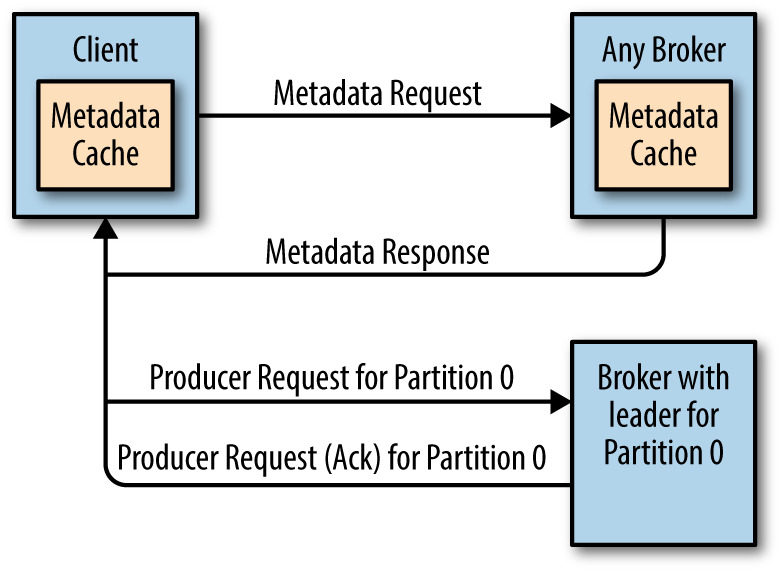
在正常情况下,Kafka中的每个Topic都会有很多个分区,每个分区又会存在多个副本。在这些副本中,存在一个leader分区,而剩下的分区叫做 follower,所有对分区的读写操作都是对leader分区进行的。所以当我们向Kafka写消息或者从Kafka读取消息的时候,必须先找到对应分区的Leader及其所在的Broker地址,这样才可以进行后续的操作。本文将 w397090770 8年前 (2017-07-28) 2061℃ 0评论6喜欢
众所周知,Kafka自己实现了一套二进制协议(binary protocol)用于各种功能的实现,比如发送消息,获取消息,提交位移以及创建topic等。具体协议规范参见:Kafka协议 这套协议的具体使用流程为:客户端创建对应协议的请求客户端发送请求给对应的brokerbroker处理请求,并发送response给客户端如果想及时了解Spark、Hadoop或者HBase w397090770 8年前 (2017-07-27) 422℃ 0评论0喜欢
最近使用ElasticSearch的时候遇到以下的异常[code land="bash"]2017-07-27 16:06:48.482 MessageHandler - message process error: java.lang.NoClassDefFoundError: Could not initialize class org.elasticsearch.common.xcontent.smile.SmileXContent at org.elasticsearch.common.xcontent.XContentFactory.contentBuilder(XContentFactory.java:124) ~[elasticsearch-2.3.4.jar:2.3.4] at org.elasticsearch.action.support.ToX w397090770 8年前 (2017-07-27) 8688℃ 0评论13喜欢
本书于2017-03由Packt Publishing出版,作者Muhammad Asif Abbasi,全书356页。通过本书你将学到以下知识:Get an overview of big data analytics and its importance for organizations and data professionalsDelve into Spark to see how it is different from existing processing platformsUnderstand the intricacies of various file formats, and how to process them with Apache Spark.Realize how to deploy Spark with YAR zz~~ 8年前 (2017-07-26) 14762℃ 0评论29喜欢
我们都知道,目前 Apache Beam 仅仅提供了 Java 和 Python 两种语言的 API,尚不支持 Scala 相关的 API。基于此全球最大的流音乐服务商 Spotify 开发了 Scio ,其为 Apache Beam 和 Google Cloud Dataflow 提供了Scala API,使得我们可以直接使用 Scala 来编写 Beam 应用程序。Scio 开发受 Apache Spark 和 Scalding 的启发,目前最新版本是 Scio 0.3.0,0.3.0版本之前依赖 w397090770 8年前 (2017-07-25) 1283℃ 0评论7喜欢
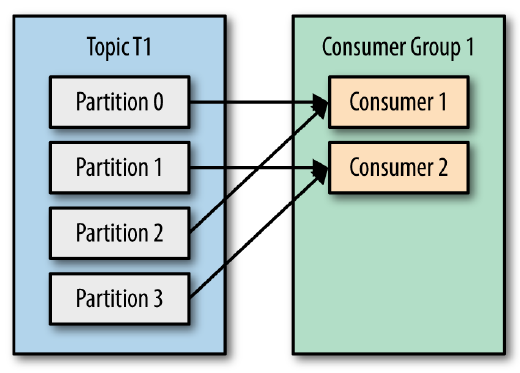
问题用过 Kafka 的同学应该都知道,每个 Topic 一般会有很多个 partitions。为了使得我们能够及时消费消息,我们也可能会启动多个 Consumer 去消费,而每个 Consumer 又会启动一个或多个streams去分别消费 Topic 对应分区中的数据。我们又知道,Kafka 存在 Consumer Group 的概念,也就是 group.id 一样的 Consumer,这些 Consumer 属于同一个Consumer Group w397090770 8年前 (2017-07-22) 17846℃ 3评论27喜欢
本文涉及到的环境:操作系统:Windows 7Idea 版本:IntelliJ IDEA 2016.3.4 Build #IU-163.12024.16, built on January 31, 2017Kafka 版本:Kafka 0.8.2.0Gradle 版本:gradle-4.0.1JDK 版本:jdk1.7.0Scala 版本:2.10.4首先到http://archive.apache.org/dist/kafka/里面下载你需要的Kafka源码,本文选自的是kafka-0.8.2.0。因为Kafka代码自0.8.x之后就使用 Gradle 来进行编译 w397090770 8年前 (2017-07-21) 6206℃ 0评论16喜欢
越来越多的公司采用流处理,并将现有的批处理应用迁移到流处理,或者对新的用例采用流处理实现的解决方案。其中许多应用集中在流数据分析上,分析的数据流来自各种源,例如数据库事务、点击、传感器测量或 IoT 设备。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopApache Flink 非常 w397090770 8年前 (2017-07-20) 3548℃ 0评论16喜欢
Apache Spark 2.2.0 经过了大半年的紧张开发,从RC1到RC6终于在今天正式发布了。由于时间的缘故,我并没有在《Apache Spark 2.2.0正式发布》文章中过多地介绍 Apache Spark 2.2.0 的新特性,本文作为补充将详细介绍Apache Spark 2.2.0 的新特性。这个版本是 Structured Streaming 的一个重要里程碑,因为其终于可以正式在生产环境中使用,实验标签(ex w397090770 8年前 (2017-07-12) 9336℃ 0评论28喜欢
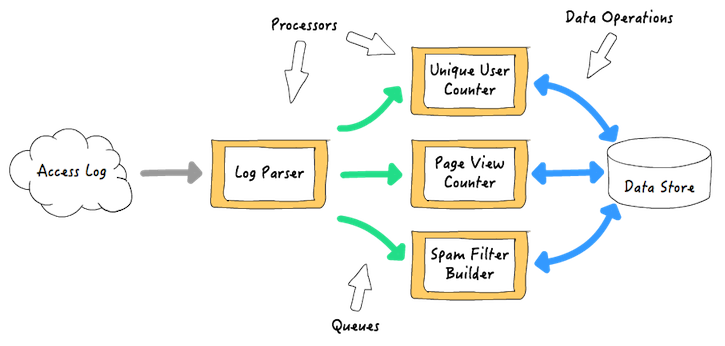
一个实时流处理框架通常需要两个基础架构:处理器和队列。处理器从队列中读取事件,执行用户的处理代码,如果要继续对结果进行处理,处理器还会把事件写到另外一个队列。队列由框架提供并管理。队列做为处理器之间的缓冲,传输数据和事件,这样处理器可以单独操作和扩展。例如,一个web 服务访问日志处理应用,可能是 w397090770 8年前 (2017-07-12) 595℃ 0评论0喜欢


![[电子书]Learning Apache Spark 2 PDF下载](https://www.iteblog.com/pic/books/Learning-Apache-Spark-2_iteblog.png)