本文将介绍如何在Local模式下安装和使用Flink集群。要求(Requirements) Flink可以在Linux, Mac OS X 以及Windows等平台上运行。Local模式安装的唯一要求是安装Java 1.7.x或者更高版本。下面的操作假定是类UNIX环境,对于Windows可以参见本文的Flink on Windows章节。我们可以使用下面的命令来查看Java的版本:[code lang="bash"]java -versio w397090770 9年前 (2016-04-19) 5460℃ 0评论3喜欢
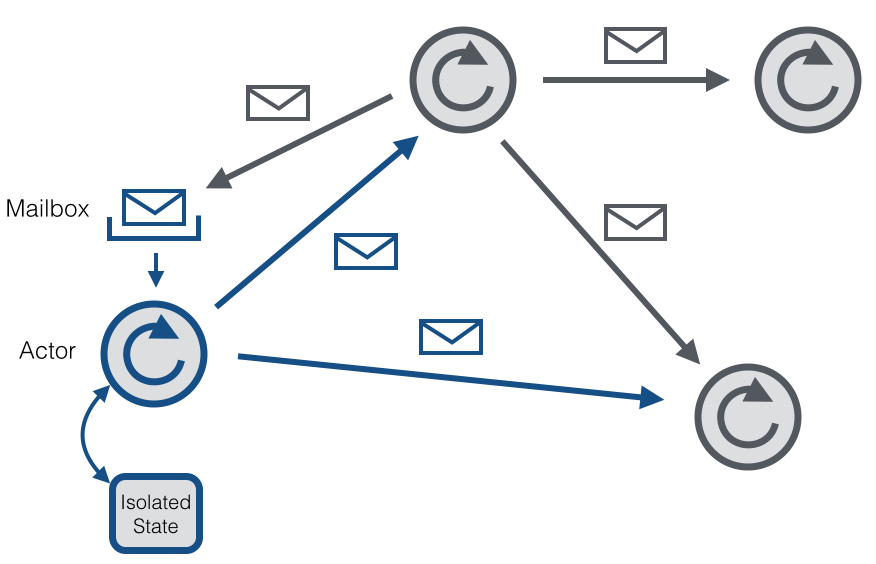
Akka与Actor 模型 Akka是一个用来开发支持并发、容错、扩展性的应用程序框架。它是actor model的实现,因此跟Erlang的并发模型很像。在actor模型的上下文中,所有的活动实体都被认为是互不依赖的actor。actor之间的互相通信是通过彼此之间发送异步消息来实现的。每个actor都有一个邮箱来存储接收到的消息。因此每个actor都维护着 w397090770 9年前 (2016-04-15) 3359℃ 0评论2喜欢
本文将介绍如何通过简单地几步来开始编写你的 Flink Scala 程序。构建工具 Flink工程可以使用不同的工具进行构建,为了快速构建Flink工程, Flink为下面的构建工具分别提供了模板: 1、SBT 2、Maven这些模板可以帮助我们组织项目结构并初始化一些构建文件。SBT创建工程1、使用Giter8可以使用下 w397090770 9年前 (2016-04-07) 10229℃ 0评论8喜欢
本文将介绍如何通过简单地几步来开始编写你的 Flink Java 程序。要求 编写你的Flink Java程序唯一的要求是需要安装Maven 3.0.4(或者更高)和Java 7.x(或者更高) 创建Flink Java工程使用下面其中一个命令来创建Flink Java工程1、使用Maven archetypes:[code lang="bash"]$ mvn archetype:generate \ -DarchetypeGrou w397090770 9年前 (2016-04-06) 13943℃ 0评论8喜欢
安装:下载并启动 Flink可以在Linux、Mac OS X以及Windows上运行。为了能够运行Flink,唯一的要求是必须安装Java 7.x或者更高版本。对于Windows用户来说,请参考 Flink on Windows 文档,里面介绍了如何在Window本地运行Flink。下载 从下载页面(http://flink.apache.org/downloads.html)下载所需的二进制包。你可以选择任何与 Hadoop/Scala 结 w397090770 9年前 (2016-04-05) 17751℃ 0评论23喜欢
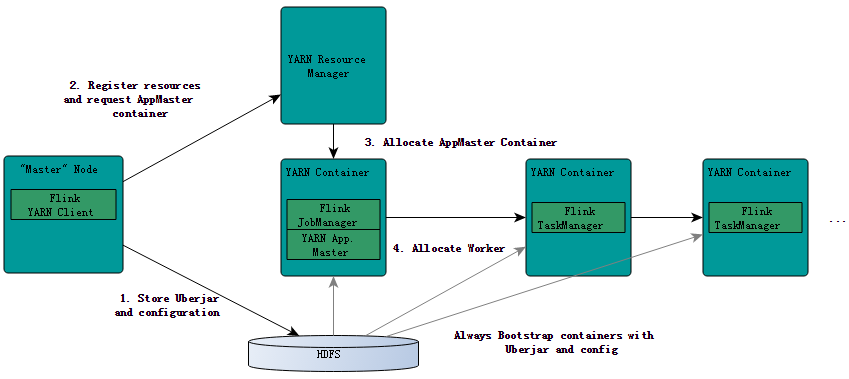
在前面(《Flink on YARN部署快速入门指南》的文章中我们简单地介绍了如何在YARN上提交和运行Flink作业,本文将简要地介绍Flink是如何与YARN进行交互的。 YRAN客户端需要访问Hadoop的相关配置文件,从而可以连接YARN资源管理器和HDFS。它使用下面的规则来决定Hadoop配置: 1、判断YARN_CONF_DIR,HADOOP_CONF_DIR或HADOOP_CONF_PATH等环境 w397090770 9年前 (2016-04-04) 6053℃ 0评论8喜欢
我们是否还需要另外一个新的数据处理引擎?当我第一次听到Flink的时候这是我是非常怀疑的。在大数据领域,现在已经不缺少数据处理框架了,但是没有一个框架能够完全满足不同的处理需求。自从Apache Spark出现后,貌似已经成为当今把大部分的问题解决得最好的框架了,所以我对另外一款解决类似问题的框架持有很强烈的怀 w397090770 9年前 (2016-04-04) 18169℃ 0评论42喜欢
Spark Streaming和Flink都能提供恰好一次的保证,即每条记录都仅处理一次。与其他处理系统(比如Storm)相比,它们都能提供一个非常高的吞吐量。它们的容错开销也都非常低。之前,Spark提供了可配置的内存管理,而Flink提供了自动内存管理,但从1.6版本开始,Spark也提供了自动内存管理。这两个流处理引擎确实有许多相似之处, w397090770 9年前 (2016-04-02) 4816℃ 0评论5喜欢
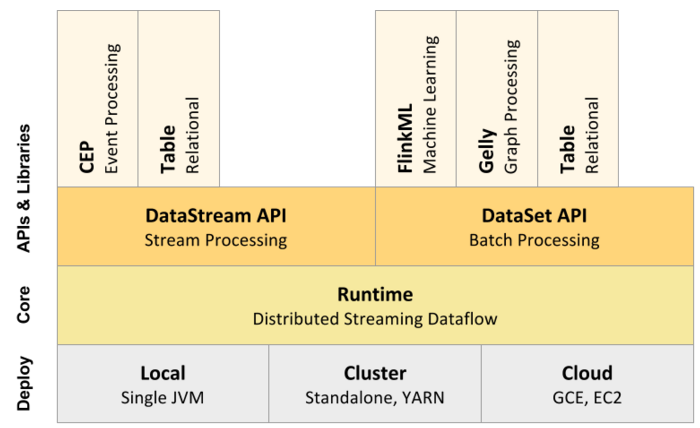
Apache Flink是一个高效、分布式、基于Java和Scala(主要是由Java实现)实现的通用大数据分析引擎,它具有分布式 MapReduce一类平台的高效性、灵活性和扩展性以及并行数据库查询优化方案,它支持批量和基于流的数据分析,且提供了基于Java和Scala的API。 从Flink官方文档可以知道,目前Flink支持三大部署模式:Local、Cluster以及Cloud w397090770 9年前 (2016-03-30) 24347℃ 6评论22喜欢
本文出自本公众号ChinaScala,由陈超所述。一、Spark能否取代Hadoop? 答: Hadoop包含了Common,HDFS,YARN及MapReduce,Spark从来没说要取代Hadoop,最多也就是取代掉MapReduce。事实上现在Hadoop已经发展成为一个生态系统,并且Hadoop生态系统也接受更多优秀的框架进来,如Spark (Spark可以和HDFS无缝结合,并且可以很好的跑在YARN上).。 w397090770 10年前 (2015-08-26) 7224℃ 1评论42喜欢