导读.bordered th, .bordered td{text-align:left;}唯品会离线平台SPARK2.3.2无缝升级到SPARK3.0.1版本,完全做到了对用户透明,目前正按着既定方案进行升级,新的版本SPARK CORE/SQL/PySpark进行了优化和BugFix,并且Merge了SPARK vip 2.3.2 重要Patch,在性能和易用性上比旧版本都有较大提升。这篇文章介绍了我们升级SPARK过程中遇到的挑战和思考, w397090770 4年前 (2021-04-05) 1365℃ 0评论4喜欢
Apache Spark 3.1.1 版本于美国当地时间2021年3月2日正式发布,这个版本继续保持使得 Spark 更快,更容易和更智能的目标,Spark 3.1 的主要目标如下:提升了 Python 的可用性;加强了 ANSI SQL 兼容性;加强了查询优化;Shuffle hash join 性能提升;History Server 支持 structured streaming注意,由于技术上的原因,Apache Spark 没有发布 3.1.0 版 w397090770 4年前 (2021-03-03) 2368℃ 0评论10喜欢
2021年2月1日, Databricks 在其博客宣布将投资10亿美元,以应对其统一数据平台(unified data platform)在全球的快速普及。 本次融资由富兰克林·邓普顿(Franklin Templeton)领投,加拿大养老金计划投资委员会(Canada Pension Plan Investment Board)、富达管理与研究有限责任公司(Fidelity Management & Research LLC)和 Whale Rock(美国的媒体和技术公 w397090770 4年前 (2021-02-02) 660℃ 0评论3喜欢
桔妹导读:在滴滴SQL任务从Hive迁移到Spark后,Spark SQL任务占比提升至85%,任务运行时间节省40%,运行任务需要的计算资源节省21%,内存资源节省49%。在迁移过程中我们沉淀出一套迁移流程, 并且发现并解决了两个引擎在语法,UDF,性能和功能方面的差异。迁移背景Spark自从2010年面世,到2020年已经经过十年的发展,现在已经发展 w397090770 4年前 (2021-01-28) 2634℃ 0评论10喜欢
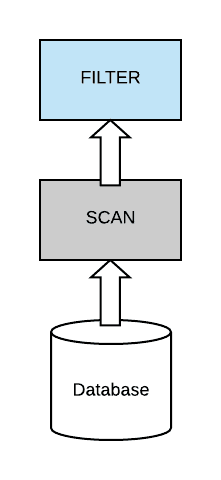
Spark 3.0 为我们带来了许多令人期待的特性。动态分区裁剪(dynamic partition pruning)就是其中之一。本文将通过图文的形式来带大家理解什么是动态分区裁剪。Spark 中的静态分区裁剪在介绍动态分区裁剪之前,有必要对 Spark 中的静态分区裁剪进行介绍。在标准数据库术语中,裁剪意味着优化器将避免读取不包含我们正在查找的数 w397090770 4年前 (2021-01-06) 1346℃ 0评论5喜欢
最近,Delta Lake 发布了一项新功能,也就是支持直接使用 Scala、Java 或者 Python 来查询 Delta Lake 里面的数据,这个是不需要通过 Spark 引擎来实现的。Scala 和 Java 读取 Delta Lake 里面的数据是通过 Delta Standalone Reader 实现的;而 Python 则是通过 Delta Rust API 实现的。Delta Lake 是一个开源存储层,为数据湖带来了可靠性。Delta Lake 提供 ACID 事务 w397090770 4年前 (2021-01-05) 1179℃ 0评论0喜欢
本文来自11月举办的 Data + AI Summit 2020 (原 Spark+AI Summit),主题为《Improving Spark SQL Performance by 30%: How We Optimize Parquet Filter Pushdown and Parquet Reader》的分享,作者为字节跳动的孙科和郭俊。相关 PPT 可以关注 Java与大数据架构 公众号并回复 9912 获取。Parquet 是一种非常流行的列式存储格式。Spark 的算子下推(pushdown filters)可以利用 P w397090770 4年前 (2020-12-14) 2651℃ 2评论4喜欢
本文来自11月举办的 Data + AI Summit 2020 (原 Spark+AI Summit),主题为《Materialized Column- An Efficient Way to Optimize Queries on Nested Columns》的分享,作者为字节跳动的郭俊。本文相关 PPT 可以关注 Java与大数据架构 公众号并回复 9910 获取。在数据仓库领域,使用复杂类型(如map)中的一列或多列,或者将许多子字段放入其中的场景是非常 w397090770 4年前 (2020-12-13) 914℃ 0评论3喜欢
Data + AI Summit Europe 2020 原 Spark + AI Summit Europe 于2020年11月17日至19日举行。由于新冠疫情影响,本次会议和六月份举办的会议一样在线举办,一共为期三天,第一天是培训,第二天和第三天是正式会议。会议涵盖来自从业者的技术内容,他们将使用 Apache Spark™、Delta Lake、MLflow、Structured Streaming、BI和SQL分析、深度学习和机器学习框架来 w397090770 4年前 (2020-12-06) 1205℃ 0评论2喜欢
为了更好的使用 Apache Iceberg,理解其时间旅行是很有必要的,这个其实也会对 Iceberg 表的读取过程有个大致了解。不过在介绍 Apache Iceberg 的时间旅行(Time travel)之前,我们需要了解 Apache Iceberg 的底层数据组织结构。Apache Iceberg 的底层数据组织我们在 《一条数据在 Apache Iceberg 之旅:写过程分析》 这篇文章中详细地介绍了 Apache I w397090770 4年前 (2020-11-29) 3782℃ 0评论4喜欢