本博客盘点了过去两年晋升为 Apache TLP(Apache Top-Level Project) 的大数据相关项目,具体参见《盘点2017年晋升为Apache TLP的大数据相关项目》、《盘点2018年晋升为Apache TLP的大数据相关项目》,继承这个惯例,本文将给大家盘点2019年晋升为 Apache TLP 的大数据相关项目,由于今年晋升成 TLP 的大数据项目很少,只有三个,而且其中两个好 w397090770 5年前 (2019-12-30) 2240℃ 0评论7喜欢
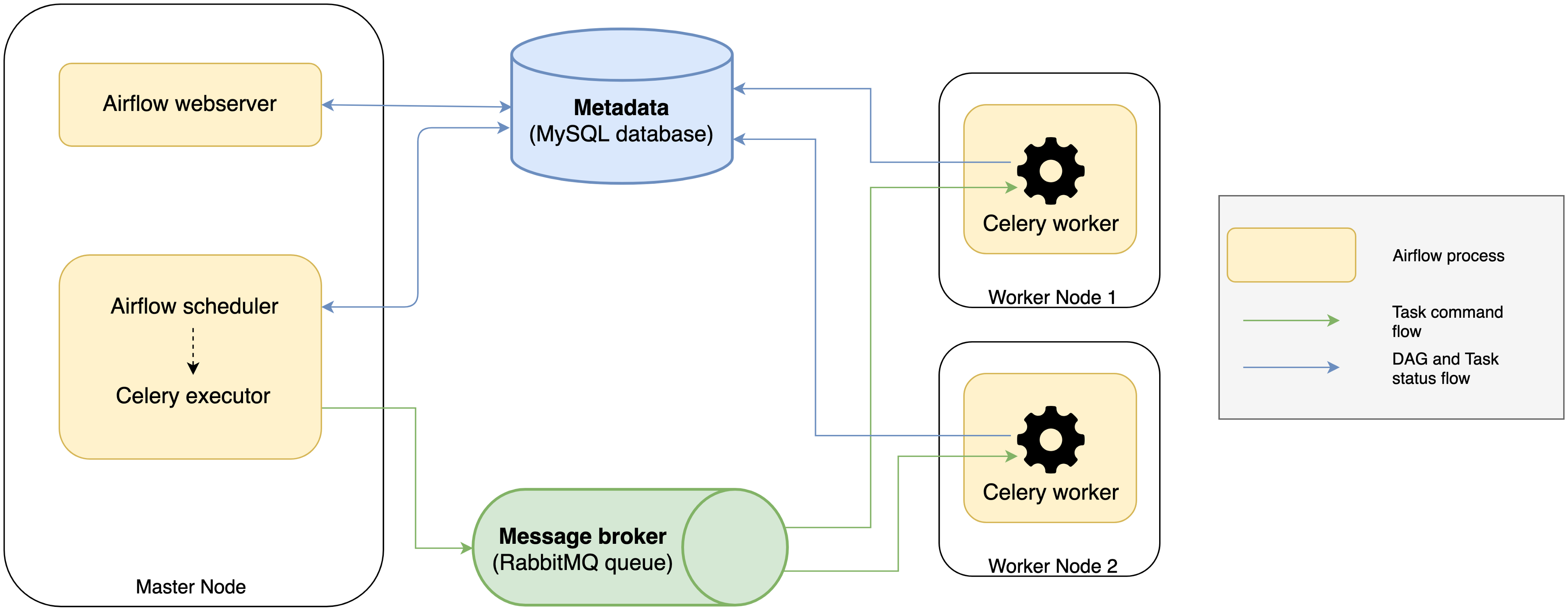
2019年12月18日 Apache Kafka 2.4 正式发布了,这个版本有很多新功能,本文将介绍这个版本比较重要的功能,完整的更新可以参见 release notes如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoopKafka broker, producer, 以及 consumer 新功能KIP-392: 允许消费者从最近的副本获取数据在 Kafka 2.4 版本之前,消费者 w397090770 5年前 (2019-12-25) 1585℃ 0评论4喜欢
Delta Lake 是数砖公司在2017年10月推出来的一个项目,并于2019年4月24日在美国旧金山召开的 Spark+AI Summit 2019 会上开源的一个存储层。它是 Databricks Runtime 重要组成部分。为 Apache Spark 和大数据 workloads 提供 ACID 事务能力,其通过写和快照隔离之间的乐观并发控制(optimistic concurrency control),在写入数据期间提供一致性的读取,从而为构 w397090770 5年前 (2019-12-24) 4437℃ 0评论8喜欢
Apache Hudi 对个人和组织何时有用如果你希望将数据快速提取到HDFS或云存储中,Hudi可以提供帮助。另外,如果你的ETL /hive/spark作业很慢或占用大量资源,那么Hudi可以通过提供一种增量式读取和写入数据的方法来提供帮助。作为一个组织,Hudi可以帮助你构建高效的数据湖,解决一些最复杂的底层存储管理问题,同时将数据更快 w397090770 5年前 (2019-12-23) 1942℃ 0评论2喜欢
Facebook 经常使用分析来进行数据驱动的决策。在过去的几年里,用户和产品都得到了增长,使得我们分析引擎中单个查询的数据量达到了数十TB。我们的一些批处理分析都是基于 Hive 平台(Apache Hive 是 Facebook 在2009年贡献给社区的)和 Corona( Facebook 内部的 MapReduce 实现)进行的。Facebook 还针对包括 Hive 在内的多个内部数据存储,继续 w397090770 5年前 (2019-12-19) 1784℃ 0评论10喜欢
Delta Lake 0.5.0 于2019年12月13日正式发布,正式版本可以到 这里 下载使用。这个版本支持多种查询引擎查询 Delta Lake 的数据,比如常见的 Hive、Presto 查询引擎。并发操作得到改进。当然,这个版本还是不支持直接使用 SQL 去增删改查 Delta Lake 的数据,这个可能得等到明年1月的 Apache Spark 3.0.0 的发布。好了,下面我们来详细介绍这个版本 w397090770 5年前 (2019-12-15) 1779℃ 0评论2喜欢
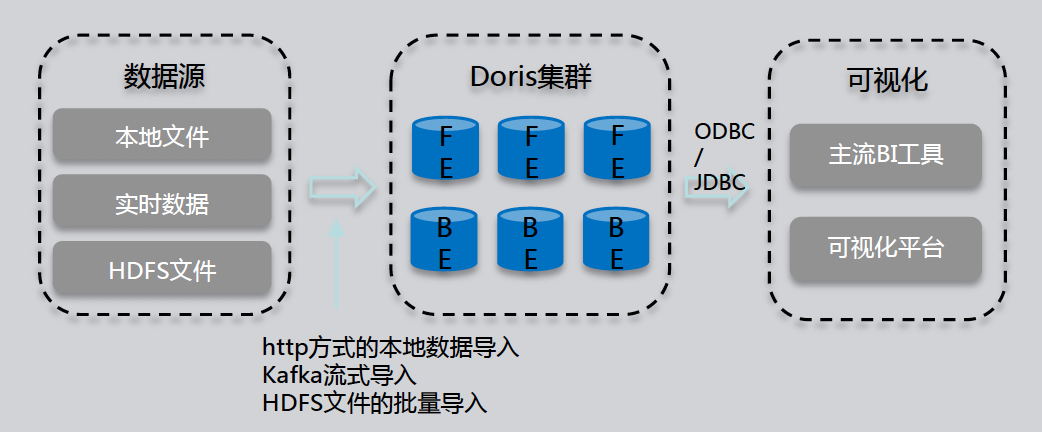
Apache Doris 简介Doris(原百度 Palo)是一款基于大规模并行处理技术的分布式 SQL 数据库,由百度在 2017 年开源,2018 年 8 月进入 Apache 孵化器。本次将主要从以下三部分介绍 Apache Doris.Doris 定位:即 Doris 所要面临的业务场景及解决的问题Doris 关键技术Doris 案例介绍01 Doris 定位实时数据仓库 Doris产品定位我们首先看一下 w397090770 5年前 (2019-12-11) 2982℃ 0评论4喜欢
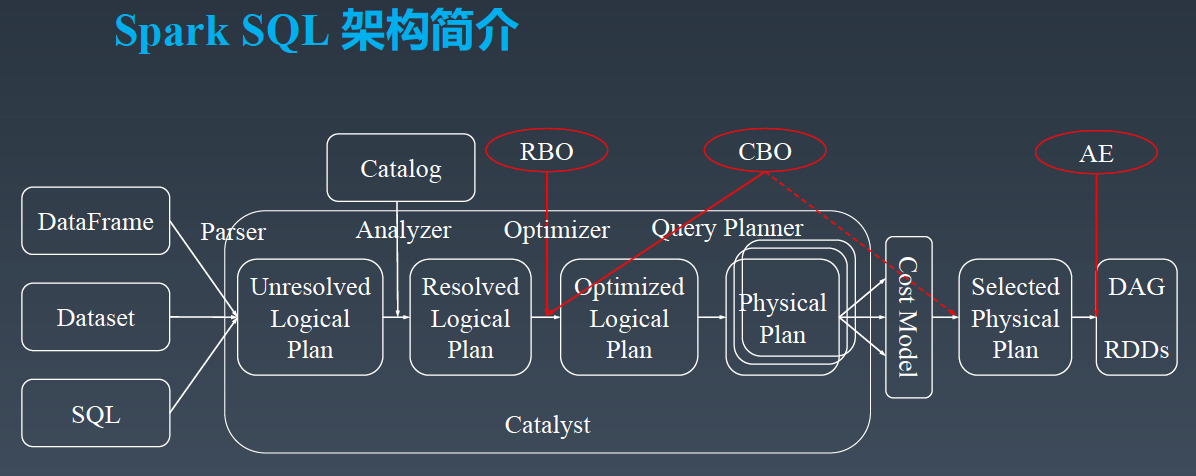
以下是字节跳动数据仓库架构负责人郭俊的分享主题沉淀,《字节跳动在Spark SQL上的核心优化实践》。PPT 请微信关注过往记忆大数据,并回复 bd_sparksql 获取。今天的分享分为三个部分,第一个部分是 SparkSQL 的架构简介,第二部分介绍字节跳动在 SparkSQL 引擎上的优化实践,第三部分是字节跳动在 Spark Shuffle 稳定性提升和性能 w397090770 5年前 (2019-12-03) 4356℃ 0评论3喜欢