背景在默认情况下,Spark Streaming 通过 receivers (或者是 Direct 方式) 以生产者生产数据的速率接收数据。当 batch processing time > batch interval 的时候,也就是每个批次数据处理的时间要比 Spark Streaming 批处理间隔时间长;越来越多的数据被接收,但是数据的处理速度没有跟上,导致系统开始出现数据堆积,可能进一步导致 Executor 端出现 w397090770 7年前 (2018-05-28) 27277℃ 409评论62喜欢
Apache Flink 1.5.0 于昨天晚上正式发布了。在过去五个月的时间里,Flink 社区共解决了超过 780 个 issues。完整的 changelog 看这里: https://issues.apache.org/jira/secure/ReleaseNote.jspa?version=12341764&projectId=12315522。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopFlink 1.5.0 是 1.x.y 版本线上的第六个主要发行版。 w397090770 7年前 (2018-05-26) 3120℃ 0评论12喜欢
FTP 是 File Transfer Protocol(文件传输协议)的英文简称,而中文简称为“文传协议”。用于 Internet 上的控制文件的双向传输。同时,它也是一个应用程序(Application)。基于不同的操作系统有不同的 FTP 应用程序,而所有这些应用程序都遵守同一种协议以传输文件。在 FTP 的使用当中,用户经常遇到两个概念:下载(Download)和上传(Up w397090770 7年前 (2018-05-23) 5274℃ 0评论7喜欢
在 《HDFS 块和 Input Splits 的区别与联系》 文章中介绍了HDFS 块和 Input Splits 的区别与联系,其中并没有涉及到源码级别的描述。为了补充这部分,这篇文章将列出相关的源码进行说明。看源码可能会比直接看文字容易理解,毕竟代码说明一切。为了简便起见,这里只描述 TextInputFormat 部分的读取逻辑,关于写 HDFS 块相关的代码请参 w397090770 7年前 (2018-05-16) 2393℃ 0评论19喜欢
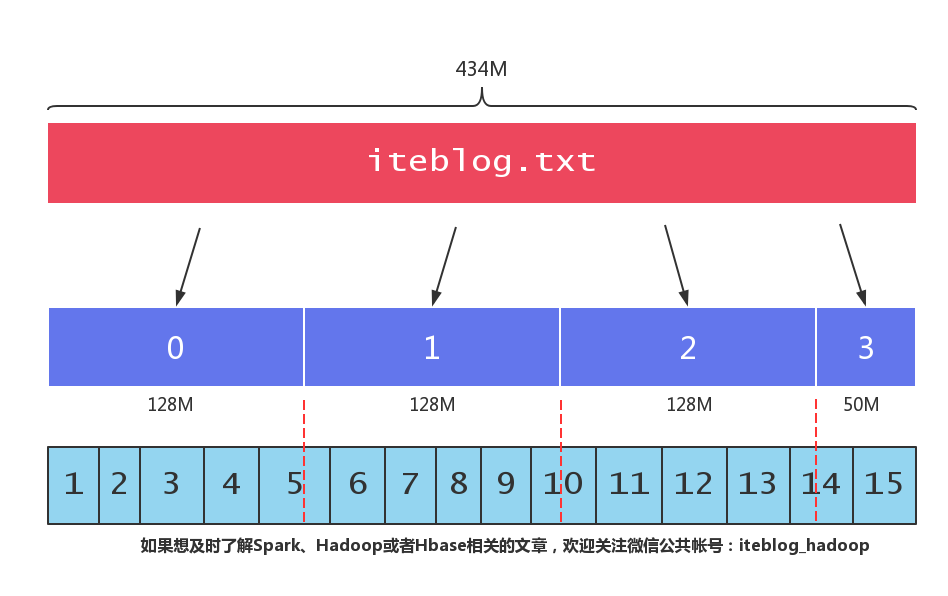
相信大家都知道,HDFS 将文件按照一定大小的块进行切割,(我们可以通过 dfs.blocksize 参数来设置 HDFS 块的大小,在 Hadoop 2.x 上,默认的块大小为 128MB。)也就是说,如果一个文件大小大于 128MB,那么这个文件会被切割成很多块,这些块分别存储在不同的机器上。当我们启动一个 MapReduce 作业去处理这些数据的时候,程序会计算出文 w397090770 7年前 (2018-05-16) 2692℃ 4评论28喜欢
Apache Kafka 从 0.11.0.0 版本开始支持在消息中添加 header 信息,具体参见 KAFKA-4208。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop本文将介绍如何使用 spring-kafka 在 Kafka Message 中添加或者读取自定义 headers。本文使用各个系统的版本为:Spring Kafka: 2.1.4.RELEASESpring Boot: 2.0.0.RELEASEApache Kafka: kafka w397090770 7年前 (2018-05-13) 4853℃ 0评论0喜欢
杭州第六次 Spark & Flink Meetup 于2018年05月12日在华为杭研所1号楼1楼报告厅进行。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop议题本次会议的议题如下:冯叶磊 - 华为云 《Time GeoSpatial on Flink SQL》范文臣 - Spark PMC 《deep dive into structural streaming》梁永峰 - 阿里《基于Flink的流计算平台 w397090770 7年前 (2018-05-13) 3941℃ 1评论8喜欢
Apache CarbonData 是一种新的融合存储解决方案,利用先进的列式存储,索引,压缩和编码技术提高计算效率,从而加快查询速度,其查询速度比 PetaBytes 数据快一个数量级。 鉴于目前使用 Apache CarbonData 用户越来越多,其中就包含了大量的中国用户,这些中国用户可能有很多人英文不是特别好,或者没那么多时间去看英文文档。基于 w397090770 7年前 (2018-05-09) 10817℃ 0评论22喜欢
一致性问题在介绍分布式系统一致性问题之前,我们先来了解一下副本概念。分布式系统会存在许多异常问题,比如机器宕机;为了提供高可用服务,一般会将数据或者服务部署到很多机器上,这些机器中的数据或服务可以称为副本。如果其中任何一台节点出现故障,用户可以访问其他机器上的数据或服务。由于副本的存在,如 w397090770 7年前 (2018-05-04) 4660℃ 0评论10喜欢
二叉树的前序遍历给你二叉树的根节点 root ,返回它节点值的 前序 遍历。示例 1:输入: [code lang="bash"] 1 \ 2 / 3 [/code]输出: [1,2,3]示例 2:输入: [code lang="bash"] 1 /2[/code]输出: [1,2]递归首先我们需要了解什么是二叉树的前序遍历:按照访问根节点——左子树——右子树的方式遍历这棵树,而在 w397090770 7年前 (2018-05-02) 68℃ 0评论0喜欢