Thrift 最初由Facebook开发,目前已经开源到Apache,已广泛应用于业界。Thrift 正如其官方主页介绍的,“是一种可扩展、跨语言的服务开发框架”。简而言之,它主要用于各个服务之间的RPC通信,其服务端和客户端可以用不同的语言来开发。只需要依照IDL(Interface Description Language)定义一次接口,Thrift工具就能自动生成 C++, Java, Python, PH w397090770 9年前 (2016-06-30) 3762℃ 0评论7喜欢
我们在使用Hive查询数据的时候经常会看到如下的输出:[code lang="java"]Query ID = iteblog_20160704104520_988f81d4-0b82-4778-af98-43cc1950d357Total jobs = 1Launching Job 1 out of 1Number of reduce tasks determined at compile time: 1In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=<number>In order to limit the maximum number of reducers: w397090770 9年前 (2016-06-28) 15224℃ 1评论39喜欢
Shanghai Apache Spark Meetup第九次聚会在6月18日下午13:00-17:00由Intel联手饿了么在上海市普陀区金沙江路1518弄2号近铁城市广场饿了么公司5楼会议室(榴莲酥+螺狮粉)举行。分享主题演讲者1: 史鸣飞, 英特尔大数据工程师演讲者2: 史栋杰, 英特尔大数据工程师演讲者3: 毕洪宇,饿了么数据运营部副总监演讲者4: 张家劲, w397090770 9年前 (2016-06-25) 2170℃ 0评论4喜欢
在Sortable公司,很多数据处理的工作都是使用Spark完成的。在使用Spark的过程中他们发现了一个能够提高Spark job性能的一个技巧,也就是修改数据的分区数,本文将举个例子并详细地介绍如何做到的。查找质数比如我们需要从2到2000000之间寻找所有的质数。我们很自然地会想到先找到所有的非质数,剩下的所有数字就是我们要找 w397090770 9年前 (2016-06-24) 23546℃ 2评论45喜欢
Hadoop集群的监控可以通过多种方式来实现(比如REST API、jmx、内置API等等)。虽然监控方式有多种,但是我们需要根据监控的指标选择不同的监控方式,比如如果你想监控作业的情况,那么你选择jmx是不能满足的;你想监控各节点的运行情况,REST API也是不能满足的。所以在选择不同当时监控时,我们需要详细了解需要我们的需 w397090770 9年前 (2016-06-23) 21396℃ 0评论34喜欢
Flink Table API Apache Flink对SQL的支持可以追溯到一年前发布的0.9.0-milestone1版本。此版本通过引入Table API来提供类似于SQL查询的功能,此功能可以操作分布式的数据集,并且可以自由地和Flink其他API进行组合。Tables在发布之初就支持静态的以及流式数据(也就是提供了DataSet和DataStream相关APIs)。我们可以将DataSet或DataStream转成Table;同 w397090770 9年前 (2016-06-16) 4240℃ 0评论5喜欢
Spark Summit 2016 San Francisco会议于2016年6月06日至6月08日在美国San Francisco进行。本次会议有多达150位Speaker,来自业界顶级的公司。 由于会议的全部资料存储在http://www.slideshare.net网站,此网站需要翻墙才能访问。基于此本站收集了本次会议的所有PPT资料供大家学习交流之用。本次会议PPT资料全部通过爬虫程序下载,如有问题 w397090770 9年前 (2016-06-15) 3380℃ 0评论9喜欢
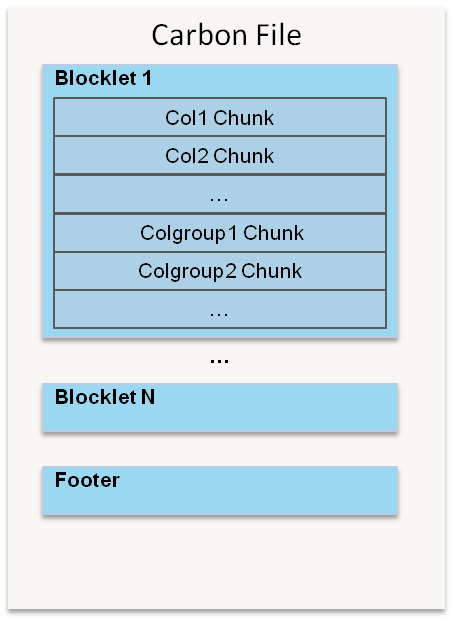
CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询。目前该项目正处于Apache孵化过程中。为什么重新设计一种文件格式目前华为针对数据的需求分析主要有以下5点要求: 1、支持海量数据扫描并 w397090770 9年前 (2016-06-13) 5497℃ 0评论7喜欢
Shanghai Apache Spark Meetup第九次聚会将在6月18日下午13:00-17:00由Intel联手饿了么在上海市普陀区金沙江路1518弄2号近铁城市广场饿了么公司5楼会议室(榴莲酥+螺狮粉)举行。欢迎大家前来参加!会议主题开场/Opening Keynote: 毕洪宇,饿了么数据运营部副总监 毕洪宇个人介绍:饿了么数据运营部副总监。本科和研究生都是同济 w397090770 9年前 (2016-06-12) 1854℃ 0评论5喜欢
我目前使用的Hive版本是apache-hive-1.2.0-bin,每次在使用 show create table 语句的时候如果你字段中有中文注释,那么Hive得出来的结果如下:hive> show create table iteblog;OKCREATE TABLE `iteblog`( `id` bigint COMMENT '�id', `uid` bigint COMMENT '(7id', `name` string COMMENT '(7�')ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' STORED AS INPUTF w397090770 9年前 (2016-06-08) 11338℃ 0评论13喜欢







![Spark Summit 2016 San Francisco PPT免费下载[共95个]](https://www.iteblog.com/pic/iteblog.png)