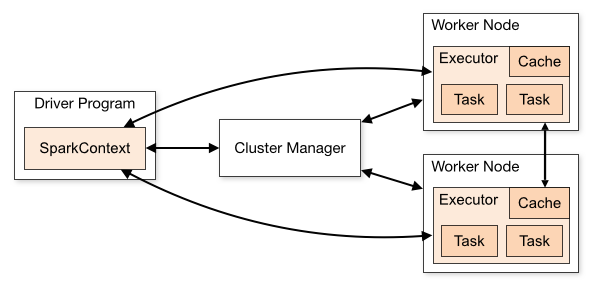
基于Spark通用计算平台,可以很好地扩展各种计算类型的应用,尤其是Spark提供了内建的计算库支持,像Spark Streaming、Spark SQL、MLlib、GraphX,这些内建库都提供了高级抽象,可以用非常简洁的代码实现复杂的计算逻辑、这也得益于Scala编程语言的简洁性。这里,我们基于1.3.0版本的Spark搭建了计算平台,实现基于Spark Streaming的实时 w397090770 11年前 (2015-05-30) 37658℃ 2评论76喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 《杭州第三次Spark meetup会议 w397090770 11年前 (2015-05-29) 5443℃ 0评论3喜欢
MapReduce和Spark比较 目前的大数据处理可以分为以下三个类型: 1、复杂的批量数据处理(batch data processing),通常的时间跨度在数十分钟到数小时之间; 2、基于历史数据的交互式查询(interactive query),通常的时间跨度在数十秒到数分钟之间; 3、基于实时数据流的数据处理(streaming data processing),通常的时间 w397090770 11年前 (2015-05-28) 5004℃ 0评论7喜欢
本博客的《Spark与Mysql(JdbcRDD)整合开发》和《Spark RDD写入RMDB(Mysql)方法二》文章中介绍了如何通过Spark读写Mysql中的数据。 在生产环境下,很多公司都会使用PostgreSQL数据库,这篇文章将介绍如何通过Spark获取PostgreSQL中的数据。我将使用Spark 1.3中的DataFrame(也就是之前的SchemaRDD),我们可以通过SQLContext加载数据库中的数据, w397090770 11年前 (2015-05-23) 13106℃ 0评论11喜欢
我们都知道Spark内部提供了HashPartitioner和RangePartitioner两种分区策略(这两种分区的代码解析可以参见:《Spark分区器HashPartitioner和RangePartitioner代码详解》),这两种分区策略在很多情况下都适合我们的场景。但是有些情况下,Spark内部不能符合咱们的需求,这时候我们就可以自定义分区策略。为此,Spark提供了相应的接口,我们只 w397090770 11年前 (2015-05-21) 18608℃ 0评论20喜欢
最近修改了Spark的一些代码,然后编译Spark出现了以下的异常信息:[code lang="scala"]error file=/iteblog/spark-1.3.1/streaming/src/main/scala/org/apache/spark/streaming/StreamingContext.scalamessage=File line length exceeds 100 characters line=279error file=/iteblog/spark-1.3.1/streaming/src/main/scala/org/apache/spark/streaming/StreamingContext.scalamessage=File line length exceeds 100 characters w397090770 11年前 (2015-05-20) 6226℃ 0评论3喜欢
如果你的Driver内存容量不能容纳一个大型RDD里面的所有数据,那么不要做以下操作:[code lang="scala"]val values = iteblogVeryLargeRDD.collect()[/code] Collect 操作会试图将 RDD 里面的每一条数据复制到Driver上,如果你Driver端的内存无法装下这些数据,这时候会发生内存溢出和崩溃。 相反,你可以调用take或者 takeSample来限制数 w397090770 11年前 (2015-05-20) 3237℃ 0评论4喜欢
spark.cleaner.ttl参数的原意是清除超过这个时间的所有RDD数据,以便腾出空间给后来的RDD使用。周期性清除保证在这个时间之前的元数据会被遗忘,对于那些运行了几小时或者几天的Spark作业(特别是Spark Streaming)设置这个是很有用的。注意:任何内存中的RDD只要过了这个时间就会被清除掉。官方文档是这么介绍的:Duration (secon w397090770 11年前 (2015-05-20) 8350℃ 0评论7喜欢
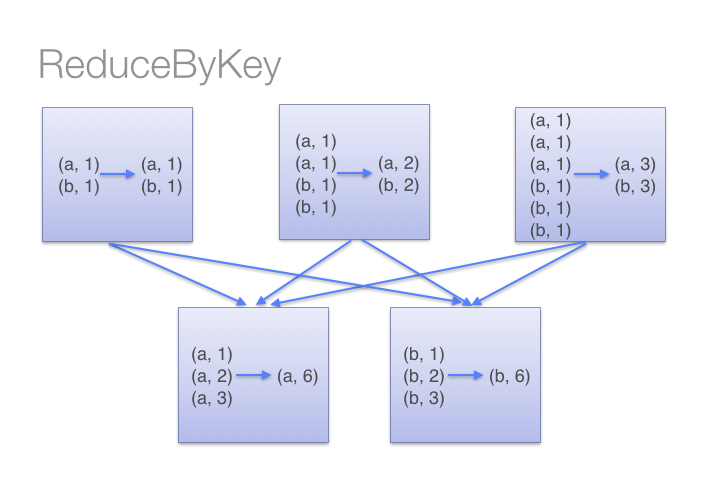
为什么建议尽量在Spark中少用GroupByKey,让我们看一下使用两种不同的方式去计算单词的个数,第一种方式使用 reduceByKey ;另外一种方式使用groupByKey,代码如下:[code lang="scala"]# User: 过往记忆# Date: 2015-05-18# Time: 下午22:26# bolg: # 本文地址:/archives/1357# 过往记忆博客,专注于hadoop、hive、spark、shark、flume的技术博客,大量 w397090770 11年前 (2015-05-18) 33730℃ 0评论51喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 《杭州第三次Spark meetup会议 w397090770 11年前 (2015-05-15) 4884℃ 0评论3喜欢