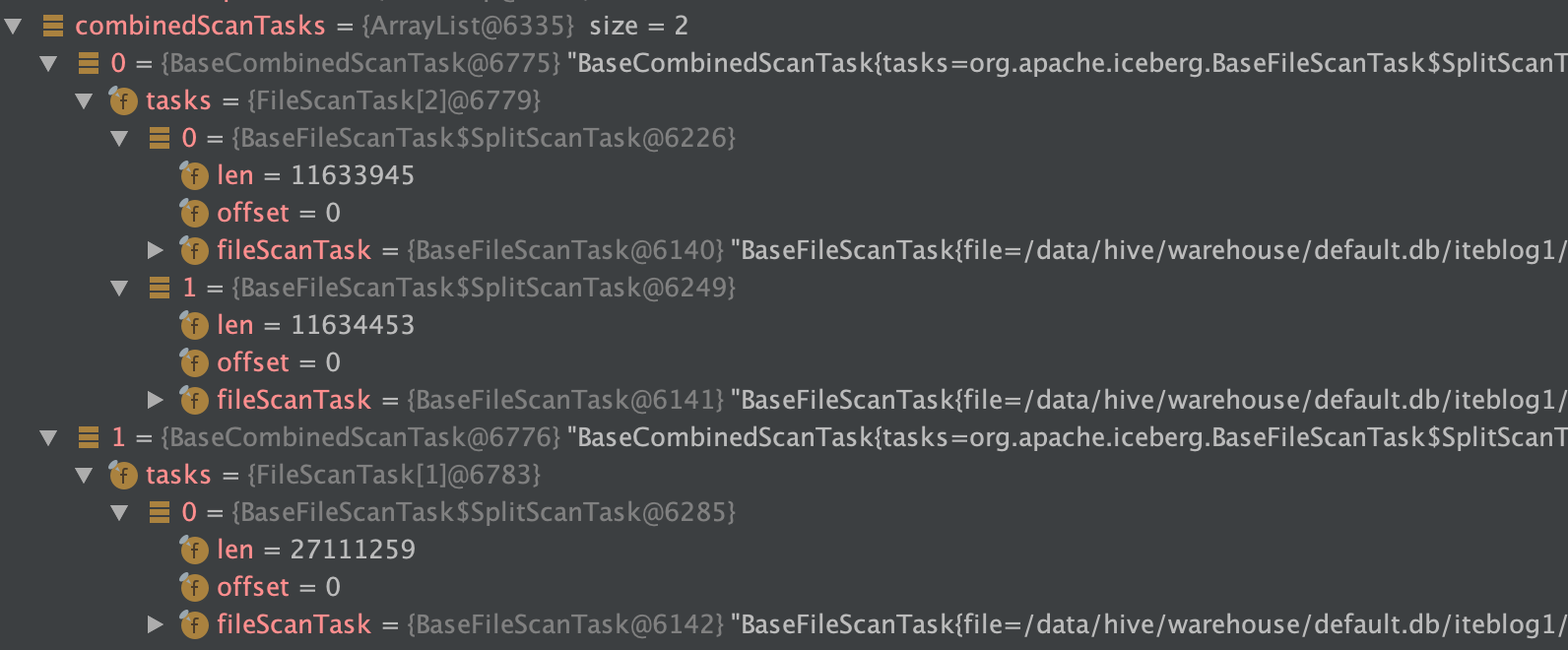
为了更好的使用 Apache Iceberg,理解其时间旅行是很有必要的,这个其实也会对 Iceberg 表的读取过程有个大致了解。不过在介绍 Apache Iceberg 的时间旅行(Time travel)之前,我们需要了解 Apache Iceberg 的底层数据组织结构。Apache Iceberg 的底层数据组织我们在 《一条数据在 Apache Iceberg 之旅:写过程分析》 这篇文章中详细地介绍了 Apache I w397090770 4年前 (2020-11-29) 3704℃ 0评论4喜欢
背景数据湖(Data Lake),湖仓一体(Data Lakehouse)俨然已经成为了大数据领域最为火热的流行词,在接受这些流行词洗礼的时候,身为技术人员我们往往会发出这样的疑问,这是一种新的技术吗,还是仅仅只是概念上的翻新(新瓶装旧酒)呢?它到底解决了什么问题,拥有什么样新的特性呢?它的现状是什么,还存在什么问题呢? w397090770 4年前 (2020-11-28) 5736℃ 0评论7喜欢
导读:Flink 从 1.9.0 开始提供与 Hive 集成的功能,随着几个版本的迭代,在最新的 Flink 1.11 中,与 Hive 集成的功能进一步深化,并且开始尝试将流计算场景与Hive 进行整合。本文主要分享在 Flink 1.11 中对接 Hive 的新特性,以及如何利用 Flink 对 Hive 数仓进行实时化改造,从而实现批流一体的目标。主要内容包括: Flink 与 Hive 集成的 w397090770 4年前 (2020-11-26) 2382℃ 0评论11喜欢
本文根据贝壳找房资深工程师仰宗强老师在2020年"面向AI技术的工程架构实践"大会上的演讲速记整理而成。1 开场大家下午好,很荣幸来到这跟大家一起分享贝壳一站式大数据开发平台的落地实践。今天的分享主要分为以下四个部分:贝壳的数据业务背景。数据开发平台探索历程。数据开发平台的整体情况介绍未来规划与 w397090770 4年前 (2020-11-25) 1679℃ 0评论5喜欢
本文来自上周(2020-11-17至2020-11-19)举办的 Data + AI Summit 2020 (原 Spark+AI Summit),主题为《Spark SQL Beyond Official Documentation》的分享,作者 David Vrba,是 Socialbakers 的高级机器学习工程师。实现高效的 Spark 应用程序并获得最大的性能为目标,通常需要官方文档之外的知识。理解 Spark 的内部流程和特性有助于根据内部优化设计查询 w397090770 4年前 (2020-11-24) 1182℃ 0评论4喜欢
本文来自车好多大数据离线存储团队相关同事的投稿,本文作者: 车好多大数据离线存储团队:冯武、王安迪。升级的背景HDFS 集群作为大数据最核心的组件,在公司承载了DW、AI、Growth 等重要业务数据的存储重任。随着业务的高速发展,数据的成倍增加,HDFS 集群出现了爆炸式的增长,使用率一直处于很高的水位。同时 HDFS文件 w397090770 4年前 (2020-11-24) 1401℃ 0评论2喜欢
在 《一条数据在 Apache Iceberg 之旅:写过程分析》 这篇文章中我们分析了 Apache Iceberg 写数据的源码。如下是我们使用 Spark 写两次数据到 Iceberg 表的数据目录布局(测试代码在 这里):[code lang="bash"]/data/hive/warehouse/default.db/iteblog├── data│ └── ts_year=2020│ ├── id_bucket=0│ │ ├── 00000-0-19603f5a-d38a w397090770 4年前 (2020-11-20) 6869℃ 6评论8喜欢
本文基于 Apache Iceberg 0.9.0 最新分支,主要分析 Apache Iceberg 中使用 Spark 2.4.6 来写数据到 Iceberg 表中,也就是对应 iceberg-spark2 模块。当然,Apache Iceberg 也支持 Flink 来读写 Iceberg 表,其底层逻辑也 Spark 类似,感兴趣的同学可以去看看。使用 Spark2 将数据写到 Apache Iceberg在介绍下面文章之前,我们先来看下在 Apache Spark 2.4.6 中写数 w397090770 4年前 (2020-11-12) 5968℃ 0评论9喜欢
HDFS集群随着使用时间的增长,难免会出现一些“性能退化”的节点,主要表现为磁盘读写变慢、网络传输变慢,我们统称这些节点为慢节点。当集群扩大到一定规模,比如上千个节点的集群,慢节点通常是不容易被发现的。大多数时候,慢节点都藏匿于众多健康节点中,只有在客户端频繁访问这些有问题的节点,发现读写变慢了, w397090770 4年前 (2020-11-12) 1646℃ 0评论7喜欢
在 Apache Iceberg 中有很多种方式可以来创建表,其中就包括使用 Catalog 方式或者实现 org.apache.iceberg.Tables 接口。下面我们来简单介绍如何使用。.如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop使用 Hive catalog从名字就可以看出,Hive catalog 是通过连接 Hive 的 MetaStore,把 Iceberg 的表存储到其中,它 w397090770 4年前 (2020-11-08) 2385℃ 0评论5喜欢