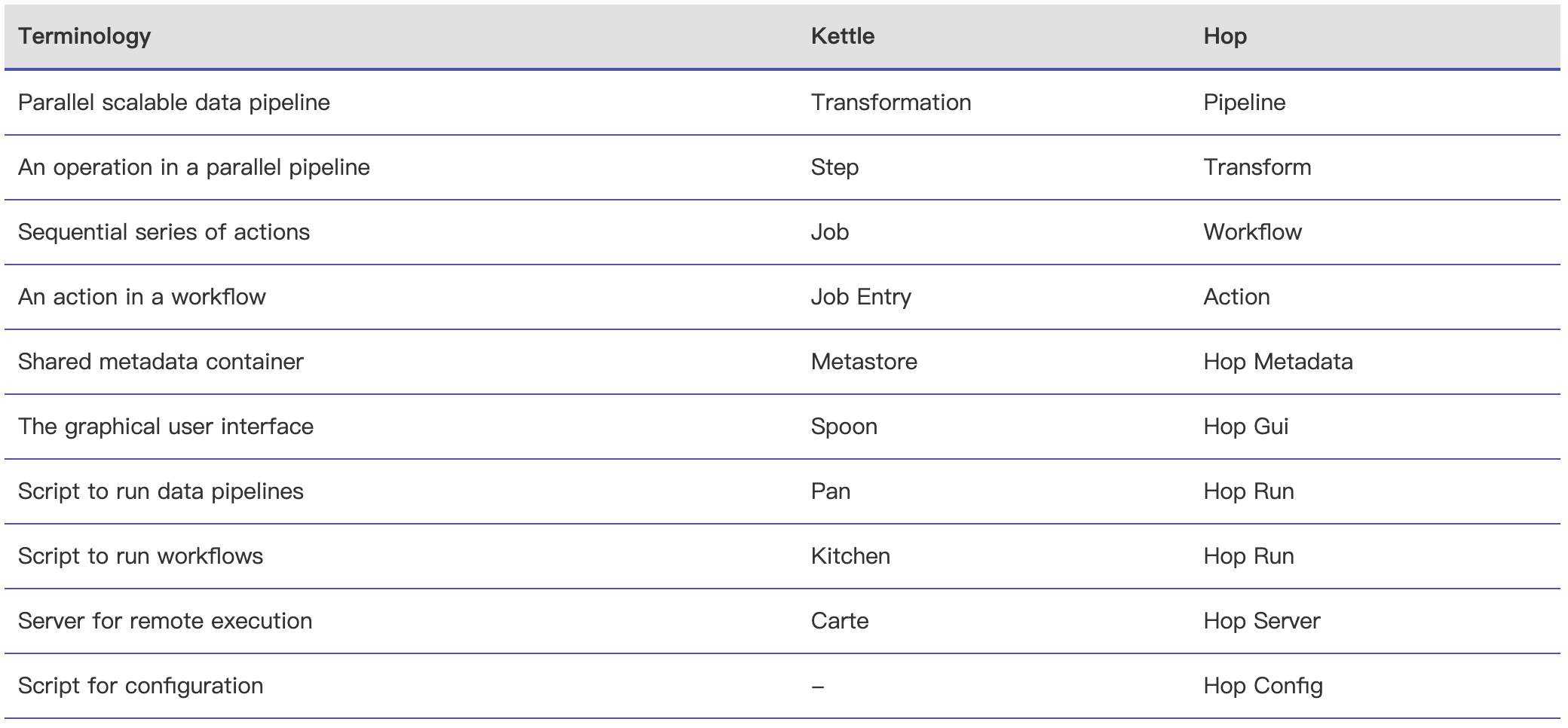
Apache Hop(Hop Orchestration Platform 的首字母缩写)是一种数据编排(data orchestration )和数据工程平台(data engineering platform),旨在促进数据和元数据编制。Hop 可以让我们专注于问题的解决,而不受技术的阻碍。该项目起源于 Kettle,经过数年的重构,并于2020年9月进入 Apache 孵化器;2022年1月18日正式成为 Apache 顶级项目。Hop 允许数据 w397090770 3年前 (2022-01-22) 1649℃ 0评论3喜欢
2022年01月10日,来自 Cloudera 的工程师、Apache Ambari PMC 主席 Jayush Luniya 给 Ambari 社区发送了一封名为《[VOTE] Move Apache Ambari to Attic》的邮件:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据邮件内容显示,在过去的两年里,Ambari 只发布了一个版本(2.7.6),大多数提交者(Committer)和 PMC 成员 w397090770 3年前 (2022-01-16) 422℃ 0评论2喜欢
时间过得真快,2021年就过去了,又到了一年总结的时候了。本文将延续之前的惯例来总结一下过去一年大数据相关的项目顺利毕业成 Apache 顶级项目。在2021年一共有四个大数据相关项目顺利毕业成顶级项目,主要是 Apache® DataSketches™、Apache® Gobblin™、Apache® DolphinScheduler™ 以及 Apache® Pinot™;同时有两个项目进入到 Apache 孵化器, w397090770 3年前 (2022-01-03) 1476℃ 0评论5喜欢
Apache Gobblin 是一个用于流数据和批处理数据生态系统的分布式大数据集成框架。可以简化大数据集成里面的常见问题,比如数据摄取、复制、组织以及生命周期管理等。该项目2014年起源于 LinkedIn,2015年开源,2017年2月进入 Apache 孵化器,2021年02月16日正式毕业成为 Apache 顶级项目。如果想及时了解Spark、Hadoop或者HBase相关的文章, w397090770 3年前 (2022-01-01) 1289℃ 0评论4喜欢
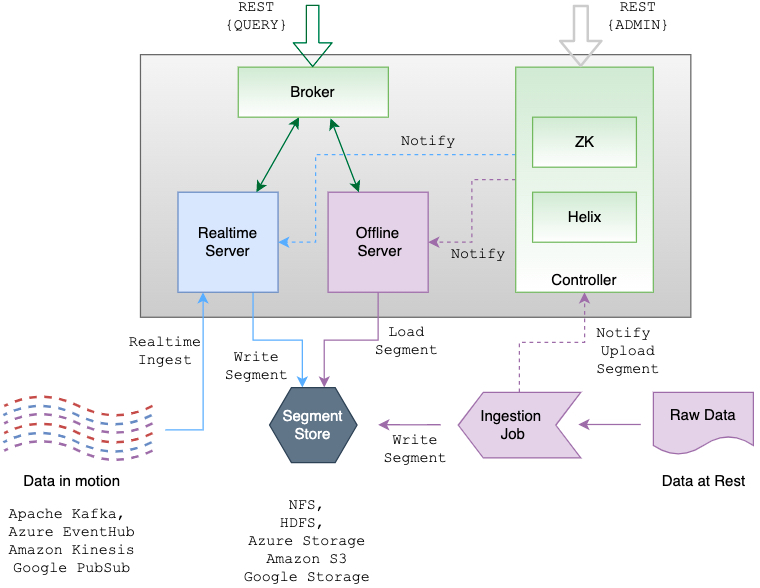
Apache Pinot 是一个分布式实时分布式 OLAP 数据存储,旨在以高吞吐量和低延迟提供可扩展的实时分析。该项目最初于 2013 年由 LinkedIn 创建,2015 年开源,于 2018 年 10 月进入 Apache 孵化器,2021年08月02日正式毕业成为 Apache 顶级项目。Apache Pinot 可以直接从流数据源(例如 Apache Kafka 和 Amazon Kinesis)中提取,并使事件可用于即时查询。 w397090770 3年前 (2022-01-01) 1057℃ 0评论1喜欢