为什么要升级在2017年底, Hadoop3.0 发布了,到目前为止, Hadoop 发布的最新版本为3.2.1。在 Hadoop3 中有很多有用的新特性出现,如支持 ErasureCoding、多 NameNode、Standby NameNode read、DataNode Disk Balance、HDFS RBF 等等。除此之外,还有很多性能优化以及 BUG 修复。其中最吸引我们的就是 ErasureCoding 特性,数据可靠性保持不变的情况下可以降 w397090770 5年前 (2020-01-05) 2617℃ 0评论11喜欢
为了让大家更好地学习交流,过往记忆大数据花了一个周末的时间把 Awesome Big Data 里近 600 个大数据相关的调度、存储、计算、数据库以及可视化等介绍全部翻译了一遍,供大家学习交流。关系型数据库管理系统MySQL 世界上最流行的开源数据库。PostgreSQL 世界上最先进的开源数据库。Oracle Database - 对象关系数据库管理系统。T w397090770 6年前 (2019-09-23) 12571℃ 0评论34喜欢
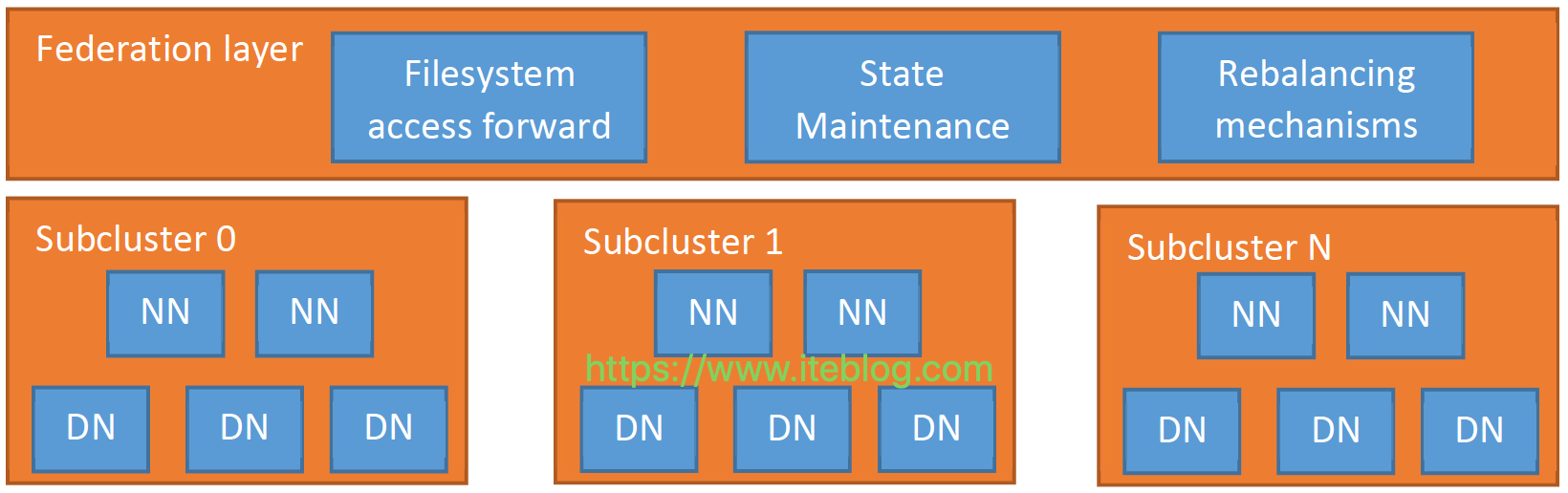
在 《Apache Hadoop 的 HDFS federation 前世今生(上)》 已经介绍了 Hadoop 2.9.0 版本之前 HDFS federation 存在的问题,那么为了解决这个问题,社区采取了什么措施呢?HDFS Router-based FederationViewFs 方案虽然可以很好的解决文件命名空间问题,但是它的实现有以下几个问题:ViewFS 是基于客户端实现的,需要用户在客户端进行相关的配置,那 w397090770 6年前 (2019-07-26) 2072℃ 0评论2喜欢
背景熟悉大数据的人应该都知道,HDFS 是一个分布式文件系统,它是基于谷歌的 GFS 思路实现的开源系统,它的设计目的就是提供一个高度容错性和高吞吐量的海量数据存储解决方案。在经典的 HDFS 架构中有2个 NameNode 和多个 DataNode 的,如下:如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop从 w397090770 6年前 (2019-07-25) 2270℃ 0评论3喜欢
HDFS 快照是从 Hadoop 2.1.0-beta 版本开始引入的新功能,详见 HDFS-2802。概述HDFS 快照(HDFS Snapshots)是文件系统在某个时间点的只读副本。可以在文件系统的子树或整个文件系统上创建快照。快照的常见用途主要包括数据备份,防止用户误操作和容灾恢复。HDFS 快照的实现非常高效:快照的创建非常迅速:除去 inode 的查找时间, w397090770 6年前 (2018-12-02) 2182℃ 0评论3喜欢
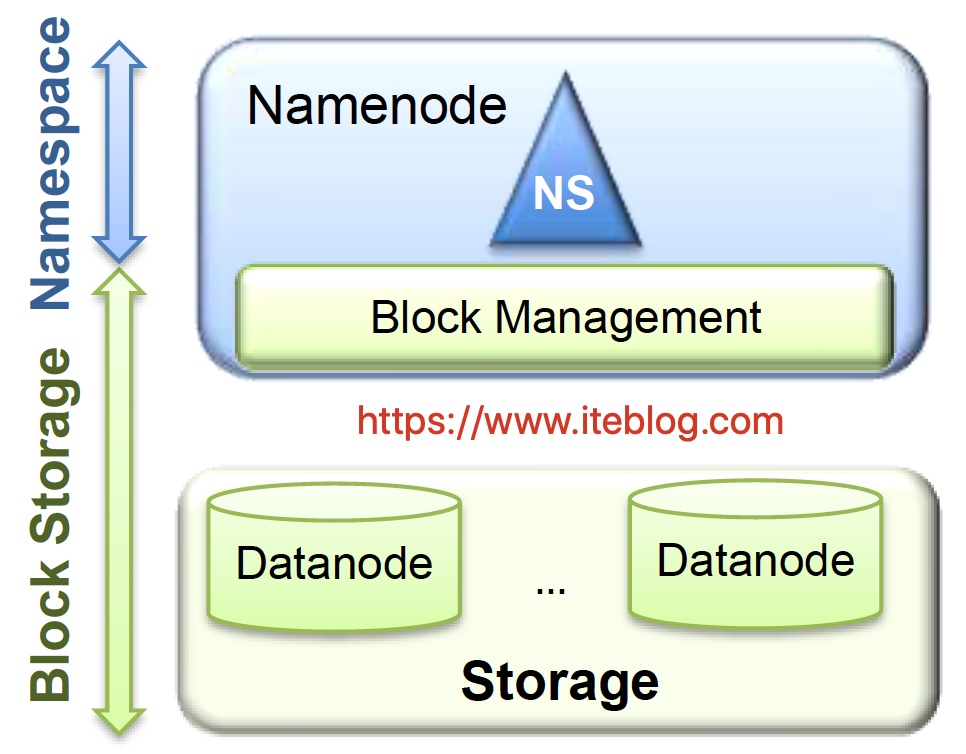
我们知道,HDFS 被设计成存储大规模的数据集,我们可以在 HDFS 上存储 TB 甚至 PB 级别的海量数据。而这些数据的元数据(比如文件由哪些块组成、这些块分别存储在哪些节点上)全部都是由 NameNode 节点维护,为了达到高效的访问, NameNode 在启动的时候会将这些元数据全部加载到内存中。而 HDFS 中的每一个文件、目录以及文件块, w397090770 7年前 (2018-10-09) 9423℃ 2评论31喜欢
在 《HDFS 块和 Input Splits 的区别与联系》 文章中介绍了HDFS 块和 Input Splits 的区别与联系,其中并没有涉及到源码级别的描述。为了补充这部分,这篇文章将列出相关的源码进行说明。看源码可能会比直接看文字容易理解,毕竟代码说明一切。为了简便起见,这里只描述 TextInputFormat 部分的读取逻辑,关于写 HDFS 块相关的代码请参 w397090770 7年前 (2018-05-16) 2398℃ 0评论19喜欢
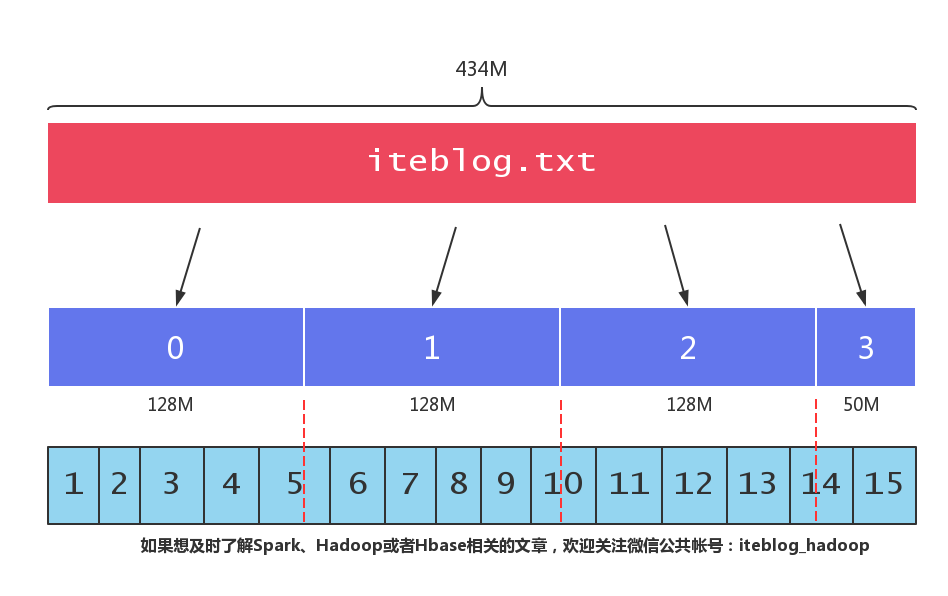
相信大家都知道,HDFS 将文件按照一定大小的块进行切割,(我们可以通过 dfs.blocksize 参数来设置 HDFS 块的大小,在 Hadoop 2.x 上,默认的块大小为 128MB。)也就是说,如果一个文件大小大于 128MB,那么这个文件会被切割成很多块,这些块分别存储在不同的机器上。当我们启动一个 MapReduce 作业去处理这些数据的时候,程序会计算出文 w397090770 7年前 (2018-05-16) 2707℃ 4评论28喜欢
在 HDFS 中,DataNode 将数据块存储到本地文件系统目录中,具体的目录可以通过配置 hdfs-site.xml 里面的 dfs.datanode.data.dir 参数。在典型的安装配置中,一般都会配置多个目录,并且把这些目录分别配置到不同的设备上,比如分别配置到不同的HDD(HDD的全称是Hard Disk Drive)和SSD(全称Solid State Drives,就是我们熟悉的固态硬盘)上。当 w397090770 7年前 (2018-03-28) 5375℃ 3评论24喜欢
HDFS Federation为HDFS系统提供了NameNode横向扩容能力。然而作为一个已实现多年的解决方案,真正应用到已运行多年的大规模集群时依然存在不少的限制和问题。本文以实际应用场景出发,介绍了HDFS Federation在美团点评的实际应用经验。 背景 2015年10月,经过一段时间的优化与改进,美团点评HDFS集群稳定性和性能有显著 zz~~ 8年前 (2017-03-17) 2062℃ 0评论7喜欢