背景 B站的YARN以社区的2.8.4分支构建,采用CapacityScheduler作为调度器, 期间进行过多次核心功能改造,目前支撑了B站的离线业务、实时业务以及部分AI训练任务。2020年以来,随着B站业务规模的迅速增长,集群总规模达到8k左右,其中单集群规模已经达到4k+ ,日均Application(下文简称App)数量在20w到30w左右。当前最大单集群整体cpu w397090770 3年前 (2022-04-11) 831℃ 0评论2喜欢
以较低的硬件成本扩展我们的数据基础设施,同时保持高性能和服务可靠性并非易事。 为了适应 Uber 数据存储和分析计算的指数级增长,数据基础设施团队通过结合硬件重新设计软件层,以扩展 Apache Hadoop® HDFS :HDFS Federation、Warm Storage、YARN 在 HDFS 数据节点上共存,以及 YARN 利用率的提高提高了系统的 CPU 和内存使用效率将多 w397090770 3年前 (2021-10-21) 469℃ 0评论3喜欢
在 LinkedIn,我们使用 Hadoop 作为大数据分析和机器学习的基础组件。随着数据量呈指数级增长,并且公司在机器学习和数据科学方面进行了大量投资,我们的集群规模每年都在翻倍,以匹配计算工作负载的增长。我们最大的集群现在有大约 10,000 个节点,是全球最大(如果不是最大的)Hadoop 集群之一。多年来,扩展 Hadoop YARN 已成为 w397090770 3年前 (2021-09-18) 565℃ 0评论4喜欢
本文来自 2019年9月23日至26日在纽约举办的 Strata Data Conference,分享者是来自 Cloudera 的 Wangda Tan 和 Wei-Chiu Chuang,会议页面 https://conferences.oreilly.com/strata/strata-ny-2019/public/schedule/detail/77506。请关注 过往记忆大数据 微信公众号,并在后台回复 hadoop_3 关键字获取本文的 PPT 下载地址。如果想及时了解Spark、Hadoop或者HBase相关的文章, w397090770 5年前 (2020-02-04) 2421℃ 2评论5喜欢
为了让大家更好地学习交流,过往记忆大数据花了一个周末的时间把 Awesome Big Data 里近 600 个大数据相关的调度、存储、计算、数据库以及可视化等介绍全部翻译了一遍,供大家学习交流。关系型数据库管理系统MySQL 世界上最流行的开源数据库。PostgreSQL 世界上最先进的开源数据库。Oracle Database - 对象关系数据库管理系统。T w397090770 5年前 (2019-09-23) 12544℃ 0评论34喜欢
2019 年 7 月 17 日,Cloudera 官方博客发文开源了一个内部研发使用很久的大数据存储和通用计算平台交叉的新项目 YuniKorn。Yunikorn 是一个新的独立通用资源调度程序,负责为大数据工作负载分配/管理资源,包括批处理作业和长时间运行的服务。介绍YuniKorn 是一种轻量级的通用资源调度程序,适用于容器编排系统(container orchestrator s w397090770 6年前 (2019-07-17) 3775℃ 0评论0喜欢
每个 NodeManager 节点内置提供了检测自身健康状态的机制(详情参见 NodeHealthCheckerService);通过这种机制,NodeManager 会将诊断出来的监控状态通过心跳机制汇报给 ResourceManager,然后ResourceManager 端会通过 RMNodeEventType.STATUS_UPDATE 更新 NodeManager 的状态;如果此时的 NodeManager 节点不健康,那么 ResourceManager 将会把 NodeManager 状态变为 NodeState w397090770 8年前 (2017-06-08) 4287℃ 0评论18喜欢
ResourceManager 内维护了 NodeManager 的生命周期;对于每个 NodeManager 在 ResourceManager 中都有一个 RMNode 与其对应;除了 RMNode ,ResourceManager 中还定义了 NodeManager 的状态(states)以及触发状态转移的事件(event)。具体如下:org.apache.hadoop.yarn.server.resourcemanager.rmnode.RMNode:这是一个接口,每个 NodeManager 都与 RMNode 对应,这个接口主要维 w397090770 8年前 (2017-06-07) 3615℃ 0评论21喜欢
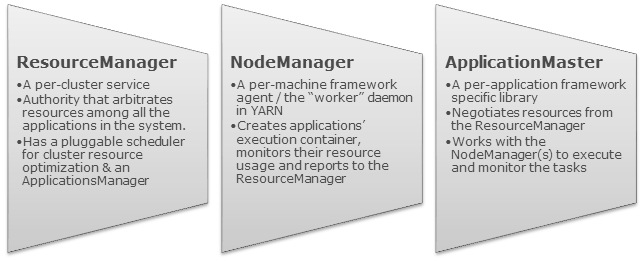
Apache YARN是将之前Hadoop 1.x的 JobTracker 功能分别拆到不同的组件里面了,每个组件分别负责不同的功能。在Hadoop 1.x中, JobTracker 负责管理集群的资源,作业调度以及作业监控;YARN把这些功能分别拆到ResourceManager 和 ApplicationMaster 中了。而之前的TaskTracker被NodeManager替代。下面分别介绍YAEN的各个组件的作用。如果想及时了解Spark、Had w397090770 8年前 (2017-06-01) 4038℃ 0评论31喜欢
如果你经常写MapReduce作业,你肯定看到过以下的异常信息:[code lang="bash"]Application application_1409135750325_48141 failed 2 times due to AM Container forappattempt_1409135750325_48141_000002 exited with exitCode: 143 due to: Container[pid=4733,containerID=container_1409135750325_48141_02_000001] is running beyond physical memory limits.Current usage: 2.0 GB of 2 GB physical memory used; 6.0 GB of w397090770 8年前 (2016-12-29) 4255℃ 1评论11喜欢