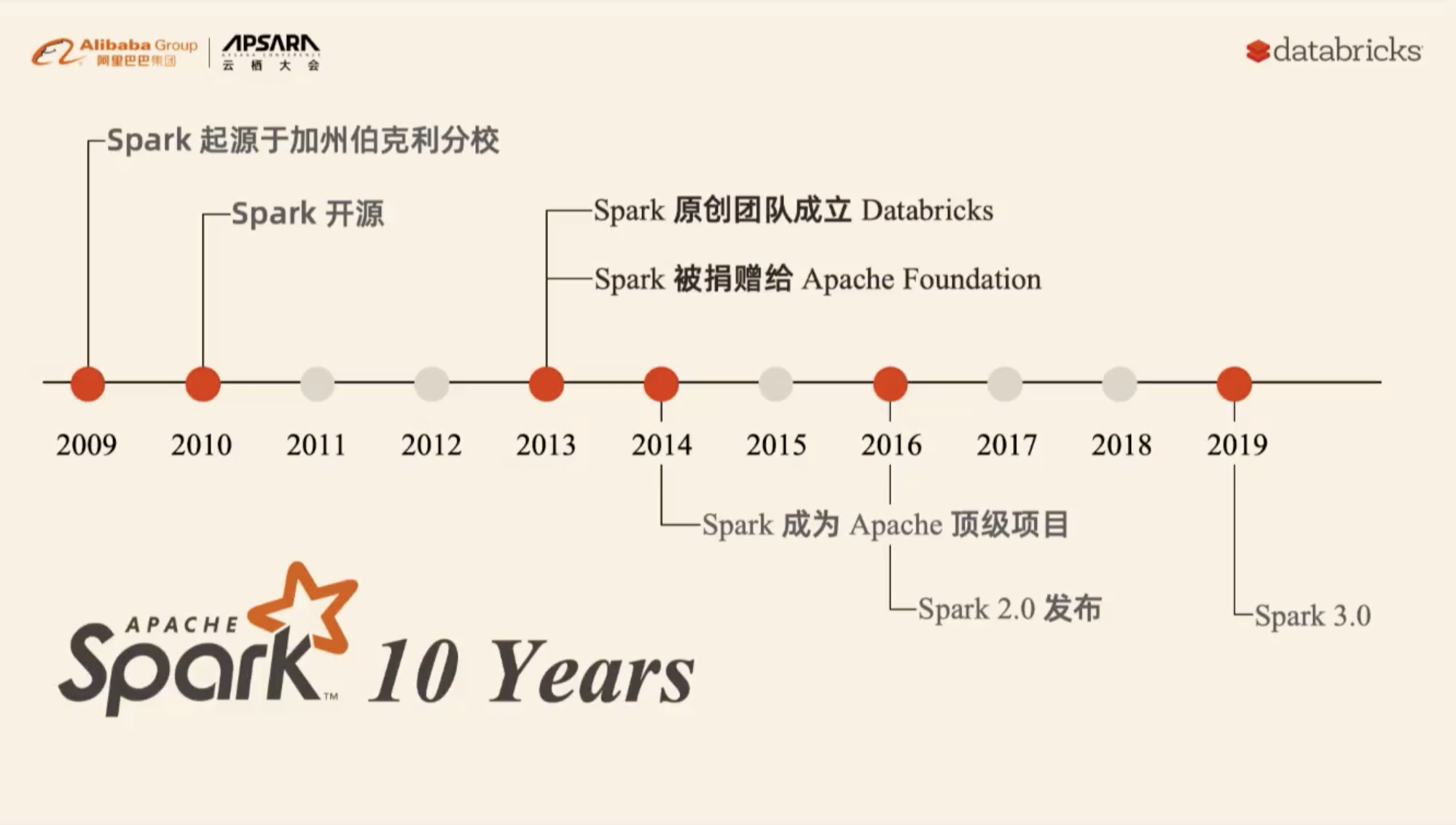
本资料来自2019-09-26在杭州举办的云栖大会的大数据 & AI 峰会分会。议题名称《New Developments in the Open Source Ecosystem: Apache Spark 3.0 and Koalas》,分享嘉宾李潇,Databricks Spark 研发总监。下面是本次会议的视频(由于微信公众号的限制,只能发布小于30分钟的视频,完整视频和 PPT 请关注 过往记忆大数据 公众号并回复 spark_yq 获取。) w397090770 5年前 (2019-09-27) 2932℃ 0评论3喜欢
Delta Lake 的 Delete 功能是由 0.3.0 版本引入的,参见这里,对应的 Patch 参见这里。在介绍 Apache Spark Delta Lake 实现逻辑之前,我们先来看看如何使用 delete 这个功能。Delta Lake 删除使用Delta Lake 的官方文档为我们提供如何使用 Delete 的几个例子,参见这里,如下:[code lang="scala"]import io.delta.tables._val iteblogDeltaTable = DeltaTable.forPath(spa w397090770 5年前 (2019-09-27) 1545℃ 0评论2喜欢
为了让大家更好地学习交流,过往记忆大数据花了一个周末的时间把 Awesome Big Data 里近 600 个大数据相关的调度、存储、计算、数据库以及可视化等介绍全部翻译了一遍,供大家学习交流。关系型数据库管理系统MySQL 世界上最流行的开源数据库。PostgreSQL 世界上最先进的开源数据库。Oracle Database - 对象关系数据库管理系统。T w397090770 5年前 (2019-09-23) 12544℃ 0评论34喜欢
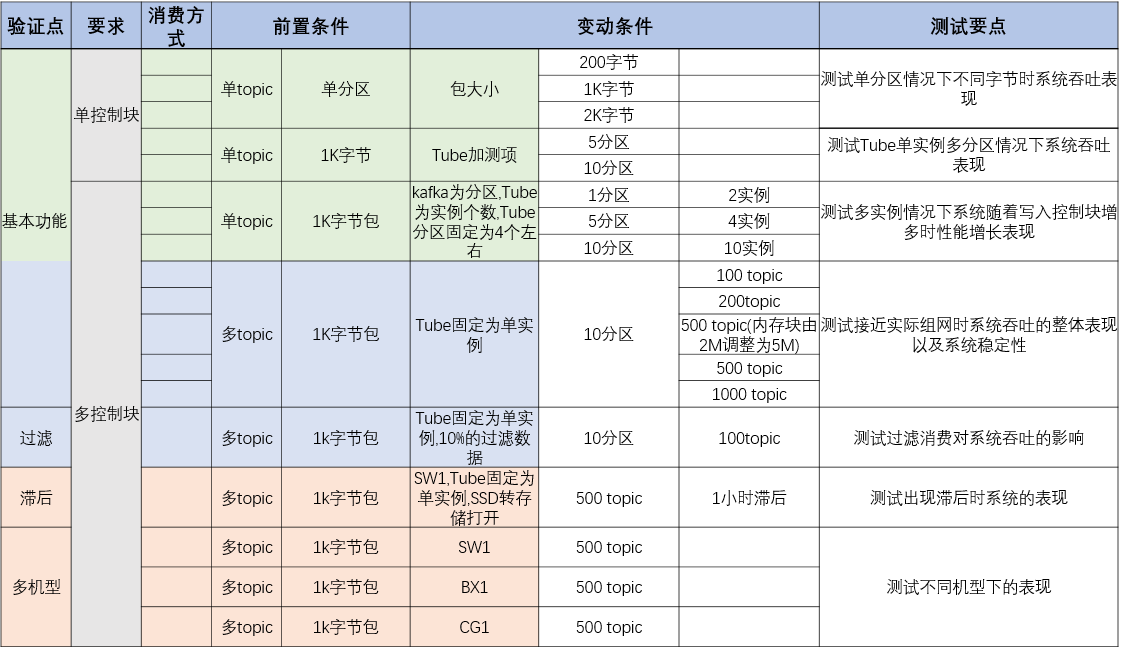
TubeMQ 是腾讯在 2013 年自研的分布式消息中间件系统,专注服务大数据场景下海量数据的高性能存储和传输,经过近7年上万亿的海量数据沉淀,目前日均接入量超过25万亿条。较之于众多明星的开源MQ组件,TubeMQ 在海量实践(稳定性+性能)和低成本方面有着比较好的核心优势。该项目于 2019年11月03日正式进入 Apache 孵化器。TubeMQ的 w397090770 5年前 (2019-09-18) 641℃ 0评论2喜欢
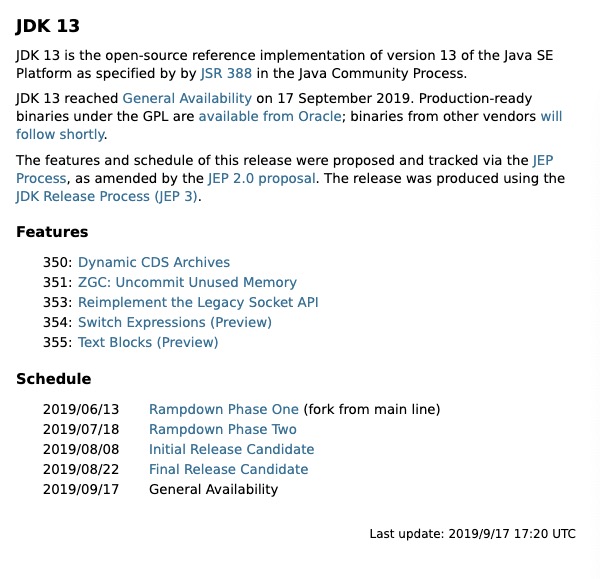
就在昨天(2019年09月17日),JDK 13 已经处于 General Availability 状态,已经正式可用了。General Availability(简称 GA)是一种正式版本的命名,也就是官方开始推荐广泛使用了,我们熟悉的 MySQL 就用 GA 来命令其正式版本。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop从上图我们可以看到 JDK 13 带来了 w397090770 5年前 (2019-09-18) 1556℃ 0评论1喜欢
最近很多粉丝后台留言问了一些大数据的面试题,其中包括了大量的 Kafka、Spark等相关的问题,所以我特意抽出一些时间整理了一些场景的大数据相关面试题,本文是 Kafka 面试相关问题,其他系列面试题后面会陆续整理,欢迎关注过往记忆大数据公众号。当然,由于个人知识面的限制,还有很多面试题相关的东西本文没有收集整理 w397090770 5年前 (2019-09-14) 17037℃ 3评论37喜欢
Delta Lake 写数据是其最基本的功能,而且其使用和现有的 Spark 写 Parquet 文件基本一致,在介绍 Delta Lake 实现原理之前先来看看如何使用它,具体使用如下:[code lang="scala"]df.write.format("delta").save("/data/iteblog/delta/test/")//数据按照 dt 分区df.write.format("delta").partitionBy("dt").save("/data/iteblog/delta/test/" w397090770 5年前 (2019-09-10) 2211℃ 0评论2喜欢
Delta Lake 是一个存储层,为 Apache Spark 和大数据 workloads 提供 ACID 事务能力,其通过写和快照隔离之间的乐观并发控制(optimistic concurrency control),在写入数据期间提供一致性的读取,从而为构建在 HDFS 和云存储上的数据湖(data lakes)带来可靠性。Delta Lake 还提供内置数据版本控制,以便轻松回滚。为了更好的学习 Delta Lake ,本文 w397090770 5年前 (2019-09-09) 4017℃ 0评论4喜欢
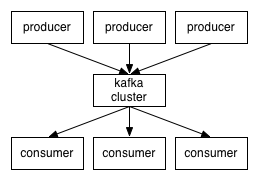
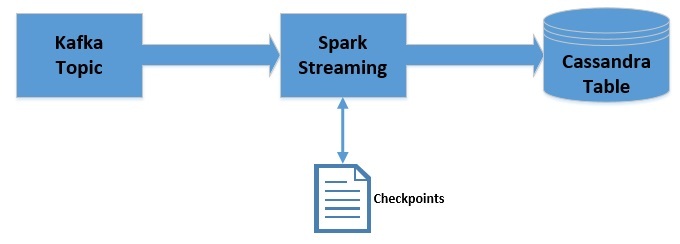
Apache Kafka 是一个可扩展,高性能,低延迟的平台,允许我们像消息系统一样读取和写入数据。我们可以很容易地在 Java 中使用 Kafka。Spark Streaming 是 Apache Spark 的一部分,是一个可扩展、高吞吐、容错的实时流处理引擎。虽然是使用 Scala 开发的,但是支持 Java API。Apache Cassandra 是分布式的 NoSQL 数据库。在这篇文章中,我们将 w397090770 5年前 (2019-09-08) 4076℃ 0评论8喜欢
Zomato 是一家食品订购、外卖及餐馆发现平台,被称为印度版的“大众点评”。目前,该公司的业务覆盖全球24个国家(主要是印度,东南亚和中东市场)。本文将介绍该公司的 Food Feed 业务是如何从 Redis 迁移到 Cassandra 的。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公众号:iteblog_hadoopFood Feed 是 Zomato 社交场景 w397090770 5年前 (2019-09-08) 1145℃ 0评论2喜欢