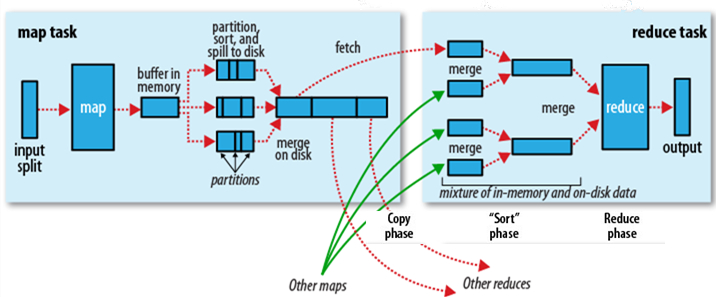
Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方。要想理解MapReduce, Shuffle是必须要了解的。我看过很多相关的资料,但每次看完都云里雾里的绕着,很难理清大致的逻辑,反而越搅越混。前段时间在做MapReduce job 性能调优的工作,需要深入代码研究MapReduce的运行机制,这才对Shuffle探了个究竟。考虑到之前我在看相关资料 w397090770 11年前 (2014-09-15) 16443℃ 7评论59喜欢
本文详细地介绍了如何将Hadoop上的Mapreduce程序转换成Spark的应用程序。有兴趣的可以参考一下:The key to getting the most out of Spark is to understand the differences between its RDD API and the original Mapper and Reducer API.Venerable MapReduce has been Apache Hadoop‘s work-horse computation paradigm since its inception. It is ideal for the kinds of work for which Hadoop was originally des w397090770 11年前 (2014-09-07) 6462℃ 1评论9喜欢
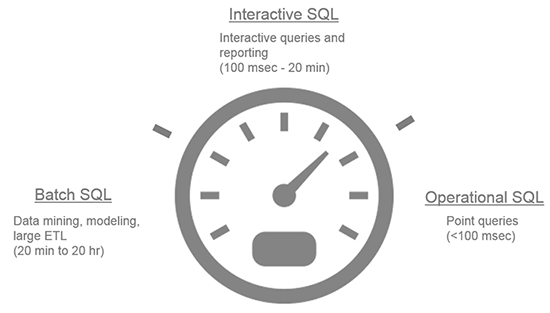
以下文章是转载自国外网站,介绍了Hadoop生态系统上面的几种SQL:Hive、Drill、Impala、Presto以及Spark\Shark等应用场景、对比以及一些结论Within the big data landscape there are multiple approaches to accessing, analyzing, and manipulating data in Hadoop. Each depends on key considerations such as latency, ANSI SQL completeness (and the ability to tolerate machine-generated SQL), developer and a w397090770 11年前 (2014-08-11) 9976℃ 0评论14喜欢
本文转载自:http://blog.cloudera.com/blog/2014/04/how-to-run-a-simple-apache-spark-app-in-cdh-5/(Editor’s note – this post has been updated to reflect CDH 5.1/Spark 1.0)Apache Spark is a general-purpose, cluster computing framework that, like MapReduce in Apache Hadoop, offers powerful abstractions for processing large datasets. For various reasons pertaining to performance, functionality, and APIs, Spark is already be w397090770 11年前 (2014-07-18) 20185℃ 3评论9喜欢
本博客分享的其他视频下载地址:《传智播客Hadoop实战视频下载地址[共14集]》、《传智播客Hadoop课程视频资料[共七天]》、《Hadoop入门视频分享[共44集]》、《Hadoop大数据零基础实战培训教程下载》、《Hadoop2.x 深入浅出企业级应用实战视频下载》、《Hadoop新手入门视频百度网盘下载[全十集]》 本博客收集到的Hadoop学习书 w397090770 11年前 (2014-07-15) 92456℃ 0评论164喜欢
写在前面的话,最近发现有很多网站转载我博客的文章,这个我都不介意的,但是这些网站转载我博客都将文章的出处去掉了,直接变成自己的文章了!!我强烈谴责他们,鄙视那些转载文章去掉出处的人!所以为了防止这些,我以后发表文章的时候,将会在文章里面加入一些回复之后才可见的内容!!请大家不要介意,本博 w397090770 11年前 (2014-05-13) 14150℃ 30评论3喜欢
我们在接触Hadoop的时候,第一个列子一般是运行Wordcount程序,在Spark我们可以用Java代码写一个Wordcount程序并部署在Yarn上运行。我们知道,在Spark源码中就存在一个用Java编写好的JavaWordCount程序,源码如下:[code lang="JAVA"]package org.apache.spark.examples;import org.apache.spark.api.java.JavaPairRDD;import org.apache.spark.api.java.JavaRDD;import org.apac w397090770 11年前 (2014-05-04) 28416℃ 1评论19喜欢
在本博客的《Spark 0.9.1 Standalone模式分布式部署》详细的介绍了如何部署Spark Standalone的分布式,在那篇文章中并没有介绍如何来如何来测试,今天我就来介绍如何用Java来编写简单的程序,并在Standalone模式下运行。 程序的名称为SimpleApp.java,通过调用Spark提供的API进行的,在程序编写前现在pom引入相应的jar依赖:[code lang="JA w397090770 11年前 (2014-04-24) 7661℃ 0评论2喜欢
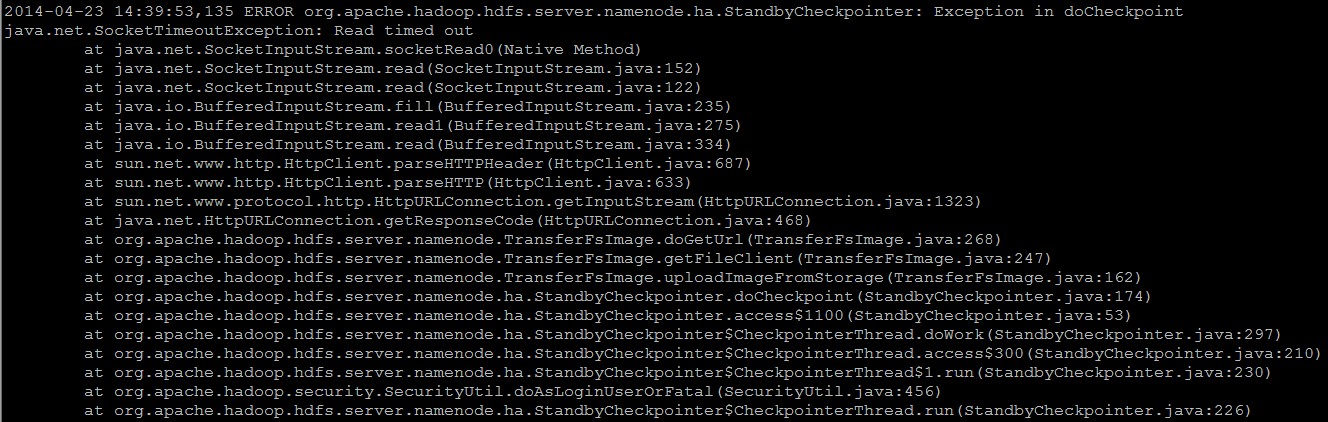
这几天观察了一下Standby NN上面的日志,发现每次Fsimage合并完之后,Standby NN通知Active NN来下载合并好的Fsimage的过程中会出现以下的异常信息:[code lang="JAVA"]2014-04-23 14:42:54,964 ERROR org.apache.hadoop.hdfs.server.namenode.ha. StandbyCheckpointer: Exception in doCheckpointjava.net.SocketTimeoutException: Read timed out at java.net.SocketInputStream.socketRead0( w397090770 11年前 (2014-04-23) 7813℃ 2评论8喜欢
1、内存不够[code lang="JAVA"][ERROR] PermGen space -> [Help 1][ERROR] [ERROR] To see the full stack trace of the errors,re-run Maven with the -e switch.[ERROR] Re-run Maven using the -X switch to enable full debug logging.[ERROR] [ERROR] For more information about the errors and possible solutions, please read the following articles:[ERROR] [Help 1]http://cwiki.apache.org/confluence/display/MAVEN/OutOfMemoryErr w397090770 11年前 (2014-04-16) 15519℃ 4评论9喜欢