在Linux文件系统中,我们可以使用下面的Shell脚本判断某个文件是否存在:[code lang="bash"]# 这里的-f参数判断$file是否存在 if [ ! -f "$file" ]; then echo "文件不存在!"fi [/code]但是我们想判断HDFS上某个文件是否存在咋办呢?别急,Hadoop内置提供了判断某个文件是否存在的命令:[code lang="bash"][iteblog@www.it w397090770 9年前 (2016-03-21) 10825℃ 0评论19喜欢
Hadoop分布式文件系统实现了一个和POSIX系统类似的文件和目录的权限模型。每个文件和目录有一个所有者(owner)和一个组(group)。文件或目录对其所有者、同组的其他用户以及所有其他用户分别有着不同的权限。对文件而言,当读取这个文件时需要有r权限,当写入或者追加到文件时需要有w权限。对目录而言,当列出目录内容 w397090770 9年前 (2016-03-21) 8000℃ 9喜欢
Kafka内部提供了许多管理脚本,这些脚本都放在$KAFKA_HOME/bin目录下,而这些类的实现都是放在源码的kafka/core/src/main/scala/kafka/tools/路径下。Consumer Offset Checker Consumer Offset Checker主要是运行kafka.tools.ConsumerOffsetChecker类,对应的脚本是kafka-consumer-offset-checker.sh,会显示出Consumer的Group、Topic、分区ID、分区对应已经消费的Offset、 w397090770 9年前 (2016-03-18) 16194℃ 0评论13喜欢
《ScalikeJDBC:基于SQL的简洁DB访问类库》文章中已经介绍了ScalikeJDBC到底是个什么东西。本文将介绍ScalikeJDBC的常用操作(Operations)API。查询API ScalikeJDBC中有多种查询API,包括single, first, list 和foreach,他们内部都是调用java.sql.PreparedStatement#executeQuery()实现的。下面将分别介绍如何使用这个API。single查询 single w397090770 9年前 (2016-03-16) 4483℃ 0评论8喜欢
Balloon.css文件允许用户给元素添加提示,而这些在Balloon.css中完全是由CSS来实现,不需要使用JavaScript。 button { display: inline-block; min-width: 160px; text-align: center; color: #fff; background: #ff3d2e; padding: 0.8rem 2rem; font-size: 1.2rem; margin-top: 1rem; border: none; border-radius: 5px; transition: background 0.1s linear;}.butt w397090770 9年前 (2016-03-15) 2558℃ 3评论10喜欢
Spark北京Meetup第十次活动将于北京时间2016年03月27日在北京市海淀区丹棱街5号微软亚太研发集团总部大厦1号楼进行。会议主题1. Spark in TalkingData 阎志涛 TalkingData研发副总裁2. Spark in GrowingIO 田毅 GrowingIO数据平台工程师 主要分享GrowingIO使用Spark进行数据处理过程中的各种小技巧 w397090770 9年前 (2016-03-14) 2433℃ 0评论6喜欢
Spark 1.6.1于2016年3月11日正式发布,此版本主要是维护版本,主要涉及稳定性修复,并不涉及到大的修改。推荐所有使用1.6.0的用户升级到此版本。 Spark 1.6.1主要修复的bug包括: 1、当写入数据到含有大量分区表时出现的OOM:SPARK-12546 2、实验性Dataset API的许多bug修复:SPARK-12478, SPARK-12696, SPARK-13101, SPARK-12932 w397090770 9年前 (2016-03-11) 3974℃ 0评论5喜欢
ScalikeJDBC是一款给Scala开发者使用的简洁DB访问类库,它是基于SQL的,使用者只需要关注SQL逻辑的编写,所有的数据库操作都交给ScalikeJDBC。这个类库内置包含了JDBC API,并且给用户提供了简单易用并且非常灵活的API。并且,QueryDSL使你的代码类型安全的并且可重复使用。我们可以在生产环境大胆地使用这款DB访问类库。工作 w397090770 9年前 (2016-03-10) 4325℃ 0评论4喜欢
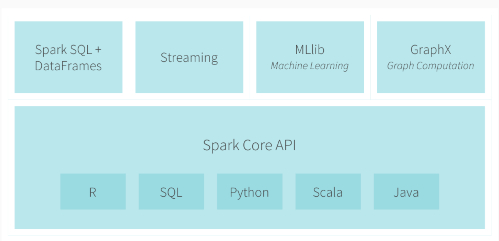
现在Apache Spark已形成一个丰富的生态系统,包括官方的和第三方开发的组件或工具。后面主要给出5个使用广泛的第三方项目。Spark官方构建了一个非常紧凑的生态系统组件,提供各种处理能力。 下面是Spark官方给出的生态系统组件 1、Spark DataFrames:列式存储的分布式数据组织,类似于关系型数据表。 2、Spark SQL:可 w397090770 9年前 (2016-03-08) 4955℃ 2评论7喜欢
XML(可扩展标记语言,英语:eXtensible Markup Language,简称: XML)是一种标记语言,也是行业标准数据交换交换格式,它很适合在系统之间进行数据存储和交换(话说Hadoop、Hive等的配置文件就是XML格式的)。本文将介绍如何使用MapReduce来读取XML文件。但是Hadoop内部是无法直接解析XML文件;而且XML格式中没有同步标记,所以并行地处 w397090770 9年前 (2016-03-07) 5886℃ 1评论7喜欢