如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop在使用Git的时候,比如push操作,需要我们输入用户名和密码,如下:[code lang="bash"]D:\iteblog\spark>git push origin initUsername for 'http://gitlab.iteblog.com': iteblogPassword for 'http://iteblog@gitlab.iteblog.com':[/code]如果频繁地进行push等需要输入用户名和密码 w397090770 9年前 (2016-02-29) 2839℃ 0评论4喜欢
Spark Summit East 2016:视频,PPT Spark Summit East 2016会议于2016年2月16日至2月18日在美国纽约进行。总体来说,Spark Summit一年比一年火,单看纽约的峰会中,规模已从900人增加到500个公司的1300人,更吸引到更多大型公司的分享,包括Bloomberg、Capital One、Novartis、Comcast等公司。而在这次会议上,Databricks还发布了两款产品——Commu w397090770 9年前 (2016-02-27) 5677℃ 0评论14喜欢
Spark Summit East 2016:视频,PPT Spark Summit East 2016会议于2016年2月16日至2月18日在美国纽约进行。总体来说,Spark Summit一年比一年火,单看纽约的峰会中,规模已从900人增加到500个公司的1300人,更吸引到更多大型公司的分享,包括Bloomberg、Capital One、Novartis、Comcast等公司。而在这次会议上,Databricks还发布了两款产品——Commu w397090770 9年前 (2016-02-27) 6186℃ 0评论9喜欢
这篇文章中将介绍C# 6.0的一个新特性,这将加深我们对Scala monad的理解。Null-conditional操作符 假如我们有一个嵌套的数据类型,然后我们需要访问这个嵌套类型里面的某个属性。比如Article可以没有作者(Author)信息;Author可以没有Address信息;Address可以没有City信息,如下:[code lang="csharp"]//////////////////////////////////// w397090770 9年前 (2016-02-24) 2149℃ 0评论6喜欢
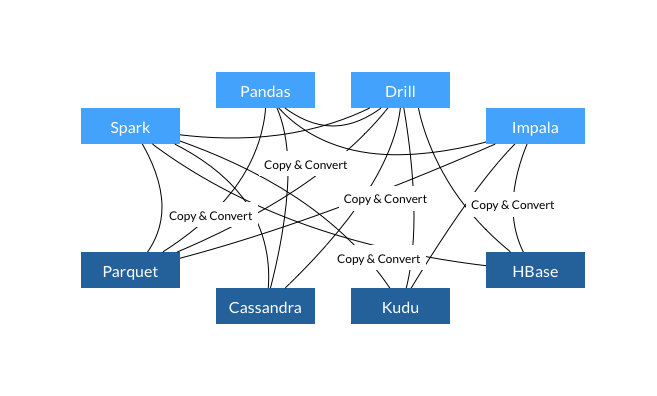
Apache Arrow项目为列式内存存储的处理和交互提供了规范。目前来自Apache Hadoop社区的开发者们致力于将它制定为大数据系统项目的事实性标准。 Apache Arrow主要有以下几点的优势: 1、列式的内存布局可以使得随机访问的速度达到O(1)。这种内存布局在处理分析流和允许SIMD(Single input multiple data) 优化的现代处理器上非常 w397090770 9年前 (2016-02-22) 6300℃ 0评论6喜欢
如何下载整个网站用来离线浏览?怎样将一个网站上的所有 MP3 文件保存到本地的一个目录中?怎么才能将需要登陆的网页后面的文件下载下来?怎样构建一个迷你版的Google?wget 是一个自由的工具,可在包括 Mac,Window 和 Linux 在内的多个平台上使用,它可帮助你实现所有上述任务,而且还有更多的功能。与大多数下载管理器不同 w397090770 9年前 (2016-02-19) 1800℃ 0评论1喜欢
《Apache Kafka编程入门指南:Producer篇》 《Apache Kafka编程入门指南:设置分区数和复制因子》 Apache Kafka编程入门指南:Consumer篇 在前面的例子(《Apache Kafka编程入门指南:Producer篇》)中,我们学习了如何编写简单的Kafka Producer程序。在那个例子中,在如果需要发送的topic不存在,Producer将会创建它。我们都知 w397090770 9年前 (2016-02-06) 7602℃ 0评论6喜欢
《Apache Kafka编程入门指南:Producer篇》 《Apache Kafka编程入门指南:设置分区数和复制因子》 Apache Kafka编程入门指南:Consumer篇 Kafka最初由Linkedin公司开发的分布式、分区的、多副本的、多订阅者的消息系统。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。kafka对消息保存 w397090770 9年前 (2016-02-05) 10272℃ 1评论12喜欢
Apache Zeppelin使用入门指南:安装Apache Zeppelin使用入门指南:编程Apache Zeppelin使用入门指南:添加外部依赖 在前面的两篇文章中我们介绍了如何编译和部署Apache Zeppelin、如何使用Apache Zeppelin。这篇文章中将介绍如何将外部依赖库加入到Apache Zeppelin中。 在现实情况下,我们编写程序一般都是需要依赖外部的相关类库 w397090770 9年前 (2016-02-04) 8182℃ 0评论7喜欢
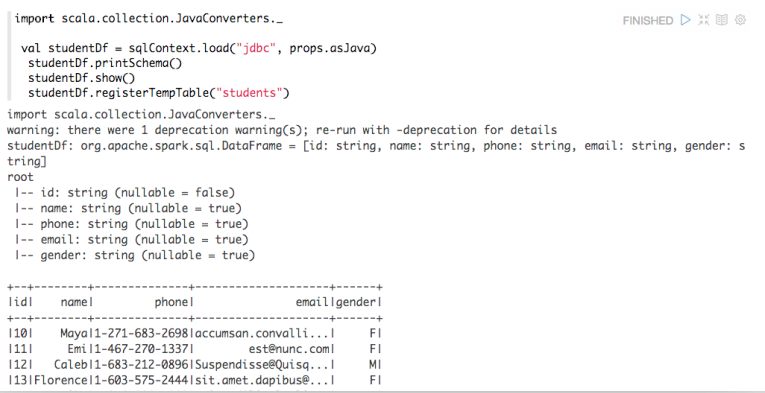
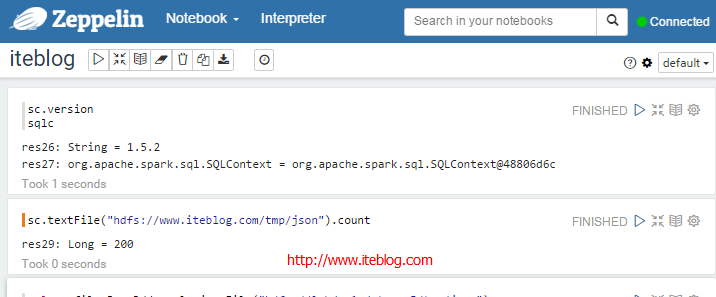
Apache Zeppelin使用入门指南:安装Apache Zeppelin使用入门指南:编程Apache Zeppelin使用入门指南:添加外部依赖使用Apache Zeppelin 编译和启动完Zeppelin相关的进程之后,我们就可以来使用Zeppelin了。我们进入到https://www.iteblog.com:8080页面,我们可以在页面上直接操作Zeppelin,依次选择Notebook->Create new note,然后会弹出一个对话框 w397090770 9年前 (2016-02-03) 25317℃ 2评论31喜欢

![Spark Summit East 2016 PPT免费下载[共65个]](https://www.iteblog.com/wp-content/themes/yusi2.0/img/pic/5.jpg)