在高德纳的计算机程序设计艺术中,有如下问题:可否在一未知大小的集合中,随机取出一元素?。或者是Google面试题: I have a linked list of numbers of length N. N is very large and I don’t know in advance the exact value of N. How can I most efficiently write a function that will return k completely random numbers from the list(中文简化的意思就是:在不知道文件总行 w397090770 10年前 (2015-11-09) 10402℃ 0评论16喜欢
为了提高本博客的用户体验,我于去年七月写了一份代码,将博客与微信公共帐号关联起来(可以参见本博客),用户可以在里面输入相关的关键字(比如new、rand、hot),但是那时候关键字有限制,只能对文章的分类进行搜索。不过,今天我修改了自动回复功能相关代码,目前支持对任意的关键字进行全文搜索,其结果相关与调用 w397090770 10年前 (2015-11-07) 2121℃ 0评论8喜欢
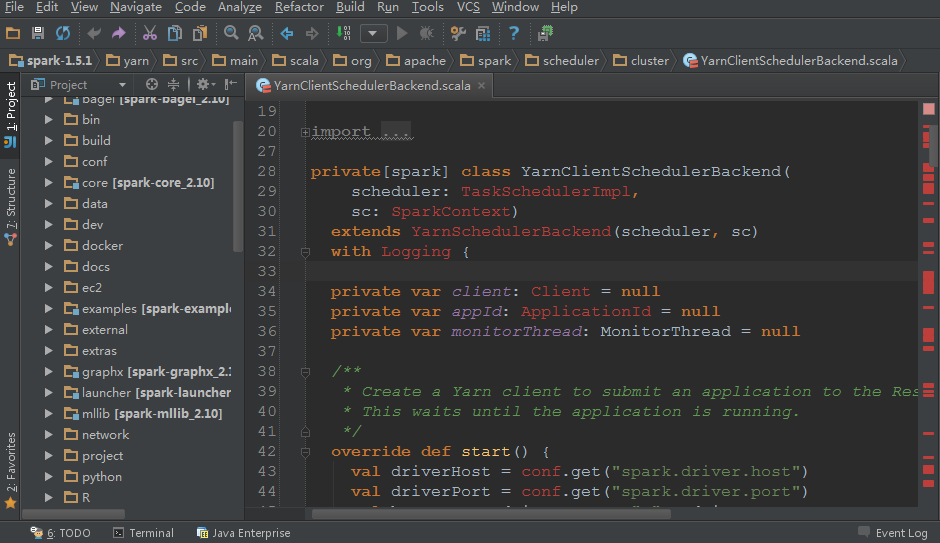
我们在学习或者使用Spark的时候都会选择下载Spark的源码包来加强Spark的学习。但是在导入Spark代码的时候,我们会发现yarn模块的相关代码总是有相关类依赖找不到的错误(如下图),而且搜索(快捷键Ctrl+N)里面的类时会搜索不到!这给我们带来了很多不遍。。 本文就是来解决这个问题的。我使用的是Idea IDE工具阅读代 w397090770 10年前 (2015-11-07) 9161℃ 4评论11喜欢
新世纪以来,互联网及个人终端的普及,传统行业的信息化及物联网的发展等产业变化产生了大量的数据,远远超出了单台机器能够处理的范围,分布式存储与处理成为唯一的选项。从2005年开始,Hadoop从最初Nutch项目的一部分,逐步发展成为目前最流行的大数据处理平台。Hadoop生态圈的各个项目,围绕着大数据的存储,计算, w397090770 10年前 (2015-11-06) 7984℃ 0评论9喜欢