最近发现离线任务对一个增量Hive表的查询越来越慢,这引起了我的注意,我在cmd窗口手动执行count操作查询发现,速度确实很慢,才不到五千万的数据,居然需要300s,这显然是有问题的,我推测可能是有小文件。我去hdfs目录查看了一下该目录:发现确实有很多小文件,有480个小文件,我觉得我找到了问题所在,那么合并一 zz~~ 3年前 (2021-08-20) 1249℃ 0评论4喜欢
2010年,Facebook 的工程师在 ICDC(IEEE International Conference on Data Engineering) 发表了一篇 《RCFile: A Fast and Space-efficient Data Placement Structure in MapReduce-based Warehouse Systems》 的论文,介绍了其为基于 MapReduce 的数据仓库设计的高效存储结构,这就是我们熟知的 RCFile(Record Columnar File)。下面介绍 RCFile 的一些诞生背景和设计。背景早在2010 w397090770 5年前 (2020-06-16) 1363℃ 0评论8喜欢
OpenCSVSerde 使用大家使用 Hive 分析数据的时候,CSV 格式的数据应该是很常见的,所以从 0.14.0 开始(参见 HIVE-7777) Hive 跟我们提供了原生的 OpenCSVSerde 来解析 CSV 格式的数据。从名字可以看出,OpenCSVSerde 是基于 Open-CSV 2.3 类库实现的,其解析 csv 的功能还是很强大的。为了在 Hive 中使用这个 serde,我们需要在建表的时候指定 row form w397090770 5年前 (2020-05-04) 1902℃ 0评论4喜欢
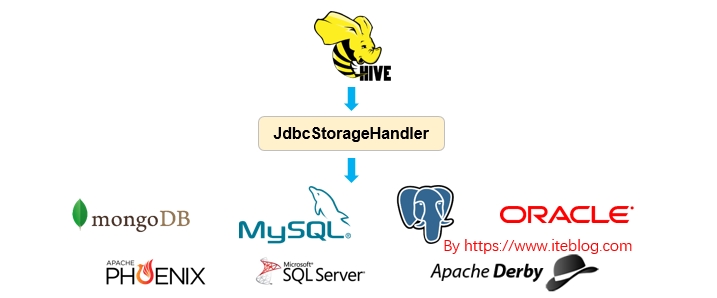
Apache Hive 从 HIVE-1555 开始引入了 JdbcStorageHandler ,这个使得 Hive 能够读取 JDBC 数据源,关于 Apache Hive 引入 JdbcStorageHandler 的背景可以参见 《Apache Hive 联邦查询(Query Federation)》。本文主要简单介绍 JdbcStorageHandler 的使用。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop语法JdbcStorageHandler 使 w397090770 6年前 (2019-04-01) 3455℃ 0评论9喜欢
有赞数据平台从2017年上半年开始,逐步使用 SparkSQL 替代 Hive 执行离线任务,目前 SparkSQL 每天的运行作业数量5000个,占离线作业数目的55%,消耗的 cpu 资源占集群总资源的50%左右。本文介绍由 SparkSQL 替换 Hive 过程中碰到的问题以及处理经验和优化建议,包括以下方面的内容:有赞数据平台的整体架构。SparkSQL 在有赞的技术演进 w397090770 6年前 (2019-03-20) 8287℃ 5评论29喜欢
如今,很多公司可能会在内部使用多种数据存储和处理系统。这些不同的系统解决了对应的使用案例。除了传统的 RDBMS (比如 Oracle DB,Teradata或PostgreSQL) 之外,我们还会使用 Apache Kafka 来获取流和事件数据。使用 Apache Druid 处理实时系列数据(real-time series data),使用 Apache Phoenix 进行快速索引查找。 此外,我们还可能使用云存储 w397090770 6年前 (2019-03-16) 5228℃ 1评论8喜欢
本文所列的 Hive 函数均为 Hive 内置的,共计294个,Hive 版本为 3.1.0。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop!! a - Logical not,和not逻辑操作符含义一致[code lang="sql"]hive> select !(true);OKfalse[/code]!=a != b - Returns TRUE if a is not equal to b,和操作符含义一致[code lang="sql"]hive> se w397090770 7年前 (2018-07-22) 9733℃ 0评论10喜欢
问题我们都知道,Hive 内部提供了大量的内置函数用于处理各种类型的需求,参见官方文档:Hive Operators and User-Defined Functions (UDFs)。我们从这些内置的 UDF 可以看到两个用于解析 Json 的函数:get_json_object 和 json_tuple。用过这两个函数的同学肯定知道,其职能解析最普通的 Json 字符串,如下:[code lang="sql"]hive (default)> SELECT get_js w397090770 7年前 (2018-07-04) 20220℃ 0评论34喜欢
在 《使用Python编写Hive UDF》 文章中,我简单的谈到了如何使用 Python 编写 Hive UDF 解决实际的问题。我们那个例子里面仅仅是一个很简单的示例,里面仅仅引入了 Python 的 sys 包,而这个包是 Python 内置的,所有我们不需要担心 Hadoop 集群中的 Python 没有这个包;但是问题来了,如果我们现在需要使用到 numpy 中的一些函数呢?假设我们 w397090770 7年前 (2018-01-25) 6571℃ 3评论23喜欢
Hive 内置为我们提供了大量的常用函数用于日常的分析,但是总有些情况这些函数还是无法满足我们的需求;值得高兴的是,Hive 允许用户自定义一些函数,用于扩展 HiveQL 的功能,这类函数叫做 UDF(用户自定义函数)。使用 Java 编写 UDF 是最常见的方法,但是本文介绍的是如何使用 Python 来编写 Hive 的 UDF 函数。如果想及时了解S w397090770 7年前 (2018-01-24) 14550℃ 0评论27喜欢