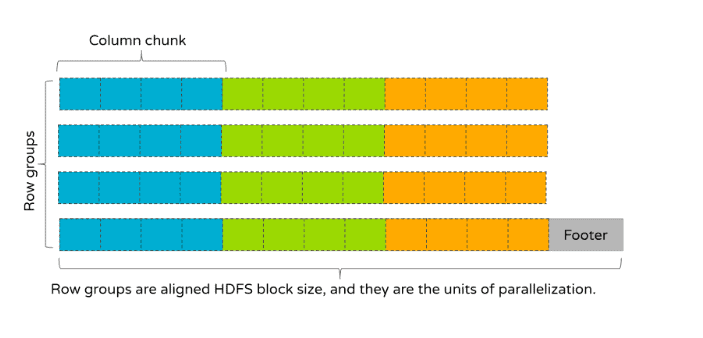
Apache Parquet通过 Parquet Page Indexes 加速查询性能 分析型SQL引擎(如Apache Impala)在进行大型表扫描和聚合查询工作负载时非常出色。在大数据生态系统中,单个表的大小可达PB(拍字节)级别,因此要实现快速的查询响应时间,就需要依据WHERE或HAVING子句中的条件对表数据进行智能过滤。通常会使用一个或多个列来对大型表进行分区,这些列能够有效地对数据进行范围过滤。例 w397090770 3个月前 (01-13) 95℃ 0评论0喜欢