本版本迁移指南 If migrating from release older than 0.5.3, please also check the upgrade instructions for each subsequent release below. Specifically check upgrade instructions for 0.6.0. This release does not introduce any new table versions. The HoodieRecordPayload interface deprecated existing methods, in favor of new ones that also lets us pass properties at runtime. Users areencouraged to migrate out of the depr w397090770 4年前 (2021-01-31) 337℃ 0评论0喜欢
桔妹导读:在滴滴SQL任务从Hive迁移到Spark后,Spark SQL任务占比提升至85%,任务运行时间节省40%,运行任务需要的计算资源节省21%,内存资源节省49%。在迁移过程中我们沉淀出一套迁移流程, 并且发现并解决了两个引擎在语法,UDF,性能和功能方面的差异。迁移背景Spark自从2010年面世,到2020年已经经过十年的发展,现在已经发展 w397090770 4年前 (2021-01-28) 2603℃ 0评论10喜欢
1月15日,ElasticSearch 创始人、Elastic 公司 CEO Shay Banon 宣布,将把 Elasticsearch 和 Kibana 的 Apache 2.0-licensed 源码协议修改成 SSPL(Server Side Public License、服务器端公共许可证)和 Elastic License 双重协议!并且让用户可以选择申请哪个许可。Shay Banon 说这个决策是为了限制云服务提供商提供 Elasticsearch和 Kibana 服务来保护 Elastic 公司在开发免费 w397090770 4年前 (2021-01-23) 404℃ 0评论3喜欢
2021年01月21日,Apache 官方博客宣布 Apache® Superset™ 成为顶级项目。Apache® Superset™ 是一个现代化的大数据探索和可视化平台,它允许用户使用简单的无代码可视化构建器和最先进的 SQL 编辑器轻松快速地构建仪表盘(dashboards)。该项目于2015年在 Airbnb 启动,并于2017年5月进入 Apache 孵化器。说白了,其实 Apache Superset 算是一个大数据 w397090770 4年前 (2021-01-22) 784℃ 0评论1喜欢
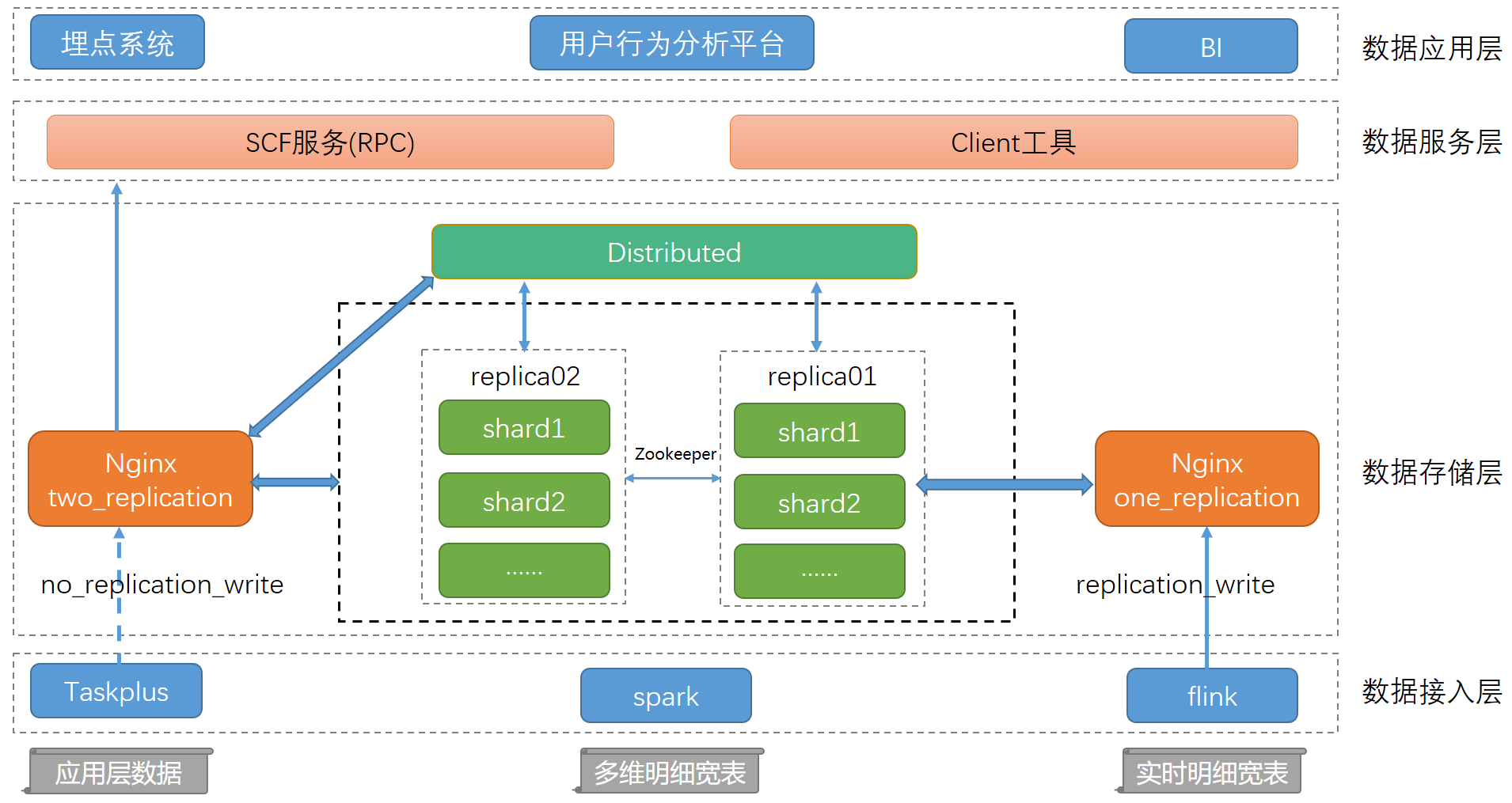
在数据量日益增长的当下,传统数据库的查询性能已满足不了我们的业务需求。而Clickhouse在OLAP领域的快速崛起引起了我们的注意,于是我们引入Clickhouse并不断优化系统性能,提供高可用集群环境。本文主要讲述如何通过Clickhouse结合大数据生态来定制一套完善的数据分析方案、如何打造完备的运维管理平台以降低维护成本,并结合具 w397090770 4年前 (2021-01-22) 1884℃ 0评论2喜欢
由 Ahana 工程师 Vivek Bharathan、David E. Simmen 以及 George Wang 编写的《Learning and Operating Presto》图书计划在2021年11月发布,不过预览版已经可以下载了。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop图书描述Presto 社区自2012年诞生于 Facebook 后迅速发展起来。但是,即使对最有经验的工程师来说 w397090770 4年前 (2021-01-21) 527℃ 0评论2喜欢
1月15日,ElasticSearch 创始人、Elastic 公司 CEO Shay Banon 宣布,将把 Elasticsearch 和 Kibana 的 Apache 2.0-licensed 源码协议修改成 SSPL(Server Side Public License、服务器端公共许可证)和 Elastic License 双重协议!下面是 Shay Banon 修改 Elasticsearch 和 Kibana 开源协议的全文翻译。注:下面的我们是指 Elastic 公司(或 Shay Banon)我们正在将 ElasticSearch w397090770 4年前 (2021-01-17) 1196℃ 0评论4喜欢
Spark 3.0 为我们带来了许多令人期待的特性。动态分区裁剪(dynamic partition pruning)就是其中之一。本文将通过图文的形式来带大家理解什么是动态分区裁剪。Spark 中的静态分区裁剪在介绍动态分区裁剪之前,有必要对 Spark 中的静态分区裁剪进行介绍。在标准数据库术语中,裁剪意味着优化器将避免读取不包含我们正在查找的数 w397090770 4年前 (2021-01-06) 1307℃ 0评论5喜欢
最近,Delta Lake 发布了一项新功能,也就是支持直接使用 Scala、Java 或者 Python 来查询 Delta Lake 里面的数据,这个是不需要通过 Spark 引擎来实现的。Scala 和 Java 读取 Delta Lake 里面的数据是通过 Delta Standalone Reader 实现的;而 Python 则是通过 Delta Rust API 实现的。Delta Lake 是一个开源存储层,为数据湖带来了可靠性。Delta Lake 提供 ACID 事务 w397090770 4年前 (2021-01-05) 1162℃ 0评论0喜欢
使用 MAC 写移动硬盘的时候会出现 Read-only file system,我们可以使用下面方法来解决。[code code="bash"]iteblog: iteblog $ diskutil info /Volumes/Seagate\ Backup\ Plus\ Drive/ Device Identifier: disk2s1 Device Node: /dev/disk2s1[/code]记下上面的 Device Node。然后使用下面命令弹出我们插入的移动硬盘:[code code="bash"]iteblog: iteblog $ hdiutil eje w397090770 4年前 (2021-01-05) 2362℃ 0评论2喜欢