这个月的4月7号,Apache Hadoop 2.4.0已经发布了,Hadoop 2.4.0是2014年第二个Hadoop发布版本(在2月20日发布了Apache Hadoop 2.3.0),他在HDFS上做了一些加强,比如对异构存储层次的支持和通过数据节点为存储在HDFS中的数据提供了内存缓存功能。在Hadoop2.4.0主要做了以下工作: (1)、HDFS支持访问控制列表(ACLs,Access Control Lists); w397090770 11年前 (2014-04-12) 8141℃ 0评论3喜欢
Avro有C, C++, C#, Java, PHP, Python, and Ruby等语言的实现,本文只简单介绍如何在Java中使用Avro进行数据的序列化(data serialization)。本文使用的是Avro 1.7.4,这是写这篇文章时最新版的Avro。读完本文,你将会学到如何使用Avro编译模式、如果用Avro序列化和反序列化数据。一、准备项目需要的jar包 文本的例子需要用到的Jar包有这四 w397090770 11年前 (2014-04-08) 45191℃ 4评论38喜欢
由于Hadoop自身的一些特点,它只适合用于将Linux作为操作系统的生产环境。在实际应用场景中,管理员适当对Linux内核参数进行调优,可在一定程度上提高作业的运行效率,比较有用的调整选项如下。一、增大同时打开的文件描述符和网络连接上限 在Hadoop集群中,由于涉及的作业和任务数目非常多,对于某个节点,由于 w397090770 11年前 (2014-04-02) 13157℃ 1评论7喜欢
io.file.buffer.size hadoop访问文件的IO操作都需要通过代码库。因此,在很多情况下,io.file.buffer.size都被用来设置缓存的大小。不论是对硬盘或者是网络操作来讲,较大的缓存都可以提供更高的数据传输,但这也就意味着更大的内存消耗和延迟。这个参数要设置为系统页面大小的倍数,以byte为单位,默认值是4KB,一般情况下,可以 w397090770 11年前 (2014-04-01) 30413℃ 2评论14喜欢
在 《Hadoop 2.2.0安装和配置lzo》 文章中介绍了如何基于 Hadoop 2.2.0安装lzo。里面简单介绍了如果在Hive里面使用lzo数据。今天主要来说说如何在Hadoop 2.2.0中使用lzo压缩文件当作的数据。 lzo压缩默认的是不支持切分的,也就是说,如果直接把lzo文件当作Mapreduce任务的输入,那么Mapreduce只会用一个Map来处理这个输入文件,这显然 w397090770 11年前 (2014-03-28) 20519℃ 7评论8喜欢
前提条件: 1、安装好jdk1.6或以上版本 2、部署好Hadoop 2.2.0(可以参见本博客《Hadoop2.2.0完全分布式集群平台安装与设置》) 3、安装好ant,这很简单:[code lang="JAVA"]$ wget http://mirrors.cnnic.cn/apache/ant/binaries/apache-ant-1.9.3-bin.tar.gz$ tar -zxvf apache-ant-1.9.3-bin.tar.gz[/code]然后设置好ANT_HOME和PATH就行 4、安装好相 w397090770 11年前 (2014-03-26) 23859℃ 1评论35喜欢
Hadoop经常用于处理大量的数据,如果期间的输出数据、中间数据能压缩存储,对系统的I/O性能会有提升。综合考虑压缩、解压速度、是否支持split,目前lzo是最好的选择。LZO(LZO是Lempel-Ziv-Oberhumer的缩写)是一种高压缩比和解压速度极快的编码,它的特点是解压缩速度非常快,无损压缩,压缩后的数据能准确还原,lzo是基于block w397090770 11年前 (2014-03-25) 17681℃ 4评论10喜欢
一、相关概念 在默认情况下,Hadoop相关的WEB页面(JobTracker, NameNode, TaskTrackers and DataNodes)是不需要什么权限验证就可以直接进入的,谁都可以查看到当前集群上有哪些作业在运行,这对安全来说是很不合理的。我们应该限定用户来访问Hadoop相关的WEB页面,只有授权的用户才能看到自己授权的作业等信息,而不应该看到他不 w397090770 11年前 (2014-03-25) 13008℃ 2评论8喜欢
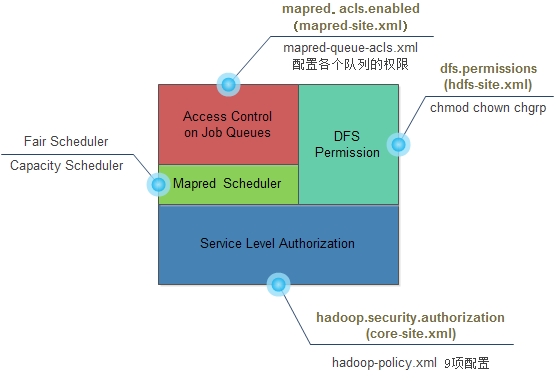
Hadoop在服务层进行了授权(Service Level Authorization)控制,这是一种机制可以保证客户和Hadoop特定的服务进行链接,比如说我们可以控制哪个用户/哪些组可以提交Mapreduce任务。所有的这些配置可以在$HADOOP_CONF_DIR/hadoop-policy.xml中进行配置。它是最基础的访问控制,优先于文件权限和mapred队列权限验证。可以看看下图[caption id="attach w397090770 11年前 (2014-03-20) 9170℃ 0评论8喜欢
前段时间,公司Hadoop集群整体的负载很高,查了一下原因,发现原来是客户端那边在每一个作业上擅自配置了很大的堆空间,从而导致集群负载很高。下面我就来讲讲怎么来现在客户端那边的JVM堆大小的设置。 我们知道,在mapred-site.xml配置文件里面有个mapred.child.java.opts配置,专门来配置一些诸如堆、垃圾回收之类的。看 w397090770 11年前 (2014-03-18) 19220℃ 0评论10喜欢