Job execution logs and profiles are important when troubleshooting Hadoop errors, tuning job performance, and planning cluster capacity. In the past, the Job History Server has been the primary source for this information, providing logs of important events in MapReduce job execution and associated profiling metrics. With the advent of YARN, which enables execution frameworks beyond MapReduce, the responsibilities of the Job History Ser w397090770 8年前 (2017-06-02) 211℃ 0评论0喜欢
下面文档是今天早上翻译的,因为要上班,时间比较仓促,有些部分没有翻译,请见谅。2017年06月01日儿童节 Apache Flink 社区正式发布了 1.3.0 版本。此版本经历了四个月的开发,共解决了680个issues。Apache Flink 1.3.0 是 1.x.y 版本线上的第四个主要版本,其 API 和其他 1.x.y 使用 @Public 注释的API是兼容的。此外,Apache Flink 社区目前制 w397090770 8年前 (2017-06-01) 2612℃ 1评论10喜欢
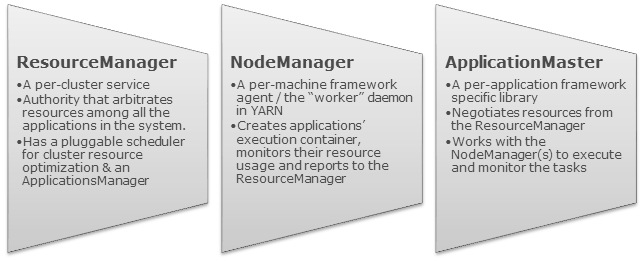
Apache YARN是将之前Hadoop 1.x的 JobTracker 功能分别拆到不同的组件里面了,每个组件分别负责不同的功能。在Hadoop 1.x中, JobTracker 负责管理集群的资源,作业调度以及作业监控;YARN把这些功能分别拆到ResourceManager 和 ApplicationMaster 中了。而之前的TaskTracker被NodeManager替代。下面分别介绍YAEN的各个组件的作用。如果想及时了解Spark、Had w397090770 8年前 (2017-06-01) 4082℃ 0评论31喜欢