来自于requests的灵感,因为它很简单;并且由lxml驱动,因为它速度很快。 Newspaper是一个惊人的新闻、全文以及文章元数据抽取开源的Python类库,这个类库支持10多种语言,所有的东西都是用unicode编码的。我们可以使用下面命令查看:[code lang="python"]/** * User: 过往记忆 * Date: 2015-05-20 * Time: 下午23:14 * bolg: * 本文地 w397090770 10年前 (2015-05-20) 2804℃ 0评论0喜欢
spark.cleaner.ttl参数的原意是清除超过这个时间的所有RDD数据,以便腾出空间给后来的RDD使用。周期性清除保证在这个时间之前的元数据会被遗忘,对于那些运行了几小时或者几天的Spark作业(特别是Spark Streaming)设置这个是很有用的。注意:任何内存中的RDD只要过了这个时间就会被清除掉。官方文档是这么介绍的:Duration (secon w397090770 10年前 (2015-05-20) 8186℃ 0评论7喜欢
Apache Hive 1.2.0于美国时间2015年05月18日正式发布,其中修复了大量大Bug,完整邮件内容如下:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopThe Apache Hive team is proud to announce the the release of Apache Hive version 1.2.0.The Apache Hive (TM) data warehouse software facilitates querying and managing large datasets residin w397090770 10年前 (2015-05-19) 5444℃ 0评论4喜欢
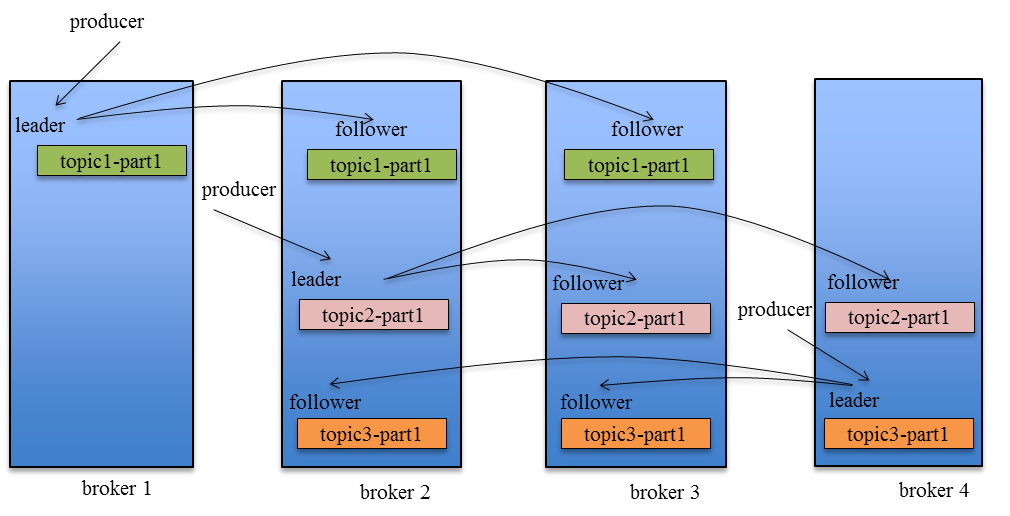
《Kafka剖析:Kafka背景及架构介绍》《Kafka设计解析:Kafka High Availability(上)》《Kafka设计解析:Kafka High Availability (下)》《Kafka设计解析:Replication工具》《Kafka设计解析:Kafka Consumer解析》 Kafka在0.8以前的版本中,并不提供High Availablity机制,一旦一个或多个Broker宕机,则宕机期间其上所有Partition都无法继续提供服 w397090770 10年前 (2015-05-19) 5440℃ 0评论3喜欢
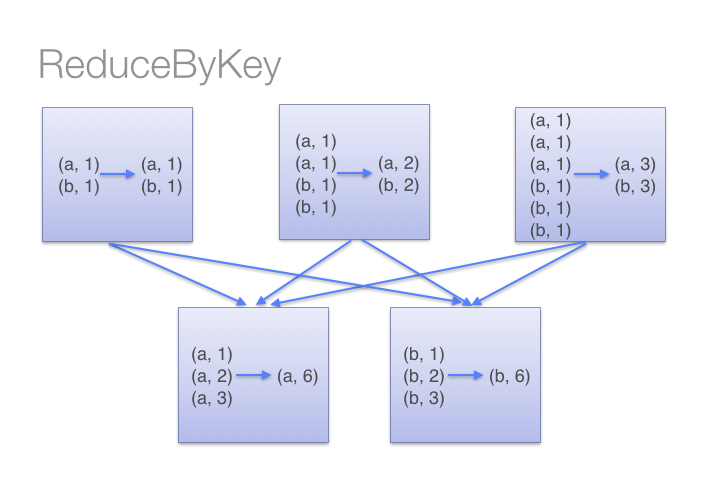
为什么建议尽量在Spark中少用GroupByKey,让我们看一下使用两种不同的方式去计算单词的个数,第一种方式使用 reduceByKey ;另外一种方式使用groupByKey,代码如下:[code lang="scala"]# User: 过往记忆# Date: 2015-05-18# Time: 下午22:26# bolg: # 本文地址:/archives/1357# 过往记忆博客,专注于hadoop、hive、spark、shark、flume的技术博客,大量 w397090770 10年前 (2015-05-18) 33636℃ 0评论51喜欢
下面IP由于地区不同可能无法访问,请多试几个。国内高匿代理 IP PORT 匿名度 类型 位置 响应速度 最后验证时间 112.19.121.141 8123 高匿名 HTTP w397090770 10年前 (2015-05-15) 23834℃ 0评论6喜欢
下面IP由于地区不同可能无法访问,请多试几个。国内高匿代理 IP PORT 匿名度 类型 位置 响应速度 最后验证时间 122.246.148.77 8090 高匿名 HTTP 浙 w397090770 10年前 (2015-05-15) 41166℃ 0评论0喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 《杭州第三次Spark meetup会议 w397090770 10年前 (2015-05-15) 4831℃ 0评论3喜欢
如果你想知道Hadoop作业运行日志,可以查看这里《Hadoop日志存放路径详解》 在很多情况下,我们需要查看driver和executors在运行Spark应用程序时候产生的日志,这些日志对于我们调试和查找问题是很重要的。 Spark日志确切的存放路径和部署模式相关: (1)、如果是Spark Standalone模式,我们可以直接在Master UI界 w397090770 10年前 (2015-05-14) 39801℃ 6评论16喜欢
下面IP由于地区不同可能无法访问,请多试几个。国内高匿代理 IP PORT 匿名度 类型 位置 响应速度 最后验证时间 125.117.130.174 9000 高匿名 HTTP w397090770 10年前 (2015-05-13) 46418℃ 0评论0喜欢