FFmpeg 是一套可以用来记录、转换数字音频、视频,并能将其转化为流的开源计算机程序,采用 LGPL 或 GPL 许可证。它提供了录制、转换以及流化音视频的完整解决方案。它包含了非常先进的音频/视频编解码库 libavcodec,为了保证高可移植性和编解码质量,libavcodec 里很多 code 都是从头开发的。如果想及时了解Spark、Hadoop或者HBase相 w397090770 4年前 (2021-04-30) 853℃ 0评论2喜欢
With MongoDB 3.6 the query language gains a new level of expressivity: you can now make use of aggregation expressions in a query using the $expr operator. This feature allows you to take full advantage of all expression operators within all queries, much of which previously had to be done within application logic or was restricted to the aggregation pipeline. $expr offers better performance than the $where operator, which while still a w397090770 4年前 (2021-04-27) 2386℃ 0评论2喜欢
Apache Kafka 是一个开源流处理平台,如今有超过30%的财富500强企业使用该平台。Kafka 有很多特性使其成为事件流平台(event streaming platform)的事实上的标准。在这篇博文中,我将介绍每个 Kafka 开发者都应该知道的五件事,这样在使用 Kafka 就可以避免很多问题。Tip #1 理解消息传递和持久性保证对于数据持久性(data durability), w397090770 4年前 (2021-04-18) 1064℃ 0评论4喜欢
iceberg 详细设计Apache iceberg 是Netflix开源的全新的存储格式,我们已经有了parquet、orc、arvo等非常优秀的存储格式以后,Netfix为什么还要设计出iceberg呢?和parquet、orc等文件格式不同, iceberg在业界被称之为Table Foramt,parquet、orc、avro等文件等格式帮助我们高效的修改、读取单个文件;同样Table Foramt帮助我们高效的修改和读取一类文件 w397090770 4年前 (2021-04-15) 2307℃ 0评论6喜欢
迁移指南如果从 0.5.3 以下版本迁移,请检查这个版本后面的其他版本的升级说明。如果需要升级到 0.8 版本,请参阅 0.6.0 版本的升级指南,因为本版本没有引入新的表版本(table versions)HoodieRecordPayload接口不建议使用现有方法,而推荐使用新方法,该方法还允许我们在运行时传递属性。 鼓励用户从不建议使用的方法中迁移 w397090770 4年前 (2021-04-14) 920℃ 0评论2喜欢
Apache Kafka 的核心设计是日志(Log)—— 一个简单的数据结构,使用顺序操作。以日志为中心的设计带来了高效的磁盘缓冲和 CPU 缓存使用、预取、零拷贝数据传输和许多其他好处,从而使 Kafka 能够提供高效率和吞吐量的功能。对于那些刚接触 Kafka 的人来说,主题(topic)以及提交日志的底层实现通常是他们学习的第一件事。但 w397090770 4年前 (2021-04-11) 775℃ 0评论4喜欢
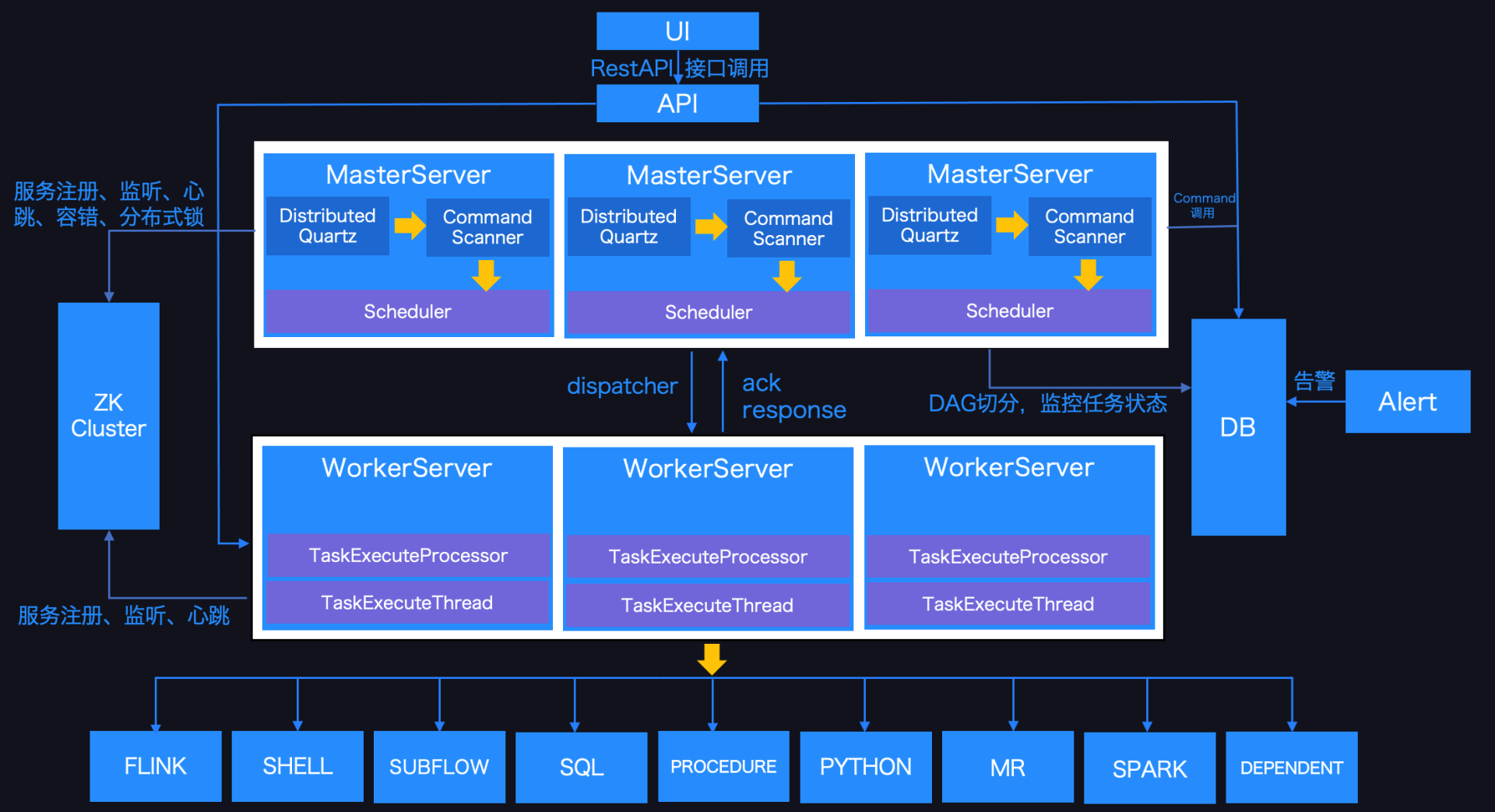
全球最大的开源软件基金会 Apache 软件基金会(以下简称 Apache)于北京时间 2021年4月9日在官方渠道宣布Apache DolphinScheduler 毕业成为Apache顶级项目。这是首个由国人主导并贡献到 Apache 的大数据工作流调度领域的顶级项目。DolphinScheduler™ 已经是联通、IDG、IBM、京东物流、联想、新东方、诺基亚、360、顺丰和腾讯等 400+ 公司在使用 w397090770 4年前 (2021-04-09) 1868℃ 0评论3喜欢
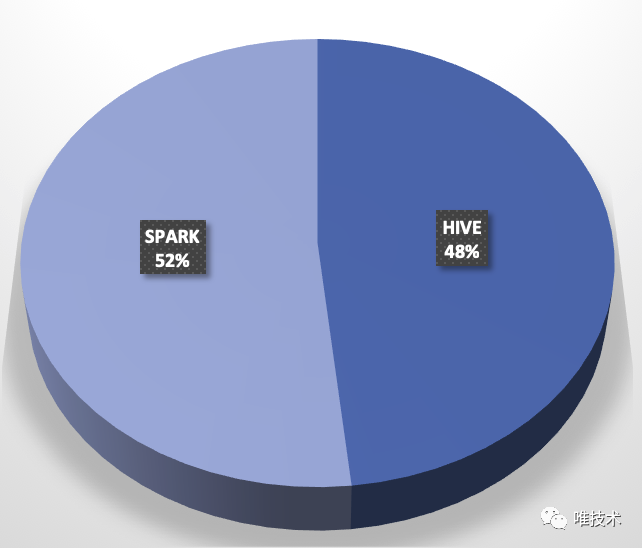
导读.bordered th, .bordered td{text-align:left;}唯品会离线平台SPARK2.3.2无缝升级到SPARK3.0.1版本,完全做到了对用户透明,目前正按着既定方案进行升级,新的版本SPARK CORE/SQL/PySpark进行了优化和BugFix,并且Merge了SPARK vip 2.3.2 重要Patch,在性能和易用性上比旧版本都有较大提升。这篇文章介绍了我们升级SPARK过程中遇到的挑战和思考, w397090770 4年前 (2021-04-05) 1331℃ 0评论4喜欢