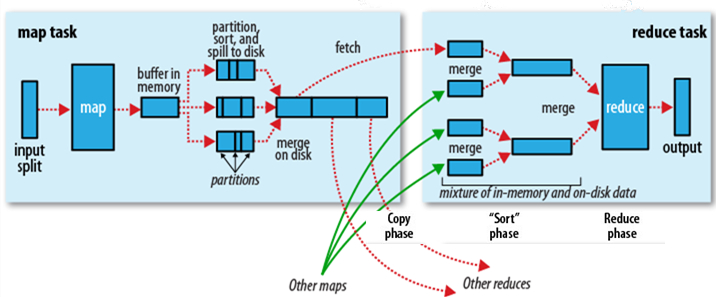
Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方。要想理解MapReduce, Shuffle是必须要了解的。我看过很多相关的资料,但每次看完都云里雾里的绕着,很难理清大致的逻辑,反而越搅越混。前段时间在做MapReduce job 性能调优的工作,需要深入代码研究MapReduce的运行机制,这才对Shuffle探了个究竟。考虑到之前我在看相关资料 w397090770 11年前 (2014-09-15) 16442℃ 7评论59喜欢
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop 今天我很激动地宣布Spark 1.1.0发布了,Spark 1.1.0引入了许多新特征(new features)包括了可扩展性和稳定性方面的提升。这篇文章主要是介绍了Spark 1.1.0主要的特性,下面的介绍主要是根据各个特征重要性的优先级进行说明的。在接下来的两个星 w397090770 11年前 (2014-09-12) 4705℃ 2评论8喜欢
我们期待已久的Spark 1.1.0在美国时间的9月11日正式发布了,官方发布的声明如下:We are happy to announce the availability of Spark 1.1.0! Spark 1.1.0 is the second release on the API-compatible 1.X line. It is Spark’s largest release ever, with contributions from 171 developers!This release brings operational and performance improvements in Spark core including a new implementation of the Spark w397090770 11年前 (2014-09-12) 3817℃ 0评论2喜欢
Spark SQL也是可以直接部署在当前的Hive wareHouse。 Spark SQL 1.1.0的 Thrift JDBC server 被设计成兼容当前的Hive数据仓库。你不需要修改你的Hive元数据,或者是改变表的数据存放目录以及分区。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop 以下列出来的是当前Spark SQL(1.1.0)对Hive特性的 w397090770 11年前 (2014-09-11) 9463℃ 1评论8喜欢
Spark 1.1.0马上就要发布了(估计就是明天),其中更新了很多功能。其中对Spark SQL进行了增强: 1、Spark 1.0是第一个预览版本( 1.0 was the first “preview” release); 2、Spark 1.1 将支持Shark更新(1.1 provides upgrade path for Shark), (1)、Replaced Shark in our benchmarks with 2-3X perfgains; (2)、Can perform optimizations with 10- w397090770 11年前 (2014-09-11) 7800℃ 2评论5喜欢
如果你需要将RDD写入到Mysql等关系型数据库,请参见《Spark RDD写入RMDB(Mysql)方法二》和《Spark将计算结果写入到Mysql中》文章。 Spark的功能是非常强大,在本博客的文章中,我们讨论了《Spark和Hbase整合》、《Spark和Flume-ng整合》以及《和Hive的整合》。今天我们的主题是聊聊Spark和Mysql的组合开发。如果想及时了解Spark、Had w397090770 11年前 (2014-09-10) 38804℃ 7评论32喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》如果想及时了解Spark、Hadoop或 w397090770 11年前 (2014-09-08) 18464℃ 177评论16喜欢
本文详细地介绍了如何将Hadoop上的Mapreduce程序转换成Spark的应用程序。有兴趣的可以参考一下:The key to getting the most out of Spark is to understand the differences between its RDD API and the original Mapper and Reducer API.Venerable MapReduce has been Apache Hadoop‘s work-horse computation paradigm since its inception. It is ideal for the kinds of work for which Hadoop was originally des w397090770 11年前 (2014-09-07) 6462℃ 1评论9喜欢
我们知道,Flume可以和许多的系统进行整合,包括了Hadoop、Spark、Kafka、Hbase等等;当然,强悍的Flume也是可以和Mysql进行整合,将分析好的日志存储到Mysql(当然,你也可以存放到pg、oracle等等关系型数据库)。 不过我这里想多说一些:Flume是分布式收集日志的系统;既然都分布式了,数据量应该很大,为什么你要将Flume分 w397090770 11年前 (2014-09-04) 25750℃ 21评论40喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 8月31日(13:30-17:30),杭州第 w397090770 11年前 (2014-09-01) 26732℃ 230评论17喜欢