名称的分布式数据集。在概念上和关系 w397090770 10年前 (2015-06-09) 36684℃ 1评论50喜欢
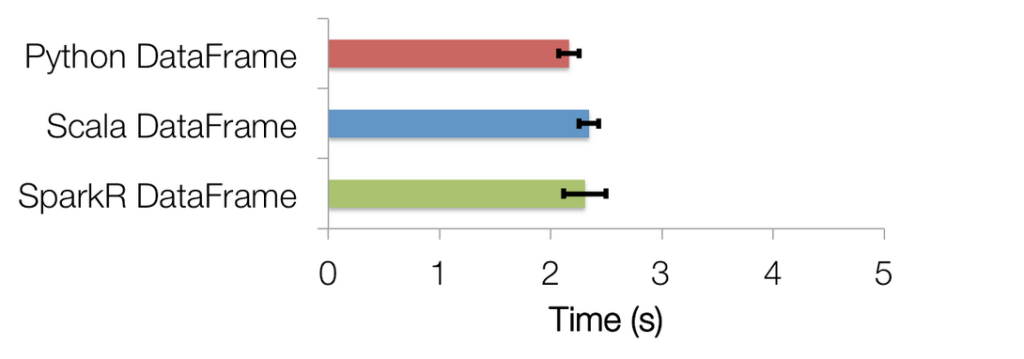
社区在Spark 1.3中开始引入了DataFrames,使得Apache Spark更加容易被使用。受R和Python中的data frames激发,Spark中的DataFrames提供了一些API,这些API在外部看起来像是操作单机的数据一样,而数据科学家对这些API非常地熟悉。统计是日常数据科学的一个重要组成部分。在即将发布的Spark 1.4中改进支持统计函数和数学函数(statistical and mathem w397090770 10年前 (2015-06-03) 14033℃ 2评论3喜欢
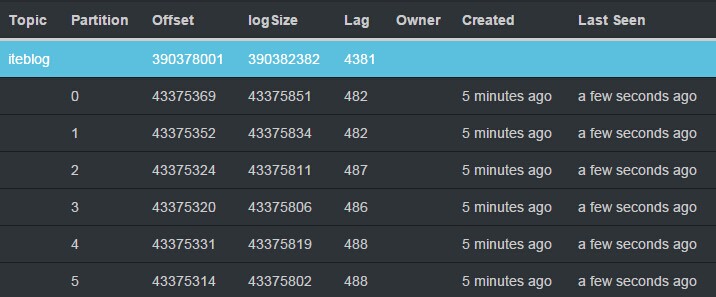
Apache Spark 1.3.0引入了Direct API,利用Kafka的低层次API从Kafka集群中读取数据,并且在Spark Streaming系统里面维护偏移量相关的信息,并且通过这种方式去实现零数据丢失(zero data loss)相比使用基于Receiver的方法要高效。但是因为是Spark Streaming系统自己维护Kafka的读偏移量,而Spark Streaming系统并没有将这个消费的偏移量发送到Zookeeper中, w397090770 10年前 (2015-06-02) 25741℃ 36评论22喜欢
CSV格式的文件也称为逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号。在本文中的CSV格式的数据就不是简单的逗号分割的),其文件以纯文本形式存表格数据(数字和文本)。CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符 w397090770 10年前 (2015-06-01) 61301℃ 2评论26喜欢