Spark已经取代Hadoop成为最活跃的开源大数据项目。但是,在选择大数据框架时,企业不能因此就厚此薄彼。近日,著名大数据专家Bernard Marr在一篇文章(http://www.forbes.com/sites/bernardmarr/2015/06/22/spark-or-hadoop-which-is-the-best-big-data-framework/)中分析了Spark和Hadoop的异同。 Hadoop和Spark均是大数据框架,都提供了一些执行常见大数据任务 w397090770 10年前 (2015-12-01) 9584℃ 0评论31喜欢
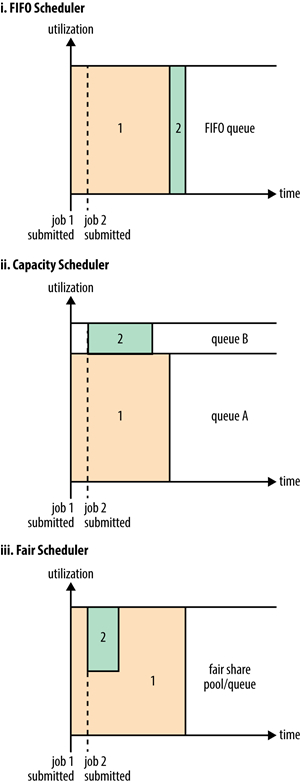
本文将介绍Hadoop YARN提供的三种任务调度策略:FIFO Scheduler,Capacity Scheduler 和 Fair Scheduler。FIFO Scheduler顾名思义,这就是先进先出(first in, first out)调度策略,所有的application将按照提交的顺序来执行,这些 application 都放在一个队列里,只有在执行完一个之后,才会继续执行下一个。这种调度策略很容易理解,但缺点也很明显 w397090770 10年前 (2015-11-29) 11795℃ 0评论31喜欢
新世纪以来,互联网及个人终端的普及,传统行业的信息化及物联网的发展等产业变化产生了大量的数据,远远超出了单台机器能够处理的范围,分布式存储与处理成为唯一的选项。从2005年开始,Hadoop从最初Nutch项目的一部分,逐步发展成为目前最流行的大数据处理平台。Hadoop生态圈的各个项目,围绕着大数据的存储,计算, w397090770 10年前 (2015-11-06) 7984℃ 0评论9喜欢
下面的大数据学习电子书我会陆续上传,敬请关注。一、Hadoop1、Hadoop Application Architectures2、Hadoop: The Definitive Guide, 4th Edition3、Hadoop Security Protecting Your Big Data Platform4、Field Guide to Hadoop An Introduction to Hadoop, Its Ecosystem, and Aligned Technologies5、Hadoop Operations A Guide for Developers and Administrators6、Hadoop Backup and Recovery Solutions w397090770 10年前 (2015-08-11) 20493℃ 2评论56喜欢
《Hadoop&Spark解决二次排序问题(Spark篇)》《Hadoop&Spark解决二次排序问题(Hadoop篇)》问题描述二次排序就是key之间有序,而且每个Key对应的value也是有序的;也就是对MapReduce的输出(KEY, Value(v1,v2,v3,......,vn))中的Value(v1,v2,v3,......,vn)值进行排序(升序或者降序),使得Value(s1,s2,s3,......,sn),si ∈ (v1,v2,v3,......,vn)且s1 < s2 < s3 < ..... w397090770 10年前 (2015-08-06) 11342℃ 6评论29喜欢
在MapReduce作业中的数据输入和输出必须使用到相关的InputFormat和OutputFormat类,来指定输入数据的格式,InputFormat类的功能是为map任务分割输入的数据。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop InputFormat类中必须指定Map输入参数Key和Value的数据类型,以及对输入的数据如何进行分 w397090770 10年前 (2015-07-11) 5552℃ 0评论14喜欢
Apache Hadoop 2.7.1于美国时间2015年07月06日正式发布,本版本属于稳定版本,是自Hadoop 2.6.0以来又一个稳定版,同时也是Hadoop 2.7.x版本线的第一个稳定版本,也是 2.7版本线的维护版本,变化不大,主要是修复了一些比较严重的Bug(其中修复了131个Bugs和patches)。比较重要的特性请参见《Hadoop 2.7.0发布:不适用于生产和不支持JDK1.6》 w397090770 10年前 (2015-07-08) 17912℃ 0评论23喜欢
[电子书]Hadoop权威指南第3版中文版PDF下载 本书英文名是:Hadoop:the Definitive Guide,4rd Edition,中文名:Hadoop权威指南,著名的O'Reilly Media出版社出版,这里提供下载的是2015年3月出版的最终版,电子书756页,9.6MB,非之前网上传的。 这里提供的是英文写作的,它的内容组织得当,思路清晰,紧密结合实际。但是要把它翻译成 w397090770 10年前 (2015-05-29) 41988℃ 7评论92喜欢
MapReduce和Spark比较 目前的大数据处理可以分为以下三个类型: 1、复杂的批量数据处理(batch data processing),通常的时间跨度在数十分钟到数小时之间; 2、基于历史数据的交互式查询(interactive query),通常的时间跨度在数十秒到数分钟之间; 3、基于实时数据流的数据处理(streaming data processing),通常的时间 w397090770 10年前 (2015-05-28) 4950℃ 0评论7喜欢
Apache Hadoop 2.7.0发布。一共修复了来自社区的535个JIRAs,其中:Hadoop Common有160个;HDFS有192个;YARN有148个;MapReduce有35个。Hadoop 2.7.0是2015年第一个Hadoop release版本,不过需要注意的是 (1)、不要将Hadoop 2.7.0用于生产环境,因为一些关键Bug还在测试中,如果需要在生产环境使用,需要等Hadoop 2.7.1/2.7.2,这些版本很快会发布。 w397090770 10年前 (2015-04-24) 8867℃ 0评论14喜欢


![Hadoop等大数据学习相关电子书[共85本]](https://www.iteblog.com/wp-content/themes/yusi2.0/img/pic/8.jpg)




