世界上大多数事物的发展规律是相似的,在最开始往往都会出现相对通用的方案解决绝大多数的问题,随后会出现为某一场景专门设计的解决方案,这些解决方案不能解决通用的问题,但是在某些具体的领域会有极其出色的表现。而在计算领域中,CPU(Central Processing Unit)和 GPU(Graphics Processing Unit)分别是通用的和特定的方案,前 zz~~ 4年前 (2021-09-24) 182℃ 0评论3喜欢
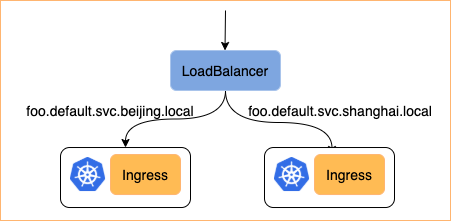
基于Kubefed的多集群管理实践多集群场景主要分以下几个方面:1)高可用低延时:应用部署到不同的集群去做高可用2)容灾备份:特别是针对于数据库这类的应用 在a集群对外提供服务的同时给b集群做一次备份 这样在发生故障的时候 可以无缝的迁移到另一个集群去3)业务隔离:尽管kubernetes提供了ns级别的隔离, zz~~ 4年前 (2021-09-24) 275℃ 0评论0喜欢
Apache Kafka 3.0 于2021年9月21日正式发布。本文将介绍这个版本的新功能。以下文章翻译自 《What's New in Apache Kafka 3.0.0》。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据我很高兴地代表 Apache Kafka® 社区宣布 Apache Kafka 3.0 的发布。 Apache Kafka 3.0 是一个大版本,其引入了各种新功能、API 发生重 w397090770 4年前 (2021-09-24) 651℃ 0评论2喜欢
导读:本文主要介绍Flink实时计算在bilibili的优化,将从以下四个方面展开: 1、Flink-connector稳定性优化 2、Flink sql优化 3、Flink-runtime优化 4、对未来的展望 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据 概述首先介绍下Flink实时计算在b站的应用场景。在b站,Flink on yarn w397090770 4年前 (2021-09-23) 920℃ 0评论4喜欢
在 LinkedIn,我们使用 Hadoop 作为大数据分析和机器学习的基础组件。随着数据量呈指数级增长,并且公司在机器学习和数据科学方面进行了大量投资,我们的集群规模每年都在翻倍,以匹配计算工作负载的增长。我们最大的集群现在有大约 10,000 个节点,是全球最大(如果不是最大的)Hadoop 集群之一。多年来,扩展 Hadoop YARN 已成为 w397090770 4年前 (2021-09-18) 581℃ 0评论4喜欢
在 LinkedIn,我们非常依赖离线数据分析来进行数据驱动的决策。多年来,Apache Spark 已经成为 LinkedIn 的主要计算引擎,以满足这些数据需求。凭借其独特的功能,Spark 为 LinkedIn 的许多关键业务提供支持,包括数据仓库、数据科学、AI/ML、A/B 测试和指标报告。需要大规模数据分析的用例数量也在快速增长。从 2017 年到现在,LinkedIn 的 S w397090770 4年前 (2021-09-08) 1084℃ 0评论4喜欢
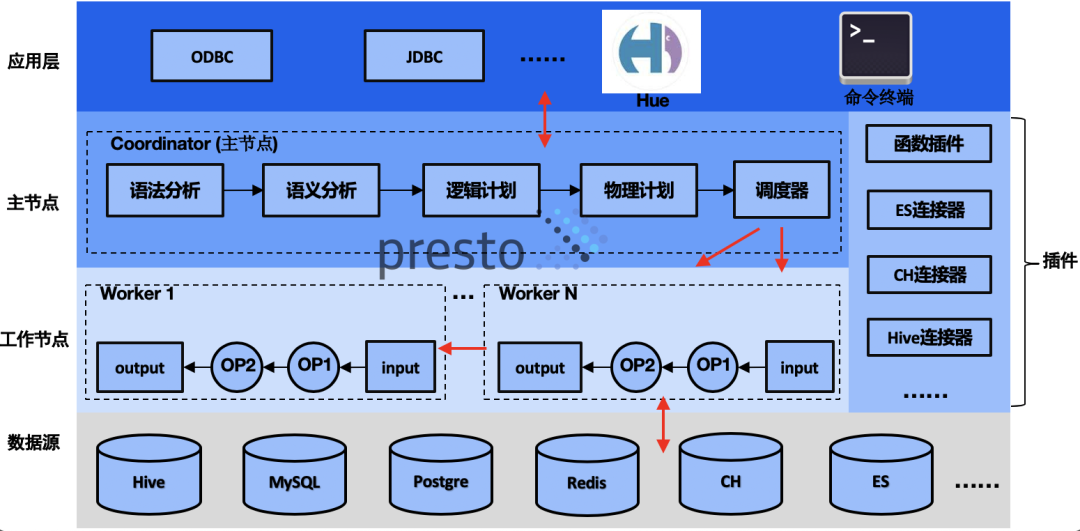
文章来源团队:腾讯医疗资讯与服务部-技术研发中心 前言:随着产品矩阵和团队规模的扩张,跨业务、APP的数据处理、分析总是不可避免。一个显而易见的问题就是异构数据源的连通。我们基于PrestoDB构建了业务线内适应腾讯生态的联邦查询引擎,连通了部门内部20+数据源实例,涵盖了90%的查询场景。同时,我们参与公司级的Pre w397090770 4年前 (2021-09-08) 581℃ 0评论1喜欢
NVMe是Non-Volatile Memory express(非易失性内存主机控制器接口规范)的简称,它是一种协议,能够使固态硬盘(SSD)运行得更快,如今在企业用户中已越来越流行。理解什么是NVMe的最简单的方法就是打个比方——假设你刚买了一辆跑车,速度能达到400公里每小时,是你以前那辆老汽车的3到4倍。唯一的问题是,普通的道路是无法允许以这 w397090770 4年前 (2021-09-07) 1011℃ 0评论1喜欢
随着 Uber 业务的扩张,为其提供支持的基础数据呈指数级增长,因此处理成本也越来越高。 当大数据成为我们最大的运营开支之一时,我们开始了一项降低数据平台成本的举措,该计划将挑战分为三部分:平台效率、供应和需求。 本文将讨论我们为提高数据平台效率和降低成本所做的努力。如果想及时了解Spark、Hadoop或者HBase w397090770 4年前 (2021-09-05) 471℃ 0评论2喜欢
导读:京东OLAP采取ClickHouse为主Doris为辅的策略,有3000台服务器,每天亿次查询万亿条数据写入,广泛服务于各个应用场景,经过历次大促考验,提供了稳定的服务。本文介绍了ClickHouse在京东的高可用实践,包括选型过程、集群部署、高可用架构、问题和规划。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公共帐 w397090770 4年前 (2021-09-03) 789℃ 0评论0喜欢