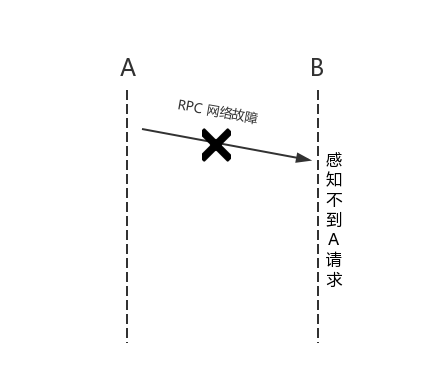
在传统的单机系统中,我们调用一个函数,这个函数要么返回成功,要么返回失败,其结果是确定的。可以概括为传统的单机系统调用只存在两态(2-state system):成功和失败。然而在分布式系统中,由于系统是分布在不同的机器上,系统之间的请求就相对于单机模式来说复杂度较高了。具体的,节点 A 上的系统通过 RPC (Remote Proc w397090770 7年前 (2018-04-20) 2555℃ 0评论9喜欢
4月6日,Apache Hadoop 3.1.0 正式发布了,Apache Hadoop 3.1.0 是2018年 Hadoop-3.x 系列的第一个小版本,并且带来了许多增强功能。不过需要注意的是,这个版本并不推荐在生产环境下使用,如果需要在正式环境下使用,请等待 3.1.1 或 3.1.2 版本。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop这个版 w397090770 7年前 (2018-04-08) 3569℃ 0评论15喜欢
本文将对 Spark 的内存管理模型进行分析,下面的分析全部是基于 Apache Spark 2.2.1 进行的。为了让下面的文章看起来不枯燥,我不打算贴出代码层面的东西。文章仅对统一内存管理模块(UnifiedMemoryManager)进行分析,如对之前的静态内存管理感兴趣,请参阅网上其他文章。我们都知道 Spark 能够有效的利用内存并进行分布式计算,其内 w397090770 7年前 (2018-04-01) 19895℃ 4评论93喜欢