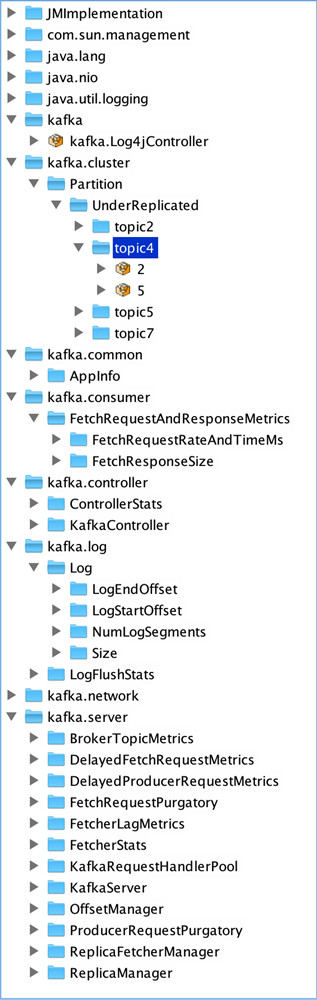
摘要 本文主要介绍了如何利用Kafka自带的性能测试脚本及Kafka Manager测试Kafka的性能,以及如何使用Kafka Manager监控Kafka的工作状态,最后给出了Kafka的性能测试报告。性能测试及集群监控工具 Kafka提供了非常多有用的工具,如Kafka设计解析(三)- Kafka High Availability (下)中提到的运维类工具——Partition Reassign Tool,Prefe w397090770 9年前 (2015-12-31) 4478℃ 1评论6喜欢
目前Spark支持四种方式从数据库中读取数据,这里以Mysql为例进行介绍。一、不指定查询条件 这个方式链接MySql的函数原型是:[code lang="scala"]def jdbc(url: String, table: String, properties: Properties): DataFrame[/code] 我们只需要提供Driver的url,需要查询的表名,以及连接表相关属性properties。下面是具体例子:[code lang="scala" w397090770 9年前 (2015-12-28) 37807℃ 1评论61喜欢
bsie是使得IE6可以支持Bootstrap的补丁,Bootstrap是 twitter.com 推出的非常棒web UI工具库。目前,bsie使得IE6能支持bootstrap大部分特性,可惜,还有一些实在无法支持...下面的这个表格就是当前已经被支持的bootstrap的组件和特性:[code lang="bash"]组件 特性-----------------------------------------------------------grid fixed, fluidnavbar w397090770 9年前 (2015-12-26) 2326℃ 7评论3喜欢
Finatra Finatra是一款基于TwitterServer和Finagle的快速、可测试的Scala异步框架。Finatra is a fast, testable, Scala services built on TwitterServer and Finagle.Play Play是一款轻量级、无状态的WEB友好框架。使用Java和Scala可以很方便地创建web应用程序。Play is based on a lightweight, stateless, web-friendly architecture.Play Framework makes it easy to build web application w397090770 9年前 (2015-12-25) 12598℃ 0评论15喜欢
SBT默认的日志级别是Info,我们可以根据自己的需要去设置它的默认日志级别,比如我们在开发过程中,就可以打开Debug日志级别,这样可以看出SBT是如何工作的。SBT的日志级别在sbt.Level类里面定义:[code lang="scala"]object Level extends Enumeration{ val Debug = Value(1, "debug") val Info = Value(2, "info") val Warn = Value(3, "warn&q w397090770 9年前 (2015-12-24) 3464℃ 0评论8喜欢
《Spark RDD缓存代码分析》 《Spark Task序列化代码分析》 《Spark分区器HashPartitioner和RangePartitioner代码详解》 《Spark Checkpoint读操作代码分析》 《Spark Checkpoint写操作代码分析》 上次介绍了RDD的Checkpint写过程(《Spark Checkpoint写操作代码分析》),本文将介绍RDD如何读取已经Checkpint的数据。在RDD Checkpint w397090770 9年前 (2015-12-23) 6414℃ 0评论10喜欢
2015年中国大数据技术大会已经圆满落幕,本届大会历时三天(2015-12-10~2015-12-12),以更加国际化的视野,从政策法规、技术实践和产业应用等角度深入探讨大数据落地后的挑战,作为大数据产业界、科技界与政府部门密切合作的重要平台,吸引了数千名大数据技术爱好者到场参会。 本届大会邀请了近百余位国内外顶尖的 w397090770 9年前 (2015-12-18) 5536℃ 0评论11喜欢
和Java一样,我们也可以使用Scala来创建Web工程,这里使用的是Scalatra,它是一款轻量级的Scala web框架,和Ruby Sinatra功能类似。比较推荐的创建Scalatra工程是使用Giter8,他是一款很不错的用于创建SBT工程的工具。所以我们需要在电脑上面安装好Giter8。这里以Centos系统为例进行介绍。安装giter8 在安装giter8之前需要安装Conscrip w397090770 9年前 (2015-12-18) 5808℃ 0评论10喜欢
本博客前两篇文章介绍了如何在脚本中使用Scala(《在脚本中运行Scala》、《在脚本中使用Scala的高级特性》),我们可以在脚本里面使用Scala强大的语法,但细心的同学可能会发现每次运行脚本的时候会花上一大部分时间,然后才会有结果。我们来测试下面简单的Scala脚本:[code lang="shell"]#!/bin/shexec scala "$0" "$@" w397090770 9年前 (2015-12-17) 4751℃ 0评论8喜欢
第二期上海大数据流处理(Shanghai Big Data Streaming 2nd Meetup)于2015年12月6日下午12:45在上海世贸大厦22层英特尔(中国)有限公司延安西路2299号进行,分享的主题如下:一、演讲者1/Speaker 1: 张天伦 英特尔大数据组软件工程师 个人介绍/BIO: 英特尔开源流处理系统Gearpump开发者,长期关注大数据领域和分布式计算,专注于流处理 w397090770 9年前 (2015-12-16) 3678℃ 0评论5喜欢