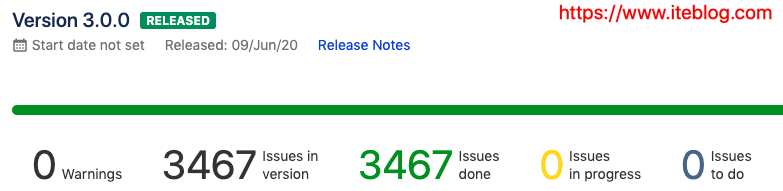
原计划在2019年年底发布的 Apache Spark 3.0.0 今天终于赶在下周二举办的 Spark Summit AI 会议之前正式发布了! Apache Spark 3.0.0 自2018年10月02日开发到目前已经经历了近21个月!这个版本的发布经历了两个预览版以及三次投票:2019年11月06日第一次预览版,参见 https://spark.apache.org/news/spark-3.0.0-preview.html2019年12月23日第二次预览版,参见 https w397090770 5年前 (2020-06-18) 1870℃ 0评论4喜欢
Facebook Spark 的使用情况在介绍下面文章之前我们来看看 Facebook 的 Spark 使用情况:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopSpark 是 Facebook 内部最大的 SQL 查询引擎(按 CPU 使用率计算)在存储计算分 w397090770 5年前 (2020-06-14) 1647℃ 0评论6喜欢
大数据处理技术现今已广泛应用于各个行业,为业务解决海量存储和海量分析的需求。但数据量的爆发式增长,对数据处理能力提出了更大的挑战,同时对时效性也提出了更高的要求。业务通常已不再满足滞后的分析结果,希望看到更实时的数据,从而在第一时间做出判断和决策。典型的场景如电商大促和金融风控等,基于延迟数 w397090770 5年前 (2020-06-08) 3967℃ 0评论3喜欢
多年以来,社区一直在努力改进 Spark SQL 的查询优化器和规划器,以生成高质量的查询执行计划。最大的改进之一是基于成本的优化(CBO,cost-based optimization)框架,该框架收集并利用各种数据统计信息(如行数,不同值的数量,NULL 值,最大/最小值等)来帮助 Spark 选择更好的计划。这些基于成本的优化技术很好的例子就是选择正确 w397090770 5年前 (2020-05-30) 1781℃ 0评论4喜欢
Pandas 用户定义函数(UDF)是 Apache Spark 中用于数据科学的最重要的增强之一,它们带来了许多好处,比如使用户能够使用 Pandas API和提高性能。 但是,随着时间的推移,Pandas UDFs 已经有了一些新的发展,这导致了一些不一致性,并在用户之间造成了混乱。即将推出的 Apache Spark 3.0 完整版将为 Pandas UDF 引入一个新接口,该接口利用 w397090770 5年前 (2020-05-30) 989℃ 0评论1喜欢
NVIDIA (辉达) 于2020年5月15日宣布将与开源社群携手合作,将端到端的 GPU 加速技术导入 Apache Spark 3.0。全球超过五十万名资料科学家使用 Apache Spark 3.0 分析引擎处理大数据资料。透过预计于今年春末正式发表的 Spark 3.0,资料科学家与机器学习工程师将能首次把革命性的 GPU 加速技术应用于 ETL (撷取、转换、载入) 资料处理作业负载 w397090770 5年前 (2020-05-15) 788℃ 0评论2喜欢
物化视图作为一种预计算的优化方式,广泛应用于传统数据库中,如Oracle,MSSQL Server等。随着大数据技术的普及,各类数仓及查询引擎在业务中扮演着越来越重要的数据分析角色,而物化视图作为数据查询的加速器,将极大增强用户在数据分析工作中的使用体验。本文将基于 SparkSQL(2.4.4) + Hive (2.3.6), 介绍物化视图在SparkSQL中 w397090770 5年前 (2020-05-14) 2333℃ 0评论4喜欢
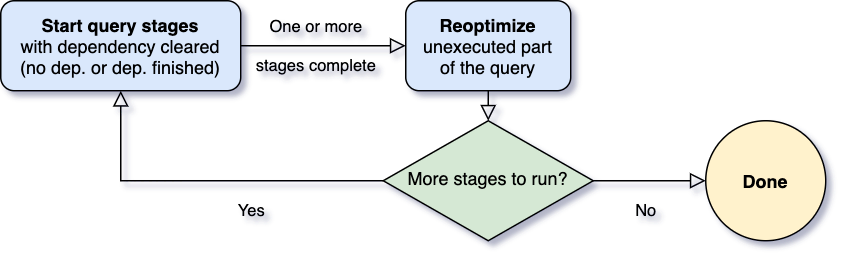
我已经在之前的 《一条 SQL 在 Apache Spark 之旅(上)》、《一条 SQL 在 Apache Spark 之旅(中)》 以及 《一条 SQL 在 Apache Spark 之旅(下)》 这三篇文章中介绍了 SQL 从用户提交到最后执行都经历了哪些过程,感兴趣的同学可以去这三篇文章看看。这篇文章中我们主要来介绍 SQL 查询计划(Query Plan)常见的处理模型(processing model)。数 w397090770 5年前 (2020-05-13) 1827℃ 0评论6喜欢
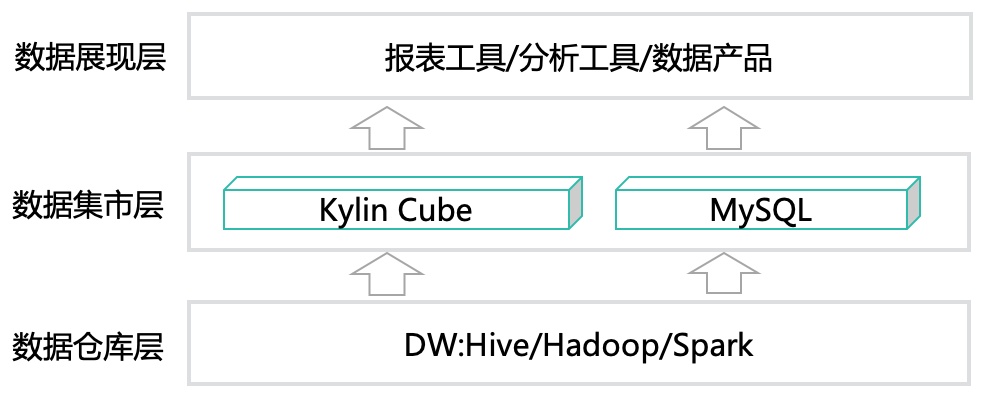
序言美团外卖数据仓库技术团队负责支撑日常业务运营及分析师的日常分析,由于外卖业务特点带来的数据生产成本较高和查询效率偏低的问题,他们通过引入Apache Doris引擎优化生产方案,实现了低成本生产与高效查询的平衡。并以此分析不同业务场景下,基于Kylin的MOLAP模式与基于Doris引擎的ROLAP模式的适用性问题。希望能对大家有 w397090770 5年前 (2020-04-17) 2420℃ 0评论3喜欢
背景相信经常使用 Spark 的同学肯定知道 Spark 支持将作业的 event log 保存到持久化设备。默认这个功能是关闭的,不过我们可以通过 spark.eventLog.enabled 参数来启用这个功能,并且通过 spark.eventLog.dir 参数来指定 event log 保存的地方,可以是本地目录或者 HDFS 上的目录,不过一般我们都会将它设置成 HDFS 上的一个目录。但是这个功能 w397090770 5年前 (2020-03-09) 2428℃ 0评论8喜欢