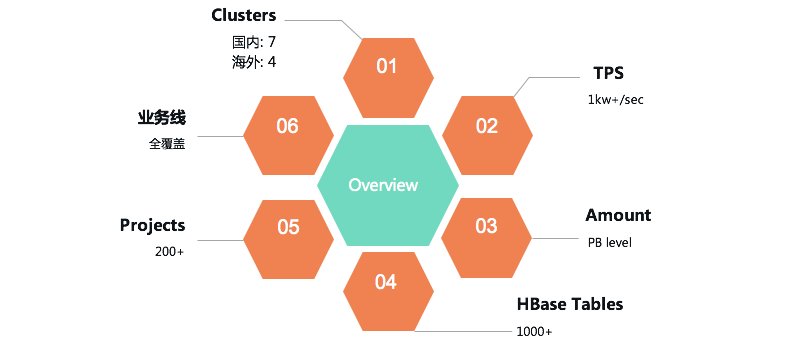
滴滴HBase团队日前完成了0.98版本 -> 1.4.8版本滚动升级,用户无感知。新版本为我们带来了丰富的新特性,在性能、稳定性与易用性方便也均有很大提升。我们将整个升级过程中面临的挑战、进行的思考以及解决的问题总结成文,希望对大家有所帮助。背景目前HBase服务在我司共有国内、海外共计11个集群,总吞吐超过1kw+/s,服务 w397090770 5年前 (2020-06-10) 1612℃ 0评论6喜欢
物化视图作为一种预计算的优化方式,广泛应用于传统数据库中,如Oracle,MSSQL Server等。随着大数据技术的普及,各类数仓及查询引擎在业务中扮演着越来越重要的数据分析角色,而物化视图作为数据查询的加速器,将极大增强用户在数据分析工作中的使用体验。本文将基于 SparkSQL(2.4.4) + Hive (2.3.6), 介绍物化视图在SparkSQL中 w397090770 5年前 (2020-05-14) 2333℃ 0评论4喜欢
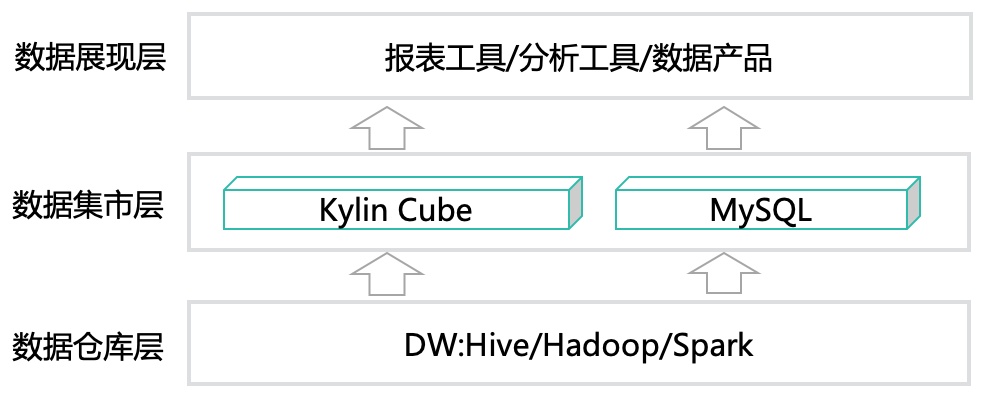
序言美团外卖数据仓库技术团队负责支撑日常业务运营及分析师的日常分析,由于外卖业务特点带来的数据生产成本较高和查询效率偏低的问题,他们通过引入Apache Doris引擎优化生产方案,实现了低成本生产与高效查询的平衡。并以此分析不同业务场景下,基于Kylin的MOLAP模式与基于Doris引擎的ROLAP模式的适用性问题。希望能对大家有 w397090770 5年前 (2020-04-17) 2420℃ 0评论3喜欢
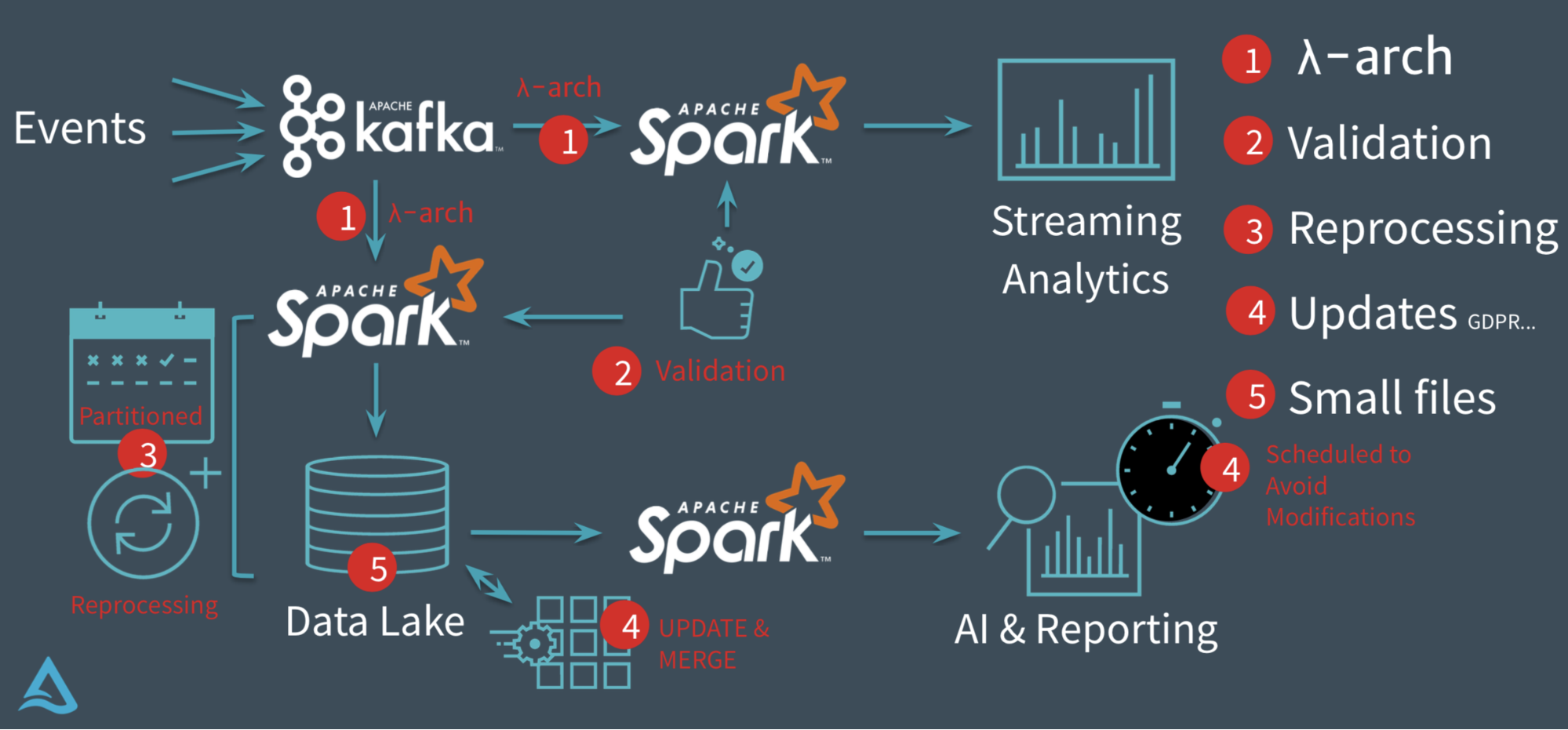
目前市面上流行的三大开源数据湖方案分别为:Delta、Apache Iceberg 和 Apache Hudi。其中,由于 Apache Spark 在商业化上取得巨大成功,所以由其背后商业公司 Databricks 推出的 Delta 也显得格外亮眼。Apache Hudi 是由 Uber 的工程师为满足其内部数据分析的需求而设计的数据湖项目,它提供的 fast upsert/delete 以及 compaction 等功能可以说是精准命中 w397090770 5年前 (2020-03-05) 4032℃ 0评论2喜欢
一、前言随着大数据技术的飞速发展,海量数据存储和计算的解决方案层出不穷,生产环境和大数据环境的交互日益密切。数据仓库作为海量数据落地和扭转的重要载体,承担着数据从生产环境到大数据环境、经由大数据环境计算处理回馈生产应用或支持决策的重要角色。数据仓库的主题覆盖度、性能、易用性、可扩展性及数 w397090770 5年前 (2020-03-01) 2048℃ 0评论7喜欢
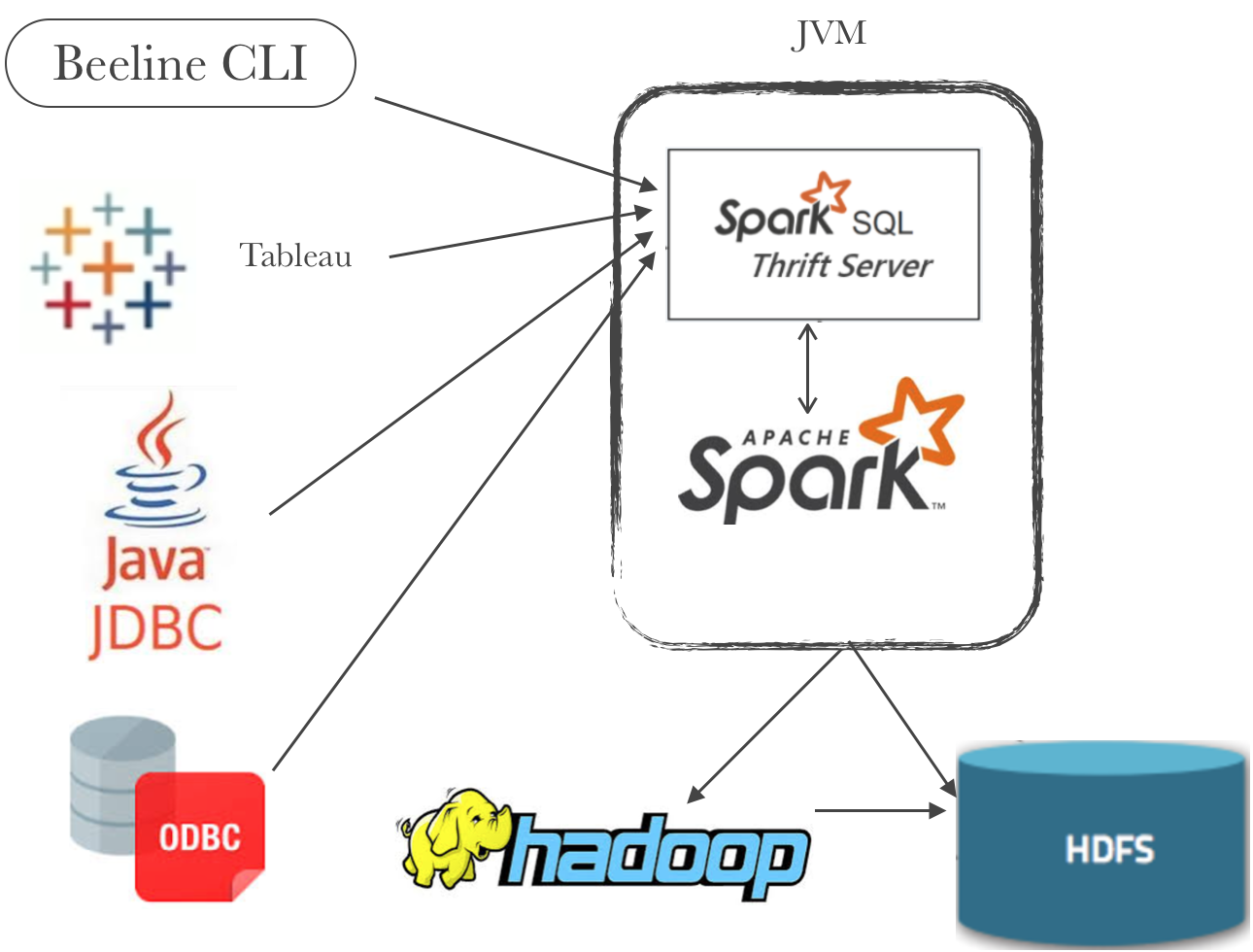
HDFS 简介因为 HDFS 这样一个系统已经存在了非常长的时间,应用的场景已经非常成熟了,所以这部分我们会比较简单地介绍。HDFS 全名 Hadoop Distributed File System,是业界使用最广泛的开源分布式文件系统。原理和架构与 Google 的 GFS 基本一致。它的特点主要有以下几项:和本地文件系统一样的目录树视图Append Only 的写入(不支持 w397090770 5年前 (2020-01-10) 2424℃ 0评论4喜欢
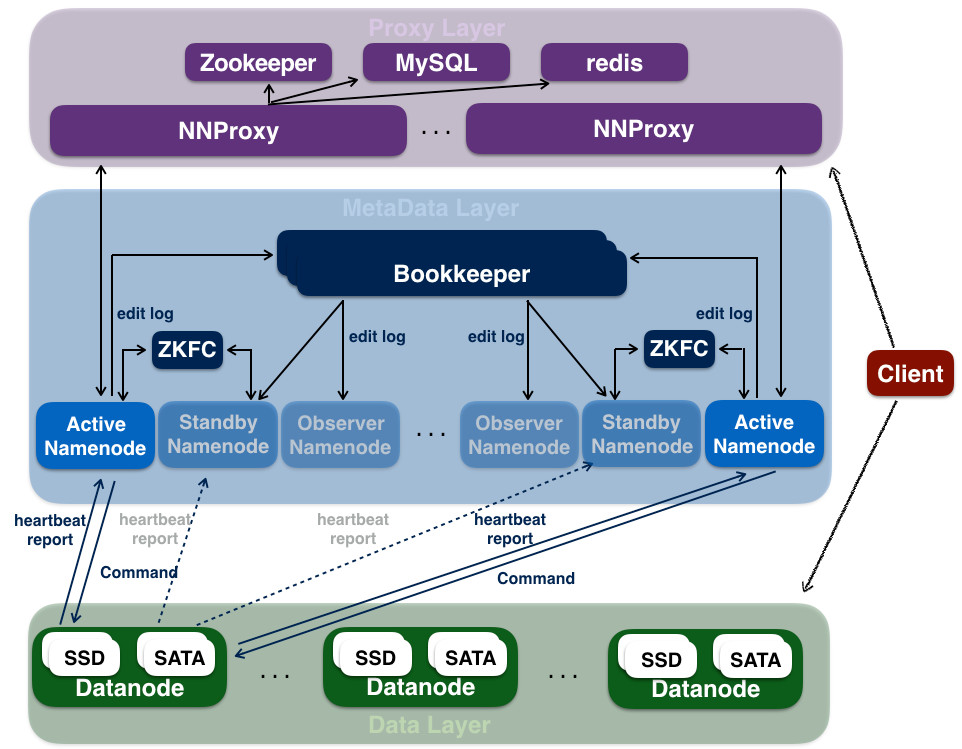
为什么要升级在2017年底, Hadoop3.0 发布了,到目前为止, Hadoop 发布的最新版本为3.2.1。在 Hadoop3 中有很多有用的新特性出现,如支持 ErasureCoding、多 NameNode、Standby NameNode read、DataNode Disk Balance、HDFS RBF 等等。除此之外,还有很多性能优化以及 BUG 修复。其中最吸引我们的就是 ErasureCoding 特性,数据可靠性保持不变的情况下可以降 w397090770 5年前 (2020-01-05) 2623℃ 0评论11喜欢
一、前言在 2019 年 1 月份的时候,我们发表过一篇博客 从 Hive 迁移到 Spark SQL 在有赞的实践,里面讲述我们在 Spark 里所做的一些优化和任务迁移相关的内容。本文会接着上次的话题继续讲一下我们之后在 SparkSQL 上所做的一些改进,以及如何做到 SparkSQL 占比提升到 91% 以上,最后也分享一些在 Spark 踩过的坑和经验希望能帮助到大家 w397090770 5年前 (2020-01-05) 1757℃ 0评论2喜欢
背景随着马蜂窝的逐渐发展,我们的业务数据越来越多,单纯使用 MySQL 已经不能满足我们的数据查询需求,例如对于商品、订单等数据的多维度检索。使用 Elasticsearch 存储业务数据可以很好的解决我们业务中的搜索需求。而数据进行异构存储后,随之而来的就是数据同步的问题。现有方法及问题对于数据同步,我们目前 w397090770 5年前 (2020-01-04) 1218℃ 0评论6喜欢