我们在使用HDFS Shell的时候只用最频繁的命令可能就是 ls 了,其具体含义我就不介绍了。在使用 ls 的命令时,我们可能想对展示出来的文件按照修改时间排序,也就是最近修改的文件(most recent)显示在最前面。如果你使用的是Hadoop 2.8.0以下版本,内置是不支持按照时间等属性排序的。不过值得高兴的是,我们可以结合Shell命令来 w397090770 8年前 (2017-02-18) 12651℃ 0评论9喜欢
在HDFS中,DataNode 将数据块存储到本地文件系统目录中,具体的目录可以通过配置 hdfs-site.xml 里面的 dfs.datanode.data.dir 参数。在典型的安装配置中,一般都会配置多个目录,并且把这些目录分别配置到不同的设备上,比如分别配置到不同的HDD(HDD的全称是Hard Disk Drive)和SSD(全称Solid State Drives,就是我们熟悉的固态硬盘)上。 w397090770 8年前 (2016-12-13) 5937℃ 0评论13喜欢
随着大数据技术的发展,HDFS作为Hadoop的核心模块之一得到了广泛的应用。为了系统的可靠性,HDFS通过复制来实现这种机制。但在HDFS中每一份数据都有两个副本,这也使得存储利用率仅为1/3,每TB数据都需要占用3TB的存储空间。随着数据量的增长,复制的代价也变得越来越明显:传统的3份复制相当于增加了200%的存储开销,给存 w397090770 9年前 (2016-05-30) 9376℃ 0评论36喜欢
在Linux文件系统中,我们可以使用下面的Shell脚本判断某个文件是否存在:[code lang="bash"]# 这里的-f参数判断$file是否存在 if [ ! -f "$file" ]; then echo "文件不存在!"fi [/code]但是我们想判断HDFS上某个文件是否存在咋办呢?别急,Hadoop内置提供了判断某个文件是否存在的命令:[code lang="bash"][iteblog@www.it w397090770 9年前 (2016-03-21) 10825℃ 0评论19喜欢
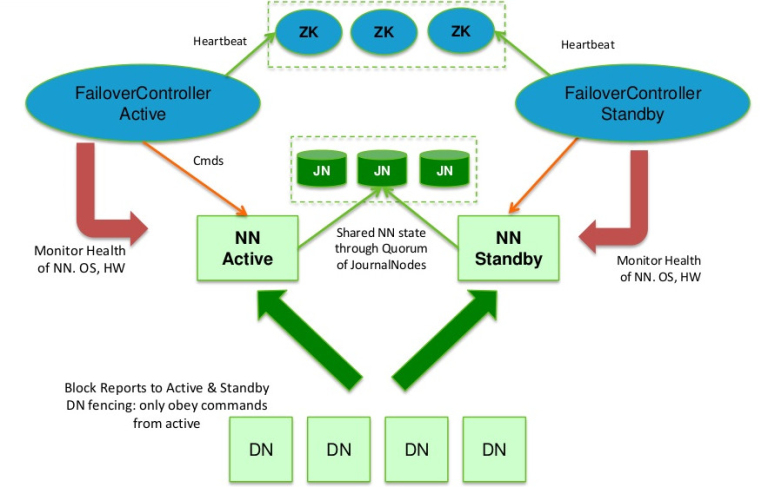
在Hadoop2.0.0之前,NameNode(NN)在HDFS集群中存在单点故障(single point of failure),每一个集群中存在一个NameNode,如果NN所在的机器出现了故障,那么将导致整个集群无法利用,直到NN重启或者在另一台主机上启动NN守护线程。 主要在两方面影响了HDFS的可用性: (1)、在不可预测的情况下,如果NN所在的机器崩溃了,整个 w397090770 12年前 (2013-11-14) 10709℃ 3评论22喜欢