本文讲解的Hive和HBase整合意思是使用Hive读取Hbase中的数据。我们可以使用HQL语句在HBase表上进行查询、插入操作;甚至是进行Join和Union等复杂查询。此功能是从Hive 0.6.0开始引入的,详情可以参见HIVE-705。Hive与HBase整合的实现是利用两者本身对外的API接口互相进行通信,相互通信主要是依靠hive-hbase-handler-1.2.0.jar工具里面的类实现 w397090770 9年前 (2016-07-31) 17478℃ 0评论42喜欢
几天前(2016年7月27日),Apache社区发布了Apache Mesos 1.0.0, 这是 Apache Mesos 的一个里程碑事件。相较于前面的版本, 1.0.0首先是改进了与 docker 的集成方式,弃用了 docker daemon;其次,新版本大力推进解决了接口规范化问题,新的 HTTP API 使得开发者能够更容易的开发 Mesos 框架;最后, 为了更好的满足企业用户的多租户,安全,审 w397090770 9年前 (2016-07-31) 2031℃ 0评论2喜欢
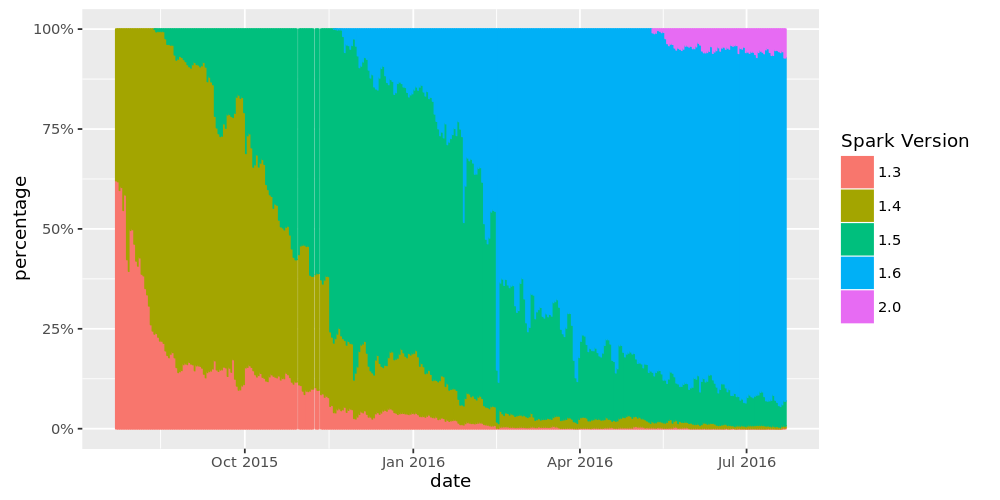
Apache Spark 2.0发布信息可以参见《Apache Spark 2.0.0正式发布及其功能介绍》 我们很荣幸地宣布,自7月26日起Databricks开始提供Apache Spark 2.0的下载,这个版本是基于社区在过去两年的经验总结而成,不但加入了用户喜爱的功能,也修复了之前的痛点。 本文总结了Spark 2.0的三大主题:更简单、更快速、更智能,另有Spark w397090770 9年前 (2016-07-28) 14414℃ 0评论28喜欢
《Apache Spark 2.0重大功能介绍》:/archives/1721 《Apache Spark作为编译器:深入介绍新的Tungsten执行引擎》:/archives/1679 《Spark 2.0技术预览:更容易、更快速、更智能》:/archives/1668 Apache Spark 2.0.0于2016-07-27正式发布。它是2.x版本线上的第一个版本。主要的更新是API可用性,SQL 2003的支持,性能提升,structured streaming w397090770 9年前 (2016-07-27) 7633℃ 4评论7喜欢
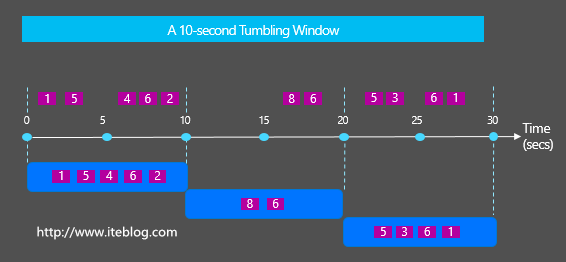
在流系统中通常会经常使用到Windows来统计一定范围的数据,比如按照固定时间、按个数等统计。一般会存在两种类型的Windows:Tumbling Windows vs Sliding Windows,它们很容易被初学者混淆,那么Tumbling Windows vs Sliding Windows之间到底有啥区别与联系呢?这就是本文将要展开的。 Tumbling的中文意思是摔跤,翻跟头,翻筋斗;Sliding中 w397090770 9年前 (2016-07-26) 3481℃ 0评论4喜欢
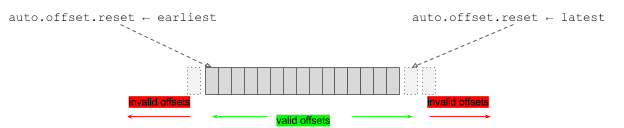
在使用Spark streaming消费kafka数据时,程序异常中断的情况下发现会有数据丢失的风险,本文简单介绍如何解决这些问题。 在问题开始之前先解释下流处理中的几种可靠性语义: 1、At most once - 每条数据最多被处理一次(0次或1次),这种语义下会出现数据丢失的问题; 2、At least once - 每条数据最少被处理一次 (1 w397090770 9年前 (2016-07-26) 10933℃ 3评论17喜欢
今年的 Spark + AI Summit 2019 databricks 开源了几个重磅的项目,比如 Delta Lake,Koalas 等,Koalas 是一个新的开源项目,它增强了 PySpark 的 DataFrame API,使其与 pandas 兼容。Python 数据科学在过去几年中爆炸式增长,pandas 已成为生态系统的关键。 当数据科学家拿到一个数据集时,他们会使用 pandas 进行探索。 它是数据清洗和分析的终极工 w397090770 9年前 (2016-07-25) 216153℃ 0评论844喜欢
Apache Kafka在LinkedIn和其他公司中是作为各种数据管道和异步消息的后端。Netflix和Microsoft公司作为Kafka的重量级使用者(Four Comma Club,每天万亿级别的消息量),他们在Kafka Summit的分享也让人受益良多。 虽然Kafka有着极其稳定的架构,但是在每天万亿级别消息量的大规模下也会偶尔出现有趣的bug。在本篇文章以及以后的几篇 w397090770 9年前 (2016-07-20) 5330℃ 1评论6喜欢
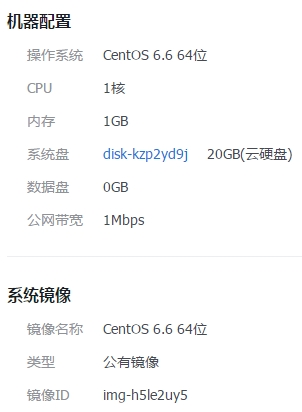
随着过往记忆大数据技术博客的浏览量逐渐增多(目前日IP达到5k+,PV达到1.5W+),博客的访问速度越来越慢,在高峰时期打开一个页面需要近10s的时间,这样的情况非常的糟糕,没多少人愿意等待近10s,所以优化网站的访问速度迫在眉睫! 先来介绍一下本博客的相关配置信息:博客购买的是腾讯云主机,CentOS 6.6 64位、1 w397090770 9年前 (2016-07-19) 1747℃ 0评论4喜欢
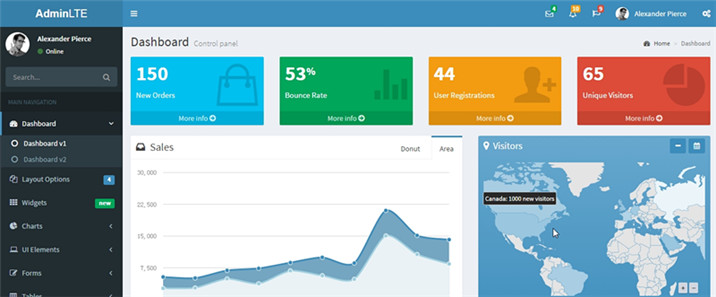
AdminLTE是一个完全响应式管理并基于Bootstrap 3.x的免费高级管理控制面板主题。高度可定制的,易于使用。自适应多种屏幕分辨率,兼容PC端和手机移动端,内置了多个模板页面,包括仪表盘、邮箱、日历、锁屏、登录及注册、404错误、500错误等页面。AdminLTE是基于模块化设计,很容易在其之上定制和重制。本文撰写的时候AdminLTE w397090770 9年前 (2016-07-17) 18681℃ 0评论24喜欢