背景我们基于 Apache Hadoop® 的数据平台以最小的延迟支持了数百 PB 的分析数据,并将其存储在基于 HDFS 之上的数据湖中。我们使用 Apache Hudi™ 作为我们表的维护格式,使用 Apache Parquet™ 作为底层文件格式。我们的数据平台利用 Apache Hive™、Apache Presto™ 和 Apache Spark™ 进行交互和长时间运行的查询,满足 Uber 不同团队的各种需求。 w397090770 3年前 (2022-03-13) 2576℃ 0评论1喜欢
背景 随着公司这两年业务的迅速扩增,业务数据量和数据处理需求也是呈几何式增长,这对底层的存储和计算等基础设施建设提出了较高的要求。本文围绕计算集群资源使用和资源调度展开,将带大家了解集群资源调度的整体过程、面临的问题,以及我们在底层所做的一系列开发优化工作。资源调度框架---YarnYarn的总体结 zz~~ 3年前 (2021-11-16) 584℃ 0评论0喜欢
前言 OPPO的大数据离线计算发展,经历了哪些阶段?在生产中遇到哪些经典的大数据问题?我们是怎么解决的,从中有哪些架构上的升级演进?未来的OPPO离线平台有哪些方向规划?今天会给大家一一揭秘。OPPO大数据离线计算发展历史大数据行业发展阶段 一家公司的技术发展,离不开整个行业的发展背景。我们简短回归 w397090770 3年前 (2021-10-29) 775℃ 0评论2喜欢
随着 Uber 业务的扩张,为其提供支持的基础数据呈指数级增长,因此处理成本也越来越高。 当大数据成为我们最大的运营开支之一时,我们开始了一项降低数据平台成本的举措,该计划将挑战分为三部分:平台效率、供应和需求。 本文将讨论我们为提高数据平台效率和降低成本所做的努力。如果想及时了解Spark、Hadoop或者HBase w397090770 3年前 (2021-09-05) 458℃ 0评论2喜欢
本文根据贝壳找房资深工程师仰宗强老师在2020年"面向AI技术的工程架构实践"大会上的演讲速记整理而成。1 开场大家下午好,很荣幸来到这跟大家一起分享贝壳一站式大数据开发平台的落地实践。今天的分享主要分为以下四个部分:贝壳的数据业务背景。数据开发平台探索历程。数据开发平台的整体情况介绍未来规划与 w397090770 4年前 (2020-11-25) 1679℃ 0评论5喜欢
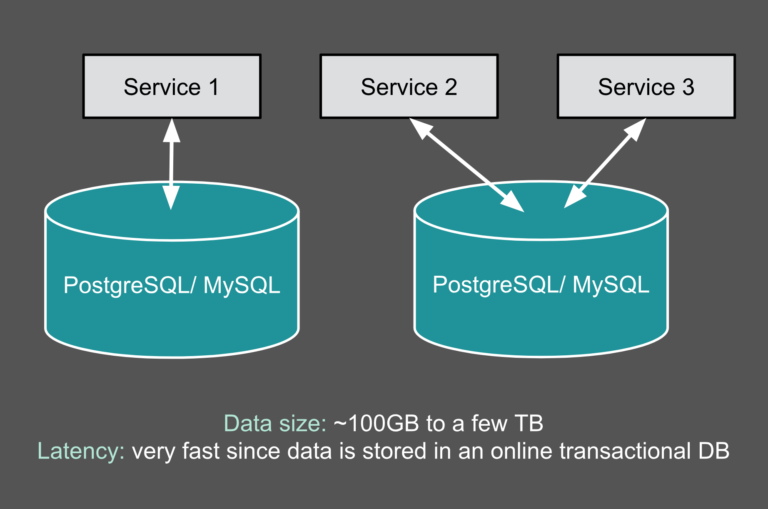
我们使用数据库可以快速访问业务数据,但是随着时间的推移,数据库会不断增长,提取信息所需的时间也会更长,数据操作成为瓶颈。这时候我们就需要对数据进行分区(partition)了。分区是将数据库或其组成元素划分为不同的独立部分。数据库分区通常是出于可管理性、性能或可用性或负载平衡的原因而进行的。在分布式数据 w397090770 5年前 (2020-05-14) 1093℃ 0评论2喜欢
这是一份迟来的年终报告,本来昨天就要发出来的,实在是没忙开,今天我就把它当作新年礼物送给各位看官,以下文章都是我结合日常工作、学习,每当“夜深人静"的时候写出来的一些小总结,希望能给大家一些技术上的帮助。关注我的朋友都知道,我在今年八月份发了一篇文章,里面整理了我五年来写在这个公众号上面的原 w397090770 5年前 (2020-01-04) 1392℃ 0评论1喜欢
Uber 致力于在全球市场上提供更安全,更可靠的运输服务。为了实现这一目标,Uber 在很大程度上依赖于数据驱动的决策,从预测高流量事件期间骑手的需求到识别和解决我们的驾驶员-合作伙伴注册流程中的瓶颈。自2014年以来,Uber 一直致力于开发大数据解决方案,确保数据可靠性,可扩展性和易用性;现在 Uber 正专注于提高他们平 w397090770 6年前 (2019-06-06) 3281℃ 0评论8喜欢
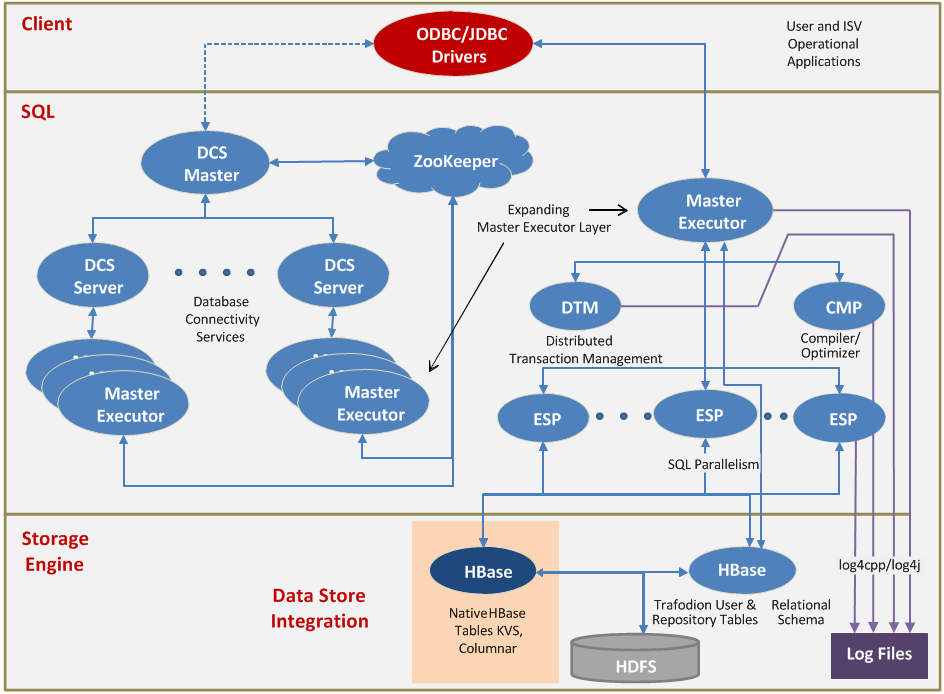
去年,我整理了2017年成功晋升为Apache TLP的大数据相关项目进行了整理,具体可以参见《盘点2017年晋升为Apache TLP的大数据相关项目》。现在已经进入了2019年了,我在这里给大家整理了2018年成功晋升为 Apache TLP 的大数据相关项目。2018年晋升成 TLP 的项目不多,总共四个,按照项目晋升的时间进行排序的。Apache Trafodion:基于 Hadoop 平 w397090770 6年前 (2019-01-02) 1597℃ 0评论4喜欢
本文主要盘点了 2017 年晋升为 Apache Top-Level Project (TLP) 的大数据相关项目,项目的介绍从孵化器毕业的时间开始排的,一共十二个。Apache Beam: 下一代的大数据处理标准Apache Beam(原名Google DataFlow)是Google在2016年2月份贡献给Apache基金会的Apache孵化项目,被认为是继MapReduce,GFS和BigQuery等之后,Google在大数据处理领域对开源社区的 w397090770 7年前 (2018-01-01) 3536℃ 0评论10喜欢