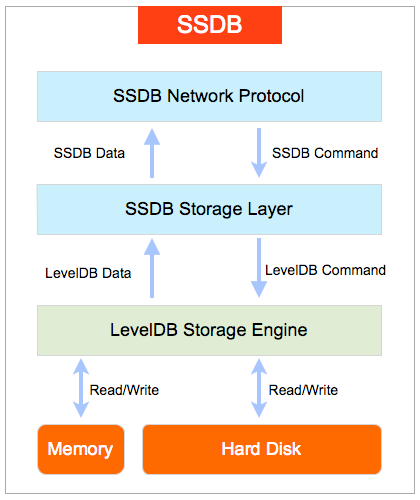
SSDB 是一个使用 C/C++ 语言开发的高性能 NoSQL 数据库, 支持 KV, list, map(hash), zset(sorted set) 等数据结构, 用来替代或者与 Redis 配合存储十亿级别列表的数据。实现上其使用了 Google 的 LevelDB作为存储引擎,SSDB 不会像 Redis 一样狂吃内存,而是将大部分数据存储到磁盘上。最重要的是,SSDB采用了New BSD License 开源协议进行了开源,目前已经 w397090770 8年前 (2017-05-27) 3033℃ 0评论7喜欢
本书作者:Rajdeep Dua、Manpreet Singh Ghotra、 Nick Pentreath,由Packt出版社于2017年04月出版,全书共532页。本书是2015年02月出版的Machine Learning with Spark的第二版。通过本书将学习到以下的知识:Get hands-on with the latest version of Spark MLCreate your first Spark program with Scala and PythonSet up and configure a development environment for Spark on your own computer, as well zz~~ 8年前 (2017-05-27) 4551℃ 0评论14喜欢
本书作者:Hanish Bansal、Saurabh Chauhan、Shrey Mehrotra,由Packt出版社于2016年4月出版,全书共486页。通过本书将学习到以下的知识:(1)、Learn different features and offering on the latest Hive(2)、Understand the working and structure of the Hive internals(3)、Get an insight on the latest development in Hive framework(4)、Grasp the concepts of Hive Data Model(5)、M zz~~ 8年前 (2017-05-26) 6413℃ 0评论22喜欢
2017年04月25日发布的nginx 1.13.0支持了TLSv1.3,而TLSv1.3相比之前的TLSv1.2、TLSv1.1等性能大幅提升。所以我迫不及待地将nginx升级到最新版1.13.0。下面记录如何升级nginx,本文基于CentOS release 6.6,其他的操作系统略有不同。如果你不知道你的系统是啥版本,可以通过下面的几个命令查询[code lang="bash"][root@iteblog.com ~]$ cat /etc/issueCentOS w397090770 8年前 (2017-05-23) 12391℃ 2评论10喜欢
昨天晚上,Apache Beam发布了第一个稳定版2.0.0,Apache Beam 社区声明:未来版本的发布将保持 API 的稳定性,并让 Beam 适用于企业的部署。Apache Beam 的第一个稳定版本是此社区第三个重要里程碑。Apache Beam 是在2016年2月加入 Apache 孵化器(Apache Incubator),并在同年的12月成功毕业成为 Apache 基金会的顶级项目(《Apache Beam成为Apache顶级项目 w397090770 8年前 (2017-05-18) 1758℃ 0评论3喜欢
如果你在Spark SQL中运行的SQL语句过长的话,会出现 java.lang.StackOverflowError 异常:[code lang="java"]java.lang.StackOverflowError at org.apache.spark.sql.hive.HiveQl$$anonfun$22.apply(HiveQl.scala:924) at org.apache.spark.sql.hive.HiveQl$$anonfun$22.apply(HiveQl.scala:924) at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244) at scala.collection.TraversableLike$$anonfun w397090770 8年前 (2017-05-17) 6331℃ 0评论7喜欢
我在前面的文章介绍了MapReduce中两种全排序的方法及其实现。但是上面的两种方法都是有很大的局限性:方法一在数据量很大的时候会出现OOM问题;方法二虽然能够将数据分散到多个Reduce中,但是问题也很明显:我们必须手动地找到各个Reduce的分界点,尽量使得分散到每个Reduce的数据量均衡。而且每次修改Reduce的个数时,都得 w397090770 8年前 (2017-05-12) 7314℃ 14评论20喜欢
我们可能会有些需求要求MapReduce的输出全局有序,这里说的有序是指Key全局有序。但是我们知道,MapReduce默认只是保证同一个分区内的Key是有序的,但是不保证全局有序。基于此,本文提供三种方法来对MapReduce的输出进行全局排序。生成测试数据在介绍如何实现之前,我们先来生成一些测试数据,实现如下:[code lang="bash"]#! w397090770 8年前 (2017-05-10) 14577℃ 0评论29喜欢
经过一个多月的投票,Apache Flink 1.2.1终于正式发布了。看这个版本就知道,Apache Flink 1.2.1仅仅是对 Flink 1.2.0进行一些Bug修复,不涉及重大的新功能。推荐所有的用户升级到Apache Flink 1.2.1。大家可以在自己项目的pom.xml文件引入以下依赖:[code lang="xml"]<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</art w397090770 8年前 (2017-05-04) 1659℃ 0评论6喜欢

![[电子书]Machine Learning with Spark Second Edition PDF下载](https://www.iteblog.com/pic/books/Machine_Learning_with_Spark_Second_Edition_iteblog.jpg)
![[电子书]Apache Hive Cookbook PDF下载](https://www.iteblog.com/pic/Apache_Hive_Cookbook-iteblog.jpg)




