《Get Programming with Scala》于2021年7月由 Manning 出版,ISBN 为 9781617295270 全书共 560 页。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop图书介绍The perfect starting point for your journey into Scala and functional programming.In Get Programming in Scala you will learn:Object-oriented principles in ScalaExpress program designs in fun w397090770 3年前 (2021-08-30) 357℃ 0评论4喜欢
本次的分享内容分成四个部分: 1.汽车之家离线计算平台现状2.平台构建过程中遇到的问题3.基于构建过程中问题的解决方案4.离线计算平台未来规划 汽车之家离线计算平台现状 1. 汽车之家离线计算平台发展历程如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据 2013年的时候汽 w397090770 3年前 (2021-08-30) 612℃ 0评论4喜欢
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据过往记忆大数据备注:以下的我们均代表 Uber 的 Hadoop 运维团队。介绍随着 Uber 业务的增长,Uber 公司在 5 年内将 Apache Hadoop(本文简称为“Hadoop”)部署扩展到 21000 台以上的节点,以支持各种分析和机器学习用例。我们组建了一支拥有各 w397090770 3年前 (2021-08-22) 771℃ 0评论4喜欢
最近发现离线任务对一个增量Hive表的查询越来越慢,这引起了我的注意,我在cmd窗口手动执行count操作查询发现,速度确实很慢,才不到五千万的数据,居然需要300s,这显然是有问题的,我推测可能是有小文件。我去hdfs目录查看了一下该目录:发现确实有很多小文件,有480个小文件,我觉得我找到了问题所在,那么合并一 zz~~ 3年前 (2021-08-20) 1249℃ 0评论4喜欢
摘要:本文整理自 58 同城实时计算平台负责人冯海涛在 Flink Forward Asia 2020 分享的议题《Flink 在 58 同城应用与实践》,内容包括: 实时计算平台架实时 SQL 建设Storm 迁移 Flink 实践一站式实时计算平台后续规划如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据实时计算平台架构 w397090770 3年前 (2021-08-17) 315℃ 0评论2喜欢
随着越来越多的公司广泛部署 Presto,Presto 不仅用于查询,还用于数据摄取和 ETL 作业。所有很有必要提高 Presto 文件写入的性能,尤其是流行的列文件格式,如 Parquet 和 ORC。本文我们将介绍 Presto 的全新原生的 Parquet writer ,它可以直接将 Presto 的列式数据结构写到 Parquet 的列式格式,最高可提高6倍的吞吐量,并减少 CPU 和内存开销 w397090770 3年前 (2021-08-14) 585℃ 0评论2喜欢
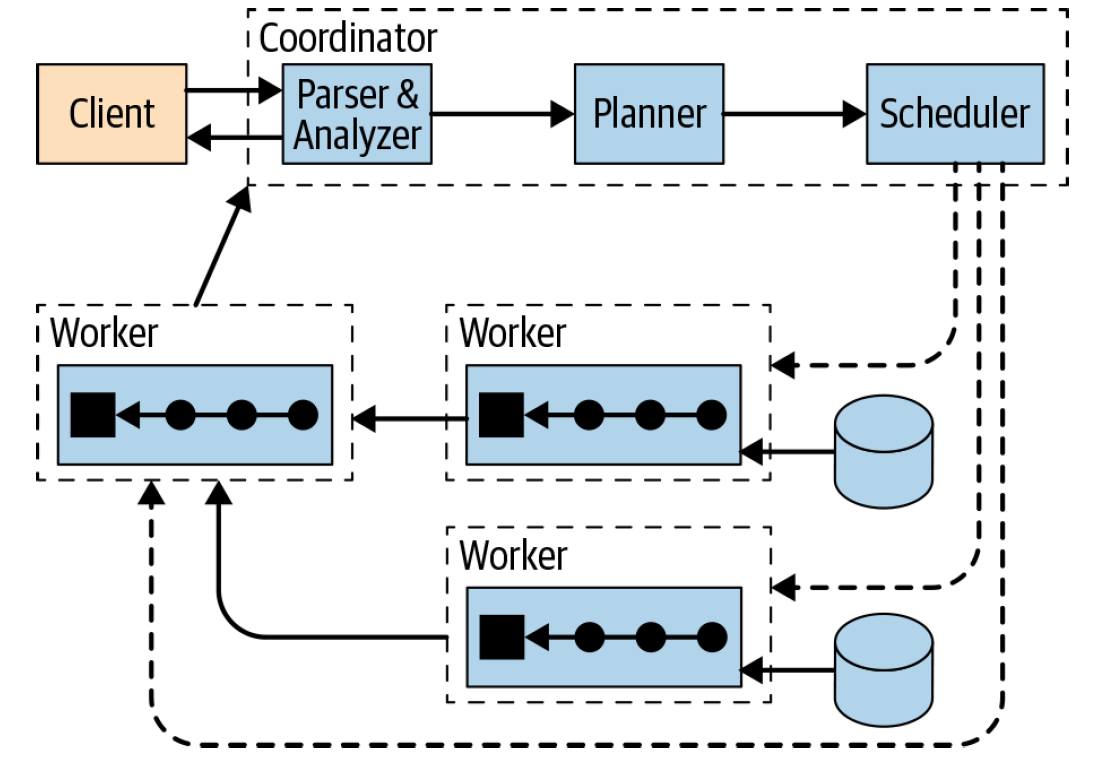
背景在介绍 Presto 计算下推之前,我们先来回顾一下 Presto 从对应的 Connector 上读取数据的流程,过程如下:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据从上图可以看出,client 提交 SQL 到 Coordinator 上,Coordinator 接收到 SQL 之后,会进行 SQL 语法语义解析,生成逻辑计划树,然后经过 pla w397090770 4年前 (2021-08-12) 1670℃ 0评论4喜欢
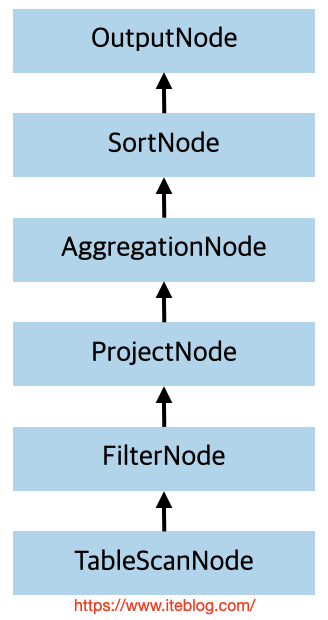
和其他计算引擎一样,一条 SQL 从客户的提交到 Coordinator 端经过 SqlParser 进行词法和语法解析形成 AST 树,然后经过 Analyzer 进行语义分析,生成了逻辑计划(LogicalPlan);接着经过优化器处理(优化规则都是在 PlanOptimizers 里面定义好的,然后在 LogicalPlanner 里面循环遍历每个规则)生成物理计划(PhysicalPlan);最后使用 PlanFragmenter 并 w397090770 4年前 (2021-08-08) 1260℃ 0评论3喜欢
Apache Hudi 是一种数据湖平台技术,它提供了构建和管理数据湖所需的几个功能。hudi 提供的一个关键特性是自我管理文件大小,这样用户就不需要担心手动维护表。拥有大量的小文件将使计算更难获得良好的查询性能,因为查询引擎不得不多次打开/读取/关闭文件以执行查询。但是对于流数据湖用例来说,可能每次都只会写入很少的 w397090770 4年前 (2021-08-03) 1130℃ 0评论1喜欢
在安装完 JDK 之后,会自带安装一些常用的小工具,而 jmap 就是其中一个比较常用的。jmap 打印给定进程、core file 或远程调试服务器的共享对象内存映射或堆内存细节。我们可以查看下 jmap 的命令使用:[code lang="bash"]iteblog@iteblog.com:~|⇒ jmapUsage: jmap [option] <pid> (to connect to running process) jmap [option] <executable <co w397090770 4年前 (2021-08-02) 869℃ 0评论0喜欢