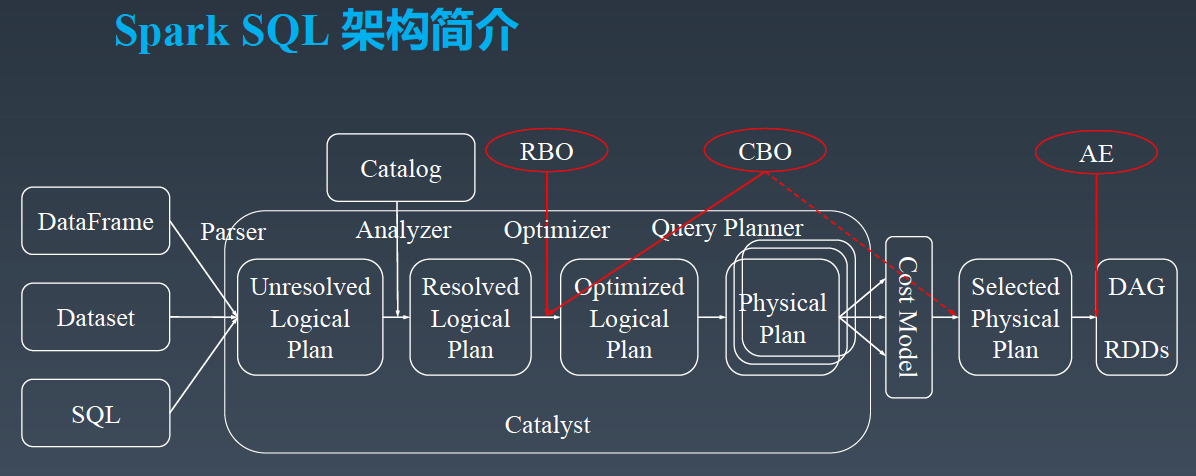
以下是字节跳动数据仓库架构负责人郭俊的分享主题沉淀,《字节跳动在Spark SQL上的核心优化实践》。PPT 请微信关注过往记忆大数据,并回复 bd_sparksql 获取。今天的分享分为三个部分,第一个部分是 SparkSQL 的架构简介,第二部分介绍字节跳动在 SparkSQL 引擎上的优化实践,第三部分是字节跳动在 Spark Shuffle 稳定性提升和性能 w397090770 5年前 (2019-12-03) 4386℃ 0评论3喜欢
本文已经不再更新,谢谢支持。本页面长期更新最新 Google、谷歌学术、维基百科、ccFox.info、ProjectH、3DM、Battle.NET 、WordPress、Microsoft Live、GitHub、Box.com、SoundCloud、inoreader、Feedly、FlipBoard、Twitter、Facebook、Flickr、imgur、DuckDuckGo、Ixquick、Google Services、Google apis、Android、Youtube、Google Drive、UpLoad、Appspot、Googl eusercontent、Gstatic、Google othe w397090770 5年前 (2019-11-19) 1448℃ 0评论3喜欢
大家肯定都知道要想在国内下载一个项目到本地速度太慢了。可以试试下面方案,把原地址:https://github.com/xxx.git 替换为:https://github.com.cnpmjs.org/xxx.git 即可。比如我们要克隆下面项目到本地,可以操作如下:[code lang="bash"][root@iteblog.com ~]$ git clone https://github.com.cnpmjs.org/397090770/web正克隆到 'web'...Username for 'https://github.com.cnpmjs.org w397090770 6年前 (2019-06-14) 1000℃ 0评论1喜欢
Flink Forward 是由 Apache 官方授权,Apache Flink China社区支持,有来自阿里巴巴,Ververica(Apache Flink 商业母公司)、腾讯、Google、Airbnb以及 Uber 等公司参加的国际型会议。旨在汇集大数据领域一流人才共同探讨新一代大数据计算引擎技术。通过参会不仅可以了解到Flink社区的最新动态和发展计划,还可以了解到国内外一线大厂围绕Flink生 w397090770 6年前 (2019-04-20) 3500℃ 0评论11喜欢
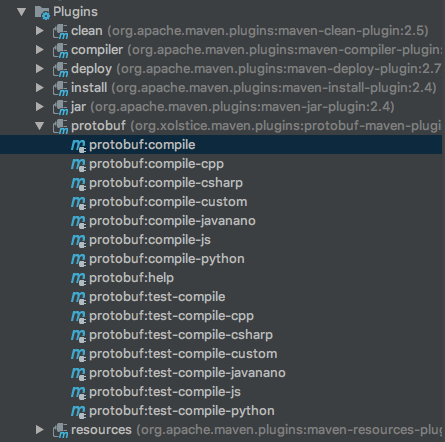
Google Protocol Buffer( 简称 Protobuf) 是 Google 公司内部的混合语言数据标准,目前已经正在使用的有超过 48,162 种报文格式定义和超过 12,183 个 .proto 文件。他们用于 RPC 系统和持续数据存储系统。Protocol Buffers 是一种序列化数据结构的方法。对于通过管线(pipeline)或存储数据进行通信的程序开发上是很有用的。这个方法包含一个接口描述 w397090770 6年前 (2019-02-01) 6944℃ 0评论8喜欢
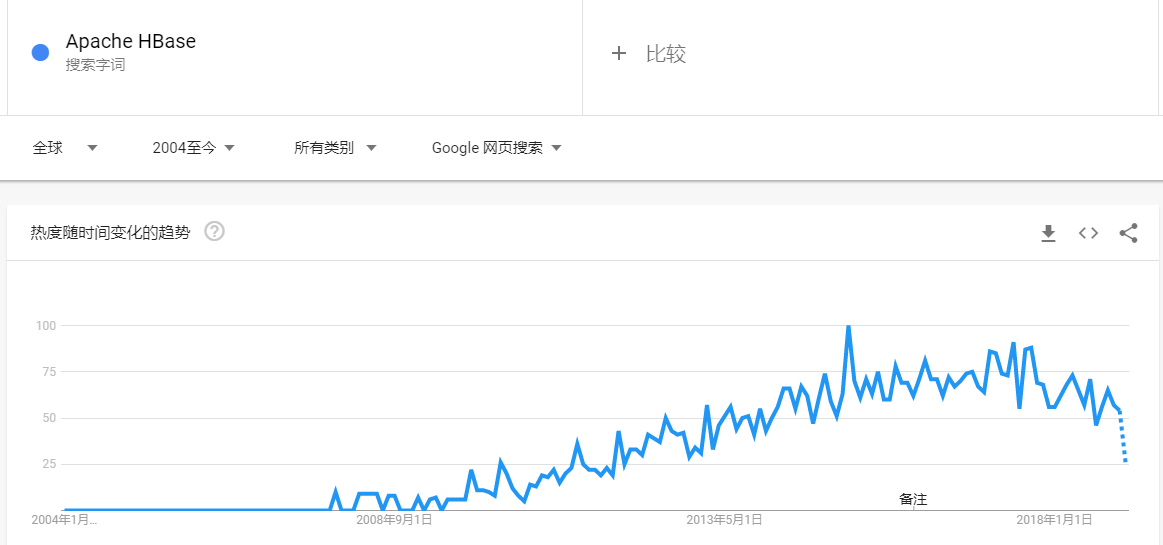
Apache HBase是基于Hadoop构建的一个分布式的、可伸缩的海量数据存储系统。随着时间的推移,HBase目前不管是在国内还是国外都受到了非常大的欢迎,以下分别是近几年 Google 和百度关于 HBase 的搜索趋势:Google如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop大家可以看到,整体趋势是越来越 w397090770 6年前 (2019-01-05) 3587℃ 4评论15喜欢
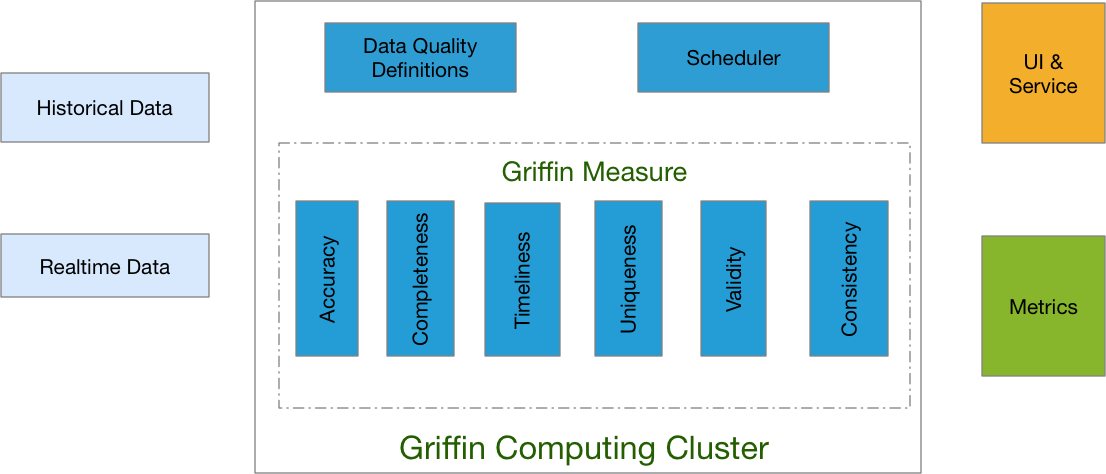
Apache Griffin 是开源的大数据数据质量解决方案,支持批处理和流模式,其是基于 Apache Hadoop 和 Apache Spark 构建,由 eBay 开发,并于 2016年12月07日进入 Apache 孵化。Griffin 提供了一个可以处理不同的任务,如定义数据质量模型,执行数据质量测量,自动化数据分析和验证,以及跨多个数据系统的统一数据质量可视化的全面的框架,旨在 w397090770 6年前 (2019-01-03) 9407℃ 3评论9喜欢
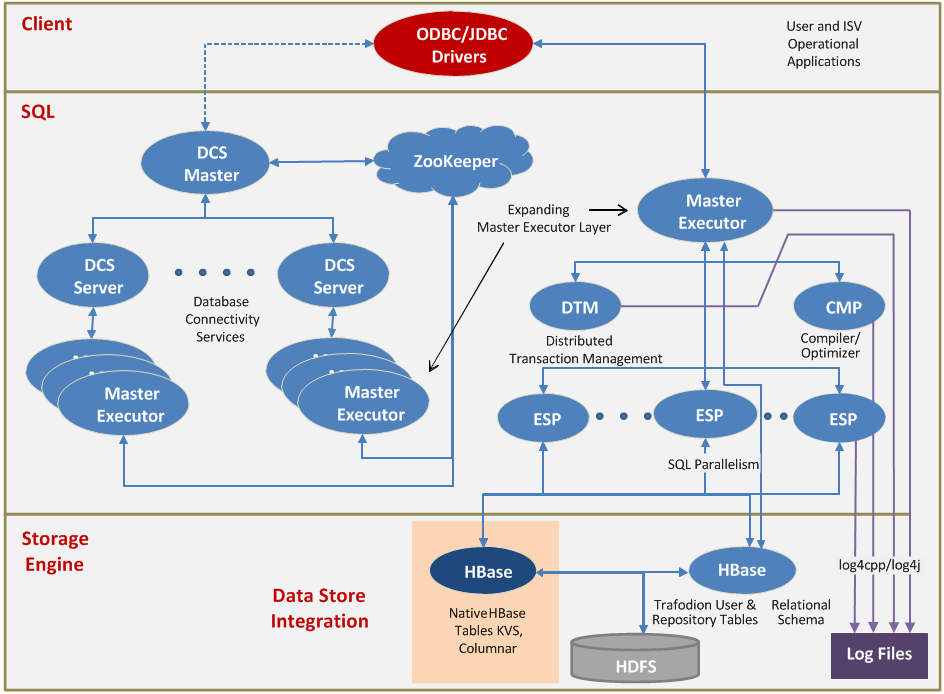
去年,我整理了2017年成功晋升为Apache TLP的大数据相关项目进行了整理,具体可以参见《盘点2017年晋升为Apache TLP的大数据相关项目》。现在已经进入了2019年了,我在这里给大家整理了2018年成功晋升为 Apache TLP 的大数据相关项目。2018年晋升成 TLP 的项目不多,总共四个,按照项目晋升的时间进行排序的。Apache Trafodion:基于 Hadoop 平 w397090770 6年前 (2019-01-02) 1664℃ 0评论4喜欢
Flink Forward 是由 Apache 官方授权,Apache Flink China社区支持,有来自阿里巴巴,dataArtisans(Apache Flink 商业母公司),华为、腾讯、滴滴、美团以及字节跳动等公司参加的国际型会议。旨在汇集大数据领域一流人才共同探讨新一代大数据计算引擎技术。通过参会不仅可以了解到Flink社区的最新动态和发展计划,还可以了解到国内外一线大 w397090770 6年前 (2018-12-22) 4072℃ 0评论17喜欢
Alluxio Meetup 上海站由 Alluxio、七牛主办,示说网、过往记忆协办,本次会议将于2018年10月27日 13:30-17:00 在上海市张江高科博霞路66号浦东软件园Q座举行。报名地址扫描下面二维码:如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop活动详情Alluxio:未来是数据的时代,数据的高效管理、存储 w397090770 7年前 (2018-10-17) 1320℃ 0评论1喜欢