gossip 是什么gossip 协议(gossip protocol)又称 epidemic 协议(epidemic protocol),是基于流行病传播方式的节点或者进程之间信息交换的协议,在分布式系统中被广泛使用,比如我们可以使用 gossip 协议来确保网络中所有节点的数据一样。gossip protocol 最初是由施乐公司帕洛阿尔托研究中心(Palo Alto Research Center)的研究员艾伦·德默斯(Al w397090770 6年前 (2019-01-24) 19840℃ 1评论15喜欢
如果你使用 Spark RDD 或者 DataFrame 编写程序,我们可以通过 coalesce 或 repartition 来修改程序的并行度:[code lang="scala"]val data = sc.newAPIHadoopFile(xxx).coalesce(2).map(xxxx)或val data = sc.newAPIHadoopFile(xxx).repartition(2).map(xxxx)val df = spark.read.json("/user/iteblog/json").repartition(4).map(xxxx)val df = spark.read.json("/user/iteblog/json").coalesce(4).map(x w397090770 6年前 (2019-01-24) 8228℃ 0评论12喜欢
现象大家在使用 Apache Spark 2.x 的时候可能会遇到这种现象:虽然我们的 Spark Jobs 已经全部完成了,但是我们的程序却还在执行。比如我们使用 Spark SQL 去执行一些 SQL,这个 SQL 在最后生成了大量的文件。然后我们可以看到,这个 SQL 所有的 Spark Jobs 其实已经运行完成了,但是这个查询语句还在运行。通过日志,我们可以看到 driver w397090770 6年前 (2019-01-14) 4277℃ 0评论18喜欢
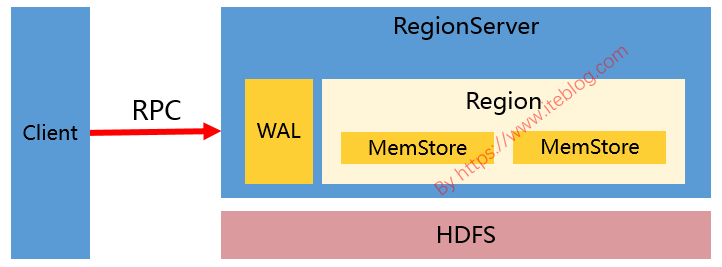
接触过 HBase 的同学应该对 HBase 写数据的过程比较熟悉(不熟悉也没关系)。HBase 写数据(比如 put、delete)的时候,都是写 WAL(假设 WAL 没有被关闭) ,然后将数据写到一个称为 MemStore 的内存结构里面的,如下图:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop但是,MemStore 毕竟是内存里 w397090770 6年前 (2019-01-13) 7506℃ 4评论32喜欢
在介绍 HBase 是不是列式存储数据库之前,我们先来了解一下什么是行式数据库和列式数据库。行式数据库和列式数据库在维基百科里面,对行式数据库和列式数据库的定义为:列式数据库是以列相关存储架构进行数据存储的数据库,主要适合于批量数据处理(OLAP)和即时查询。相对应的是行式数据库,数据以行相关的存储体 w397090770 6年前 (2019-01-08) 6479℃ 0评论31喜欢
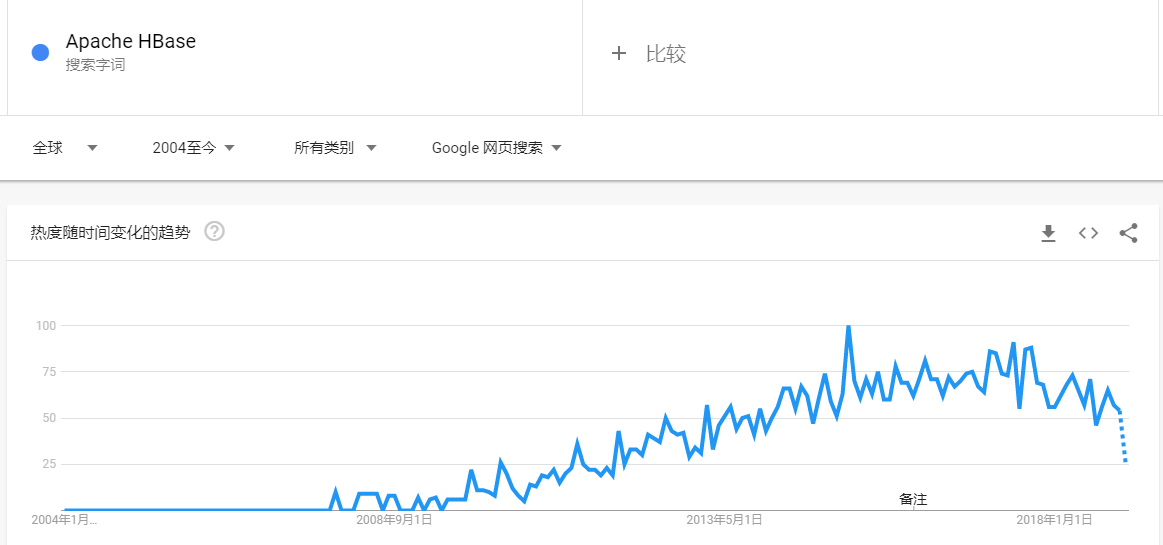
Apache HBase是基于Hadoop构建的一个分布式的、可伸缩的海量数据存储系统。随着时间的推移,HBase目前不管是在国内还是国外都受到了非常大的欢迎,以下分别是近几年 Google 和百度关于 HBase 的搜索趋势:Google如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop大家可以看到,整体趋势是越来越 w397090770 6年前 (2019-01-05) 3579℃ 4评论15喜欢
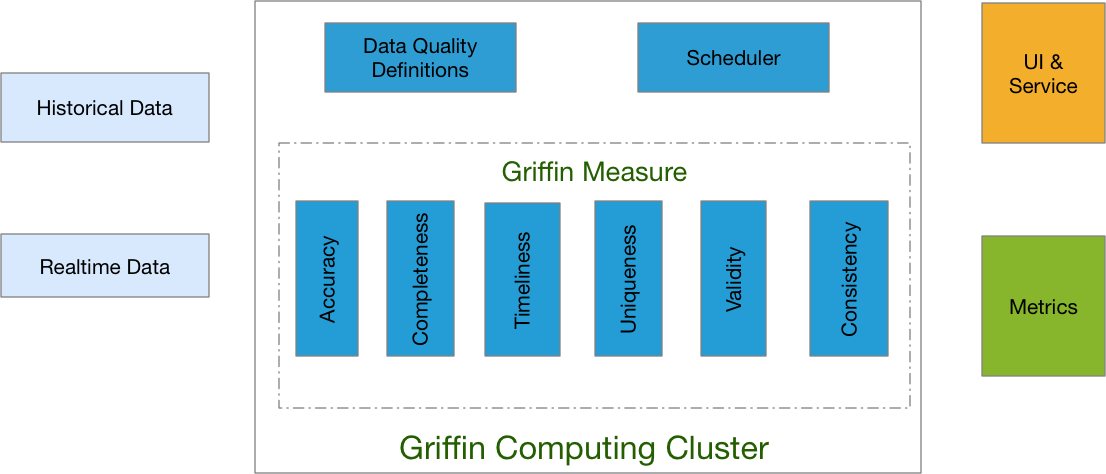
Apache Griffin 是开源的大数据数据质量解决方案,支持批处理和流模式,其是基于 Apache Hadoop 和 Apache Spark 构建,由 eBay 开发,并于 2016年12月07日进入 Apache 孵化。Griffin 提供了一个可以处理不同的任务,如定义数据质量模型,执行数据质量测量,自动化数据分析和验证,以及跨多个数据系统的统一数据质量可视化的全面的框架,旨在 w397090770 6年前 (2019-01-03) 9341℃ 3评论9喜欢
Apache HBase 是构建在 HDFS 之上的数据库,使用 HBase 我们可以随机读写存储在 HDFS 上的数据,但是我们都知道,HDFS 上的文件仅仅只支持追加(Append),其默认是不支持修改已经写好的文件。所以很多人就会问,HBase 是如何实现低延迟的读写能力呢?文本将试图介绍 HBase 写数据的过程。其实 HBase 写数据包括 put 和 delete 操作,在 HBase w397090770 6年前 (2019-01-02) 2583℃ 0评论12喜欢
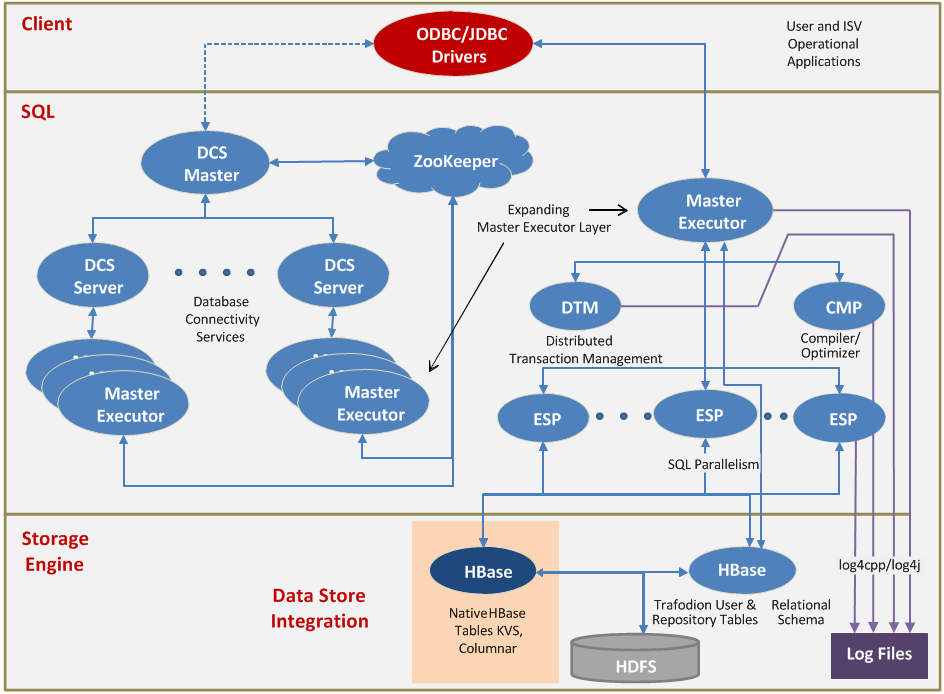
去年,我整理了2017年成功晋升为Apache TLP的大数据相关项目进行了整理,具体可以参见《盘点2017年晋升为Apache TLP的大数据相关项目》。现在已经进入了2019年了,我在这里给大家整理了2018年成功晋升为 Apache TLP 的大数据相关项目。2018年晋升成 TLP 的项目不多,总共四个,按照项目晋升的时间进行排序的。Apache Trafodion:基于 Hadoop 平 w397090770 6年前 (2019-01-02) 1597℃ 0评论4喜欢
在《HDFS 快照编程指南》文章中,我简单介绍了 HDFS 的快照功能。本文将介绍 HBase 快照功能,因为 HBase 的底层存储是基于 HDFS 的,所以 HBase 的快照功能也是依赖 HDFS 快照的知识。HBase 快照功能是从 HBase 0.95.0 开始引入的,详见 HBASE-50。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoopHBase 快 w397090770 6年前 (2019-01-01) 2695℃ 0评论9喜欢