本文所列的所有API在ElasticSearch文档是有详尽的说明,但它的结构组织的不太好。 这篇文章把ElasticSearch API用表格的形式供大家参考。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopCategoryDescriptionCall examplesDocument APISingle Document APIAdds a new document[code lang="bash"]PUT / w397090770 8年前 (2017-02-20) 2444℃ 0评论9喜欢
我们在使用HDFS Shell的时候只用最频繁的命令可能就是 ls 了,其具体含义我就不介绍了。在使用 ls 的命令时,我们可能想对展示出来的文件按照修改时间排序,也就是最近修改的文件(most recent)显示在最前面。如果你使用的是Hadoop 2.8.0以下版本,内置是不支持按照时间等属性排序的。不过值得高兴的是,我们可以结合Shell命令来 w397090770 8年前 (2017-02-18) 12651℃ 0评论9喜欢
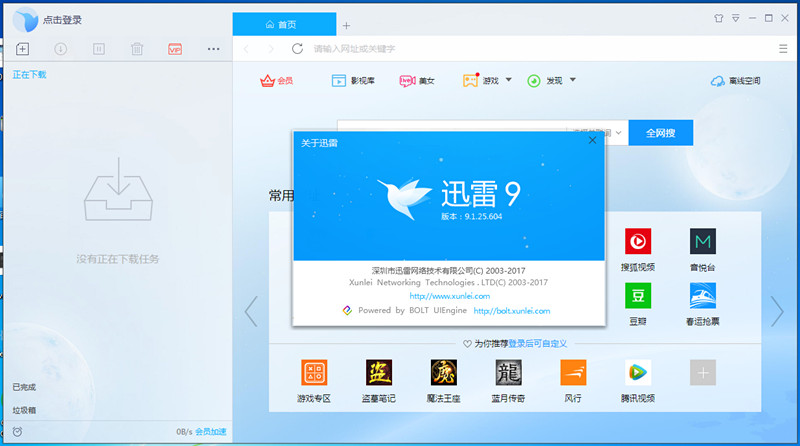
最近升级了迅雷9,新版本精简了任务列表的面积,然而增加了一个硕大的内置浏览器面板,大概占据了四分之三的窗口面积,并且不能关闭!界面如下:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop就个人观点而言,实在不能理解为什么需要让一个下载工具的附加功能占据主要使用区 w397090770 8年前 (2017-02-18) 6502℃ 0评论20喜欢
2017年已然来临,大数据技术仍然保持着飞速发展。无论是物联网、云计算领域乃至企业技术都开始将其引入自身并作为新的变革方向。众多企业已经在积极接纳大数据技术,并作为提升自身市场竞争力的核心因素。在今天的文章中,我们将基于甲骨文给出的预测结论,总结2017年十项大数据变化趋势。如果想及时了解Spark、H w397090770 8年前 (2017-02-17) 1052℃ 0评论3喜欢
想必大家在使用Maven从仓库下载Jar的时候都感觉速度非常慢吧。前几年国内的开源中国还提供了免费的Maven镜像,但是由于运营成本过高,此Maven仓库在运营两年后被迫关闭了。不过高兴的是,阿里云在2016年08月悄悄上线了Maven仓库,点这里:http://maven.aliyun.com。我们可以把下面的配置复制到$MAVEN_HOME/conf/setting.xml里面:如果想及时 w397090770 8年前 (2017-02-16) 18436℃ 1评论6喜欢
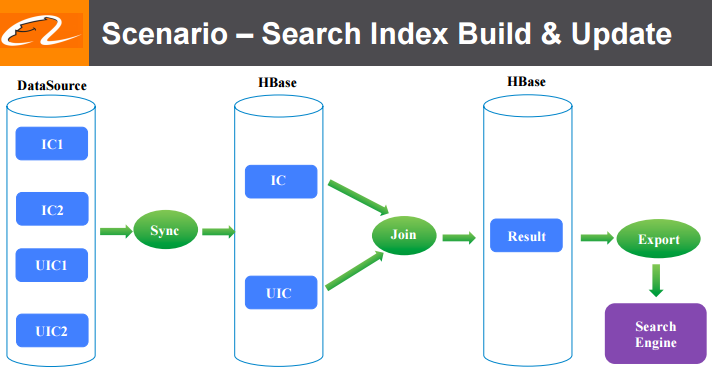
阿里巴巴是世界上最大的电子商务零售商。 我们在2015年的年销售额总计3940亿美元,超过eBay和亚马逊之和。阿里巴巴搜索(个性化搜索和推荐平台)是客户的关键入口,并承载了大部分在线收入,因此搜索基础架构团队需要不断探索新技术来改进产品。 在电子商务网站应用场景中,什么能造就一个强大的搜索引擎?答案 w397090770 8年前 (2017-02-16) 7014℃ 0评论6喜欢
在数据URI方面其是一个特别高效的UTF-8 binary-to-text编码解决方案,可以用来替换base-64解决。对同一份数据进行编码,Base-122比Base-64小14%。Base-122当前是一个实验编码,后面可能会发生变化。基本使用Base-122编码产生UTF-8字符,但每字节比base-64编码更多的位。[code lang="javascript"]let base122 = require('./base122');let inputData = require('fs'). w397090770 8年前 (2017-02-15) 1024℃ 4喜欢
下面论文均为大数据和分布式比较经典的论文,包括:CAP、BASE、2PC、一致性协议、一致性哈希、逻辑时钟、Leases 等。如果大家还有比较好的论文,欢迎在下面评论。分布式理论 Time, Clocks, and the Ordering of Events in a Distributed System Reaching Agreement in the Presence of Faults The Byzantine General Problem (CAP) Brewer's Conjecture and the Feasibility of w397090770 8年前 (2017-02-15) 3799℃ 0评论10喜欢
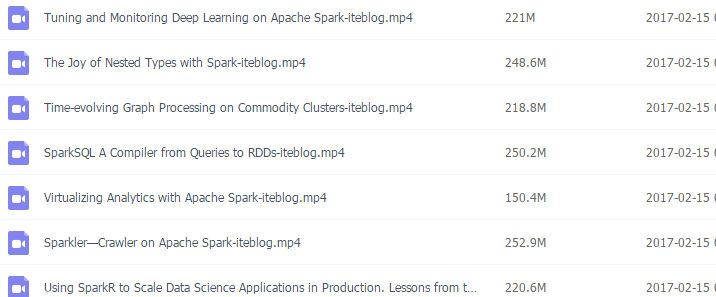
Spark Summit East 2017会议于2017年2月07日到09日在波士顿进行,本次会议有来自工业界的上百位Speaker;官方日程:https://spark-summit.org/east-2017/schedule/。 目前本站昨晚已经把里面的85(今天早上发现又上传了25个视频,晚上我补全)个视频全部从Youtube下载下来,已经上传到百度网盘(访问https://github.com/397090770/spark-summit-east-2017获 w397090770 8年前 (2017-02-15) 2847℃ 0评论15喜欢
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop《Learning Spark》O'Reilly,2015-01 电子书下载:进入下载《Advanced Analytics with Spark》 O'Reilly,2015-04 电子书下载:进入下载如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop《High Performance Spark》O'Reilly 2016-03 出 w397090770 8年前 (2017-02-12) 6769℃ 0评论18喜欢