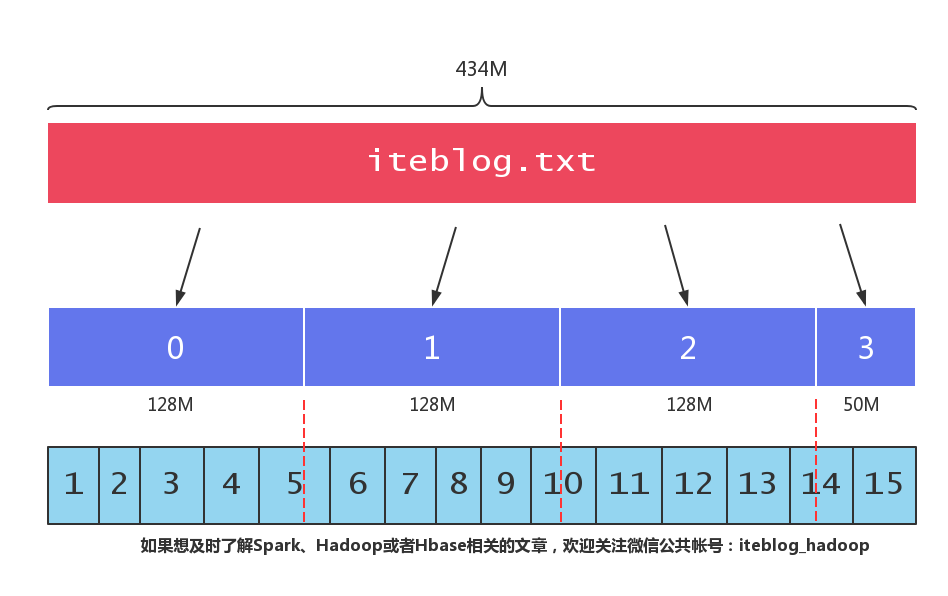
相信大家都知道,HDFS 将文件按照一定大小的块进行切割,(我们可以通过 dfs.blocksize 参数来设置 HDFS 块的大小,在 Hadoop 2.x 上,默认的块大小为 128MB。)也就是说,如果一个文件大小大于 128MB,那么这个文件会被切割成很多块,这些块分别存储在不同的机器上。当我们启动一个 MapReduce 作业去处理这些数据的时候,程序会计算出文 w397090770 7年前 (2018-05-16) 2711℃ 4评论28喜欢
4月6日,Apache Hadoop 3.1.0 正式发布了,Apache Hadoop 3.1.0 是2018年 Hadoop-3.x 系列的第一个小版本,并且带来了许多增强功能。不过需要注意的是,这个版本并不推荐在生产环境下使用,如果需要在正式环境下使用,请等待 3.1.1 或 3.1.2 版本。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop这个版 w397090770 7年前 (2018-04-08) 3617℃ 0评论15喜欢
在 HDFS 中,DataNode 将数据块存储到本地文件系统目录中,具体的目录可以通过配置 hdfs-site.xml 里面的 dfs.datanode.data.dir 参数。在典型的安装配置中,一般都会配置多个目录,并且把这些目录分别配置到不同的设备上,比如分别配置到不同的HDD(HDD的全称是Hard Disk Drive)和SSD(全称Solid State Drives,就是我们熟悉的固态硬盘)上。当 w397090770 7年前 (2018-03-28) 5378℃ 3评论24喜欢
我们每天都可能会操作 HDFS 上的文件,这就很难避免误操作,比如比较严重的误操作就是删除文件。本文针对这个问题提供了三种恢复误删除文件的方法,希望对大家的日常运维有所帮助。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop通过垃圾箱恢复HDFS 为我们提供了垃圾箱的功能, w397090770 7年前 (2018-01-14) 10244℃ 2评论23喜欢
今天凌晨 Apache Hadoop 3.0.0 GA 版本正式发布,这意味着我们就可以正式在线上使用 Hadoop 3.0.0 了!这个版本是 Apache Hadoop 3.0.0 的第一个稳定版本,有很多重大的改进,比如支持 EC、支持多于2个的NameNodes、Intra-datanode均衡器等等。下面是关于 Apache Hadoop 3.0.0 GA 的正式介绍。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微 w397090770 7年前 (2017-12-15) 3504℃ 1评论38喜欢
就在前几天,Apache Hadoop 3.0.0-beta1 正式发布了,这是3.0.0的第一个 beta 版本。本版本基于 3.0.0-alpha4 版本进行了Bug修复、性能提升以及其他一些加强。好消息是,这个版本之后会正式发行 Apache Hadoop 3.3.0 GA(General Availability,正式发布的版本)版本,这意味着我们就可以正式在线上使用 Hadoop 3.0.0 了!目前预计 Apache Hadoop 3.3.0 GA 将会在 201 w397090770 8年前 (2017-10-11) 2273℃ 0评论15喜欢
每个 NodeManager 节点内置提供了检测自身健康状态的机制(详情参见 NodeHealthCheckerService);通过这种机制,NodeManager 会将诊断出来的监控状态通过心跳机制汇报给 ResourceManager,然后ResourceManager 端会通过 RMNodeEventType.STATUS_UPDATE 更新 NodeManager 的状态;如果此时的 NodeManager 节点不健康,那么 ResourceManager 将会把 NodeManager 状态变为 NodeState w397090770 8年前 (2017-06-08) 4313℃ 0评论18喜欢
ResourceManager 内维护了 NodeManager 的生命周期;对于每个 NodeManager 在 ResourceManager 中都有一个 RMNode 与其对应;除了 RMNode ,ResourceManager 中还定义了 NodeManager 的状态(states)以及触发状态转移的事件(event)。具体如下:org.apache.hadoop.yarn.server.resourcemanager.rmnode.RMNode:这是一个接口,每个 NodeManager 都与 RMNode 对应,这个接口主要维 w397090770 8年前 (2017-06-07) 3658℃ 0评论21喜欢
Job execution logs and profiles are important when troubleshooting Hadoop errors, tuning job performance, and planning cluster capacity. In the past, the Job History Server has been the primary source for this information, providing logs of important events in MapReduce job execution and associated profiling metrics. With the advent of YARN, which enables execution frameworks beyond MapReduce, the responsibilities of the Job History Ser w397090770 8年前 (2017-06-02) 211℃ 0评论0喜欢
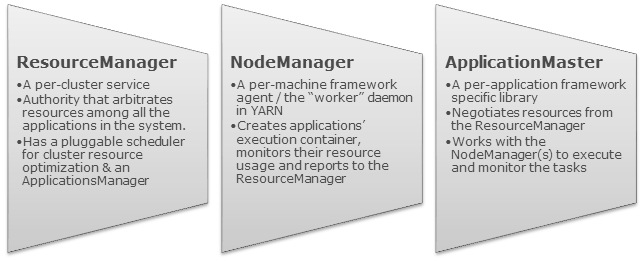
Apache YARN是将之前Hadoop 1.x的 JobTracker 功能分别拆到不同的组件里面了,每个组件分别负责不同的功能。在Hadoop 1.x中, JobTracker 负责管理集群的资源,作业调度以及作业监控;YARN把这些功能分别拆到ResourceManager 和 ApplicationMaster 中了。而之前的TaskTracker被NodeManager替代。下面分别介绍YAEN的各个组件的作用。如果想及时了解Spark、Had w397090770 8年前 (2017-06-01) 4082℃ 0评论31喜欢