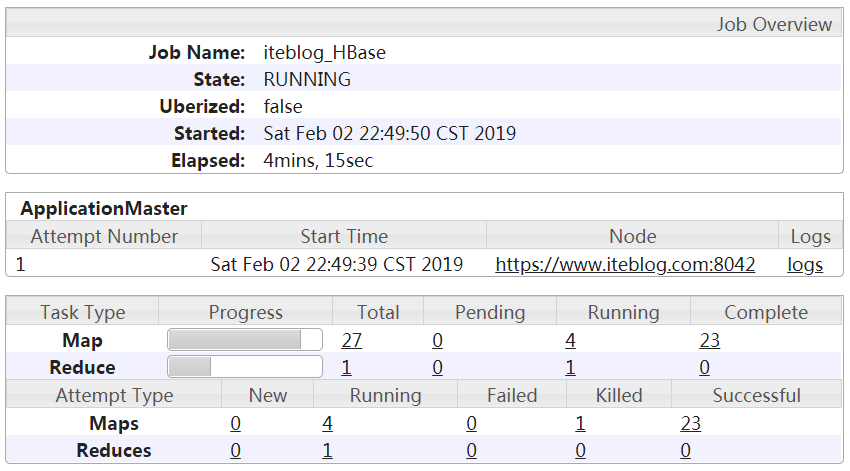
前两篇文章,《HBase 中加盐(Salting)之后的表如何读取:协处理器篇》 和 《HBase 中加盐(Salting)之后的表如何读取:Spark 篇》 分别介绍了两种方法读取加盐之后的 HBase 表。本文将介绍如何在 MapReduce 读取加盐之后的表。在 MapReduce 中也可以使用 《HBase 中加盐(Salting)之后的表如何读取:Spark 篇》 文章里面的 SaltRangeTableInputForm w397090770 6年前 (2019-02-27) 2954℃ 0评论7喜欢
在 《HBase 中加盐(Salting)之后的表如何读取:协处理器篇》 文章中介绍了使用协处理器来查询加盐之后的表,本文将介绍第二种方法来实现相同的功能。我们知道,HBase 为我们提供了 hbase-mapreduce 工程包含了读取 HBase 表的 InputFormat、OutputFormat 等类。这个工程的描述如下:This module contains implementations of InputFormat, OutputFormat, Mapper w397090770 6年前 (2019-02-26) 3904℃ 0评论16喜欢
在 《HBase Rowkey 设计指南》 文章中,我们介绍了避免数据热点的三种比较常见方法:加盐 - Salting哈希 - Hashing反转 - Reversing其中在加盐(Salting)的方法里面是这么描述的:给 Rowkey 分配一个随机前缀以使得它和之前排序不同。但是在 Rowkey 前面加了随机前缀,那么我们怎么将这些数据读出来呢?我将分三篇文章来介绍如何 w397090770 6年前 (2019-02-24) 4728℃ 0评论11喜欢
由于Spark基于内存计算的特性,集群的任何资源都可以成为Spark程序的瓶颈:CPU,网络带宽,或者内存。通常,如果内存容得下数据,瓶颈会是网络带宽。不过有时你同样需要做些优化,例如将RDD以序列化到磁盘,来降低内存占用。这个教程会涵盖两个主要话题:数据序列化,它对网络性能尤其重要并可以减少内存使用,以及内存调优 w397090770 6年前 (2019-02-20) 3233℃ 0评论8喜欢
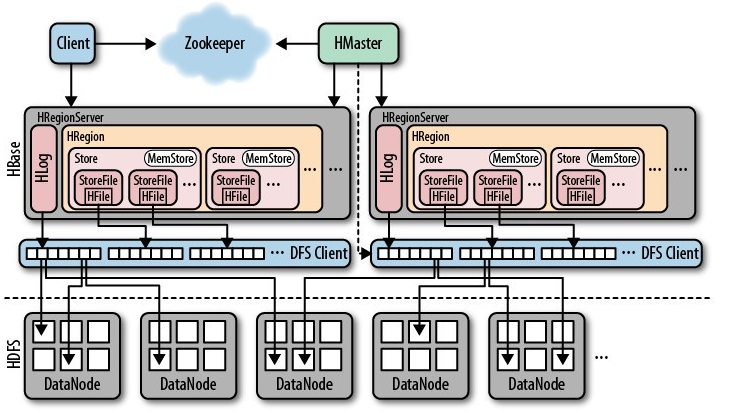
本文首先对 HBase 做简单的介绍,包括其整体架构、依赖组件、核心服务类的相关解析。再重点介绍 HBase 读取数据的流程分析,并根据此流程介绍如何在客户端以及服务端优化性能,同时结合有赞线上 HBase 集群的实际应用情况,将理论和实践结合,希望能给读者带来启发。如文章有纰漏请在下面留言,我们共同探讨共同学习。HBas w397090770 6年前 (2019-02-20) 5260℃ 0评论11喜欢
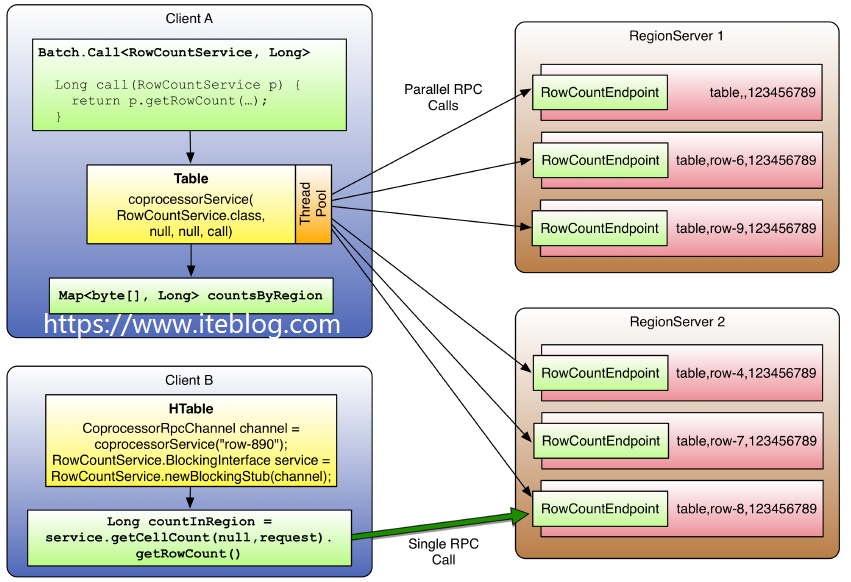
HBase 和 MapReduce 有很高的集成,我们可以使用 MR 对存储在 HBase 中的数据进行分布式计算。但是在很多情况下,例如简单的加法计算或者聚合操作(求和、计数等),如果能够将这些计算推送到 RegionServer,这将大大减少服务器和客户的的数据通信开销,从而提高 HBase 的计算性能,这就是本文要介绍的协处理器(Coprocessors)。HBase w397090770 6年前 (2019-02-17) 6327℃ 2评论13喜欢
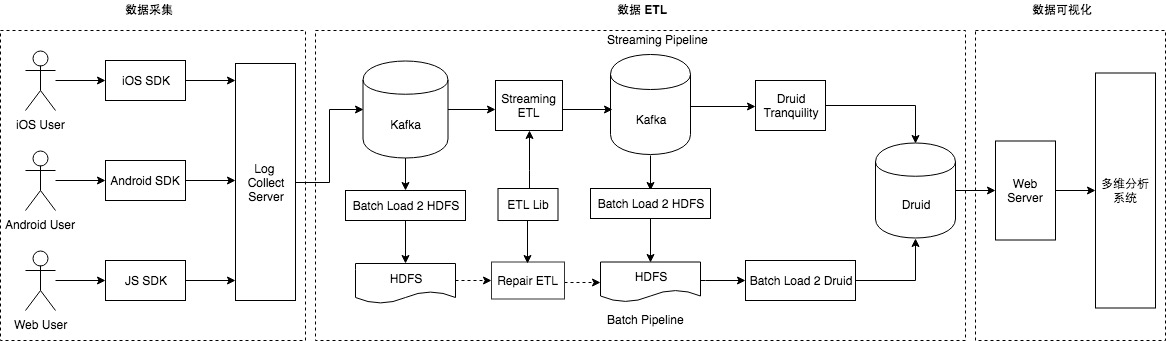
“数据智能” (Data Intelligence) 有一个必须且基础的环节,就是数据仓库的建设,同时,数据仓库也是公司数据发展到一定规模后必然会提供的一种基础服务。从智能商业的角度来讲,数据的结果代表了用户的反馈,获取结果的及时性就显得尤为重要,快速的获取数据反馈能够帮助公司更快的做出决策,更好的进行产品迭代,实时数 w397090770 6年前 (2019-02-16) 24269℃ 1评论46喜欢
Google Protocol Buffer( 简称 Protobuf) 是 Google 公司内部的混合语言数据标准,目前已经正在使用的有超过 48,162 种报文格式定义和超过 12,183 个 .proto 文件。他们用于 RPC 系统和持续数据存储系统。Protocol Buffers 是一种序列化数据结构的方法。对于通过管线(pipeline)或存储数据进行通信的程序开发上是很有用的。这个方法包含一个接口描述 w397090770 6年前 (2019-02-01) 6907℃ 0评论8喜欢
一致性哈希算法(Consistent Hashing)最早在1997年由 David Karger 等人在论文《Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web》中被提出,其设计目标是为了解决因特网中的热点(Hot spot)问题;一致性哈希最初在 P2P 网络中作为分布式哈希表( DHT)的常用数据分布算法,目前这个算法在分布式系统中成 w397090770 6年前 (2019-02-01) 3998℃ 0评论7喜欢